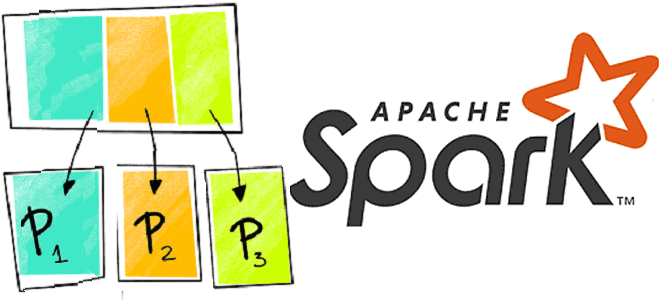
Чтобы сделать обучение разработчиков Apache Spark, дата-аналитиков и инженеров Big Data еще более наглядным, сегодня рассмотрим проблему JOIN-соединений при неравномерном распределении данных по узлам кластера и способы ее решения. Читайте далее, как избавиться от перекосов и ускорить выполнение SQL-запросов в Spark-приложениях. Перекосы данных в Apache Spark: что это и чем...