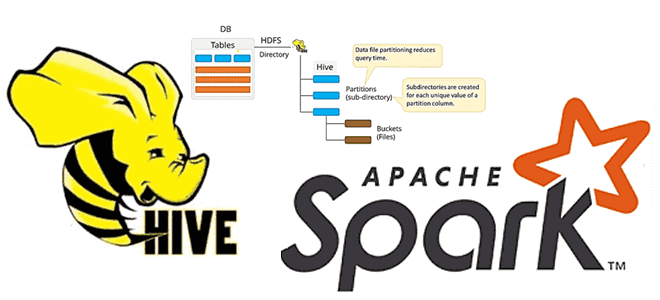
Недавно мы писали про обновление хранилища метаданных Apache Hive с помощью команды MSCK REPAIR TABLE, операторов AirFlow и Spark-заданий. В продолжение этой темы про работу с партиционированными Parquet-файлами сегодня рассмотрим применение Spark SQL для этого случая, чтобы использовать таблицу Hive вместо временного представления Spark. Временные таблицы Hive/Spark и разделы в Parquet-файлах...