
Школа Больших Данных продолжает серию митапов по Apache Spark. Третий митап состоится 24 мая в 17:00 МСК по теме «Spark или pandas? Spark и pandas!». Apache Spark – это Big Data фреймворк с открытым исходным кодом для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных, входящий в экосистему проектов...
3 режима вывода в Apache Spark Structured Streaming
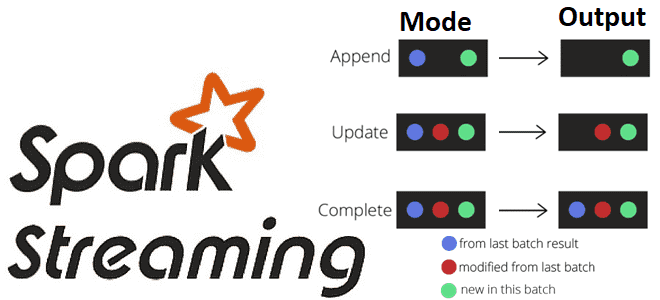
Какие бывают режимы вывода в структурированной потоковой передаче Spark, чем они отличаются и как их использовать на практике: разбираемся на практическом примере. Краткий ликбез по output modes в Apache Spark Structured Streaming для обучения дата-инженеров и разработчиков распределенных приложений. Что такое режимы вывода в Apache Spark Structured Streaming Apache Spark...