Разграничение доступа на основе атрибутов (Attribute-Based Access Control, ABAC) — модель контроля доступа к объектам, основанная на анализе правил для атрибутов объектов или субъектов, возможных операций с ними и окружения, соответствующего запросу. Системы управления доступом на основе атрибутов обеспечивают мандатное и избирательное управление доступом. Рассматриваемый вид разграничения доступа дает возможность создать огромное количество комбинаций условий...
Agile

Agile – набор методов и практик для гибкого управления проектами в разных прикладных областях, от разработки ПО до реализации маркетинговых стратегий, с целью повышения скорости создания готовых продуктов и минимизации рисков за счет итерационного выполнения, интерактивного взаимодействия членов команды и быстрой реакцией на изменения. История зарождения Agile Изначально термин Agile...
AirFlow
Apache AirFlow - это open-source инструмент, который позволяет разрабатывать, планировать и осуществлять мониторинг сложных рабочих процессов. Главной особенностью является то, что для описания процессов используется язык программирования Python. Airflow используется как планировщик ETL/ELT-процессов. Основные сущности рабочего процесса на Apache Airflow: Направленные ациклические графы (DAG) Планировщик (Scheduler) Операторы (Operators) Задачи (Tasks)...
Apache Hbase

Hbase - это нереляционная распределенная система управления базами данных (СУБД) с открытым исходным кодом, написанная на языке Java. Hbase является проектом экосистемы Hadoop и работает поверх распределенной файловой системы HDFS (Hadoop Distributed File System) [1].
Apache Hive

Hive – это система управления базами данных (СУБД) в рамках платформы Hadoop для хранения и обработки больших данных в распределенной среде. Хайв позволяет проектировать структуры Big Data (таблицы, партиции, бакеты) с помощью SQL-подобного языка, называемого HiveQL.
Arenadata

Группа Arenadata — ведущий российский разработчик ПО и лидер по количеству коммерческих внедрений на рынке систем управления и обработки данных. Группа представлена во всех ключевых нишах рынка и занимает лидирующие позиции в большинстве продуктовых категорий. Эксперты Arenadata вносят существенный вклад в развитие глобальных Open Source проектов. Arenadata среди мирового сообщества...
AVRO

Avro – это линейно-ориентированный (строчный) формат хранения файлов Big Data, активно применяемый в экосистеме Apache Hadoop и широко используемый в качестве платформы сериализации. Как устроен формат Avro для файлов Big Data: структура и принцип работы Avro сохраняет схему в независимом от реализации текстовом формате JSON (JavaScript Object Notation), что облегчает...
Big Data
Big Data (Большие данные) Big Data - данные большого объема, высокой скорости накопления или изменения и/или разновариантные информационные активы, которые требуют экономически эффективных, инновационных формы обработки данных, которые позволяют получить расширенное понимание информации, способствующее принятию решений и автоматизации процессов. Для каждой организации или компании существует предел объема данных (Volume) которые...
CAP
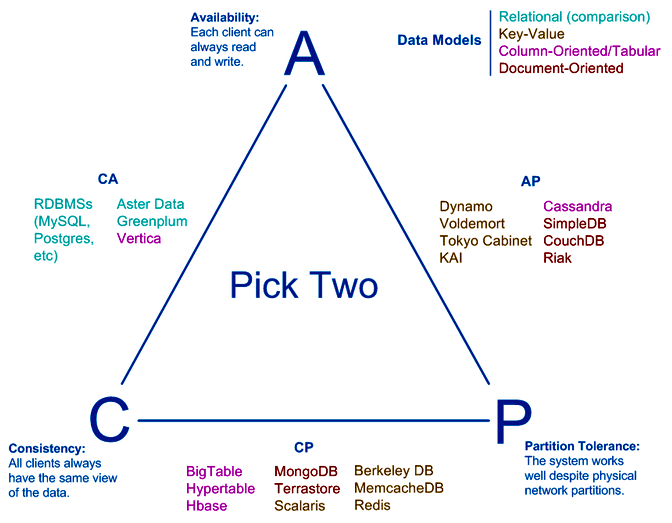
CAP – это акроним от англоязычных слов Consistency (Согласованность, Целостность), Availability (Доступность) и Partition tolerance (Устойчивость к разделению). Согласно утверждению профессора Калифорнийского университета в Беркли, Эрика Брюера, сделанному в 2000-м году, в распределенных системах осуществимы лишь 2 свойства из указанных 3-х. В частности, считается что нереляционные базы данных жертвуют согласованностью данных в...
Case Based Reasoning (CBR)
Case Based Reasoning (CBR) - метод решения проблем рассуждением по аналогии, путем предположения на основе подобных случаев (прецедентов). Это способ решения проблем на основе уже известных решений, который широко применяется во всех областях деятельности. Например, в бизнес-анализе такое сопоставление с эталоном, целенаправленный поиск и внедрение лучших практик со стороны называется...
Cassandra

Apache Cassandra – это нереляционная отказоустойчивая распределенная СУБД, рассчитанная на создание высокомасштабируемых и надёжных хранилищ огромных массивов данных, представленных в виде хэша. Проект был разработан на языке Java в корпорации Facebook в 2008 году, и передан фонду Apache Software Foundation в 2009 [1]. Эта СУБД относится к гибридным NoSQL-решениям, поскольку она...
Churn Rate
Churn Rate (уровень оттока клиентов) - индикатор, показывающий процент пользователей, которые перестали пользоваться приложением (сервисом) или перестали быть вашим клиентом в течение рассматриваемого периода. Для уменьшения оттока клиентов используют таргетированные маркетинговые кампании для удержания клиентов с помощью персональных бонусов, скидок и предложения. Для успешной компании уровень оттока клиентов (Churn Rate) должен...
ClickHouse

ClickHouse – колоночная реляционная СУБД с открытым исходным кодом от компании Яндекс для быстрой обработки аналитических SQL-запросов на структурированных больших данных (Big Data) в режиме реального времени.
Cloudera

Cloudera CDH (Cloudera’s Distribution including Apache Hadoop) — дистрибутив Apache Hadoop с набором программ, библиотек и утилит, разработанных компанией Cloudera для больших данных (Big Data) и машинного обучения (Machine Learning), бесплатно распространяемый и коммерчески поддерживаемый для некоторых Linux-систем (Red Hat, CentOS, Ubuntu, SuSE SLES, Debian) [1]. Состав и архитектура Клаудера...
CRISP-DM
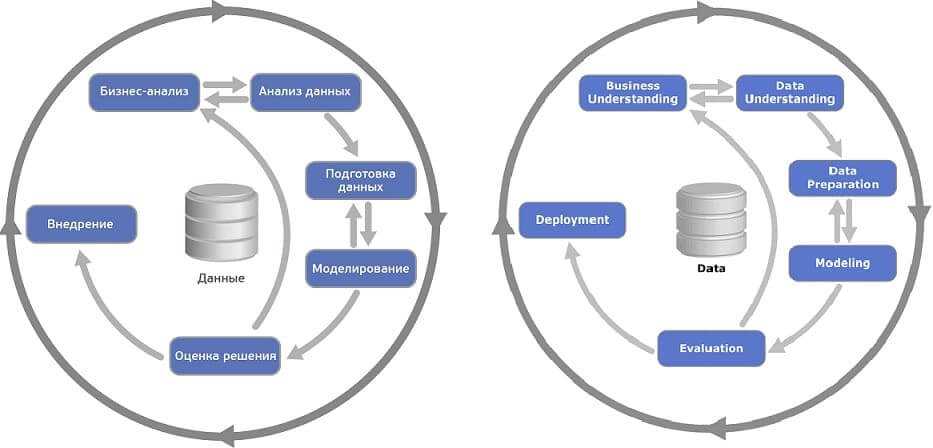
CRISP-DM (от английского Cross-Industry Standard Process for Data Mining) — межотраслевой стандартный процесс исследования данных. Это проверенная в промышленности и наиболее распространённая методология, первая версия которой была представлена в Брюсселе в марте 1999 года, а пошаговая инструкция опубликована в 2000 году [1]. CRISP-DM описывает жизненный цикл исследования данных, состоящий из...
Data Lake
Data Lake (Озеро данных) - это метод хранения данных системой или репозиторием в натуральном (RAW) формате, который предполагает одновременное хранение данных в различных схемах и форматах. Обычно используется blob-объект (binary large object) или файл. Идея озера данных в том чтобы иметь логически определенное, единое хранилище всех данных в организации (enterprise data)...
Data Mining
Data Mining - процесс поиска в сырых необработанных данных интересных, неизвестных, нетривиальных взаимосвязей и полезных знаний, позволяющих интерпретировать и применять результаты для принятия решений в любых сферах человеческой деятельности. Представляет собой совокупность методов визуализации, классификации, моделирования и прогнозирования, основанные на применении деревьев решений, искусственных нейронных сетей, генетических алгоритмов, эволюционного программирования, ассоциативной памяти, нечёткой логики. Дополнительно о...
data provenance
data provenance - происхождение данных
Data Science
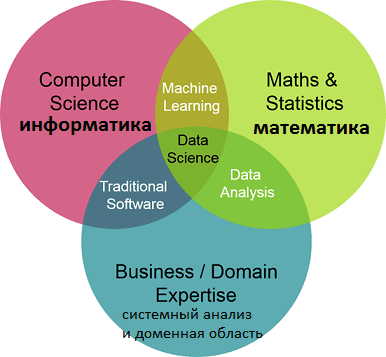
Data Science – это наука о данных, объединяющая разные области знаний: информатику, математику и системный анализ. Сюда входят методы обработки больших данных (Big Data), интеллектуального анализа данных (Data Mining), статистические методы, методы искусственного интеллекта, в т.ч машинное обучение (Machine Learning). DS включает методы проектирования и разработки баз данных и прикладного...
Dataflow

Dataflow, или поток данных, представляет собой концепцию, важную для понимания того, как данные перемещаются и обрабатываются в программном коде. Эта концепция играет ключевую роль в различных областях программирования, включая параллельное программирование, асинхронное выполнение и обработку событий. В программировании поток данных представляет собой направление перемещения данных от одного участка кода к...