
8 апреля 2024 года вышел очередной релиз Apache AirFlow. Знакомимся с ключевыми новинками выпуска 2.9: от функций работы с наборами данных до настроек внешнего объектного хранилища в качестве бэкенда XCom-объектов и особенностей поддержки Python 3.12. Наборы данных и гибкое планирование DAG Airflow Выпуск 2.9 содержит более 35 интересных новых функций,...
Проектирование raw-слоя DWH для последующего преобразования в Data Vault
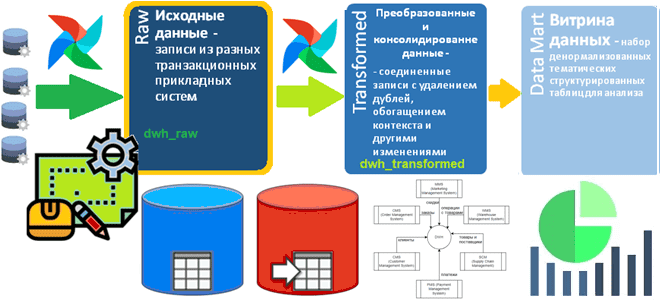
Как определить структуру Raw-слоя корпоративного хранилища данных: пример проектирования и DDL-скрипт для кейса электронной коммерции, выбор компонентов решения для архитектуры данных. Постановка задачи: анализ систем-источников Сегодня корпоративные хранилища данных (DWH, Data Warehouse) обычно реализуются в виде нескольких баз данных, связанных ETL-процессами. Причем каждая из этих гомогенных или гетерогенных, т.е. на...
Состояние гонки в ETL-конвейерах: как дата-инженеру избежать коллизий данных

Что такое гонка данных, почему она опасна в ETL-заданиях и как ее избежать: зачем разделять задания репликации в RAW-слой хранилища от их преобразования и сохранения в Transformed-слое DWH перед созданием витрин данных для BI-приложений. Что такое гонка данных в дата-инженерии Одна из главных особенностей распределенных систем – это задержка между...
Тестирование доступности веб-сайта с помощью http-хуков Apache AirFlow
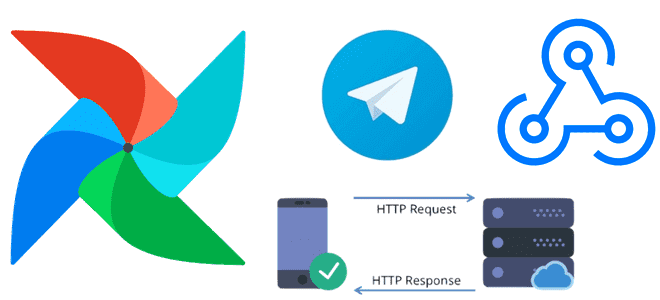
Сегодня я покажу, как проверить доступность веб-сайта с помощью http-хука в Apache AirFlow и отправить результаты проверки в Телеграм-бот. Еще раз про хуки и соединения Apache AirFlow Доступность системы является ключевым свойством информационной безопасности. Проверить, что веб-сервис доступен, можно по статусу HTTP-ответа на GET-запрос. Чтобы делать такую проверку периодически, т.е....
Как создать и запустить docker-контейнер Apache AirFlow на Windows

Что такое WSL, Docker и как запустить веб-сервер Apache AirFlow в контейнере на локальной машине в Ubuntu поверх Windows вместо любимого Google Colab. Пошаговое руководство для начинающих дата-инженеров. Краткий ликбез по WSL и Docker для любителей Windows Обычно я всегда запускала веб-сервер Apache AirFlow в интерактивной среде Google Colab, которая...
Как сменить SQLLite на PostgreSQL для бэкенда Apache AirFlow
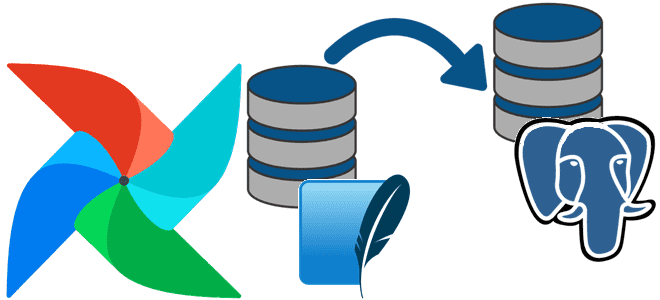
Зачем менять базу данных метаданных в производственном развертывании Apache AirFlow и как это сделать: пошаговое руководство для дата-инженера с примерами и рекомендациями. 5 шагов перехода от SQLLite к PostgreSQL: миграция базы данных метаданных Apache AirFlow Чтобы планировать и запускать конвейеры обработки данных, Apache AirFlow хранит сведения о задачах, DAG, исполнителях,...
Аутентификация и авторизация пользователей в Apache AirFlow

Зачем ограничивать доступ к папке с DAG и как это сделать: категории и роли пользователей в Apache AirFlow, способы входа в систему и конфигурации для настройки прав. Категории и роли пользователей Apache AirFlow Поскольку основным источником угрозы почти для любой информационной системы являются люди, при разработке методов обеспечения безопасности надо,...
5 советов начинающему дата-инженеру по AirFlow: личный опыт

Как спроектировать DAG и выбрать способ обмена данными между задачами, где определить подключения и запросы к БД и что поможет избежать ада Python-зависимостей при использовании Apache AirFlow. Сегодня я расскажу своем личном опыте наступания на грабли при работе с этим оркестратором batch-процессов и уроках, которые из этого вынесла. 5 советов...
Управление зависимостями: 5 подходов к проектированию конвейеров обработки данных
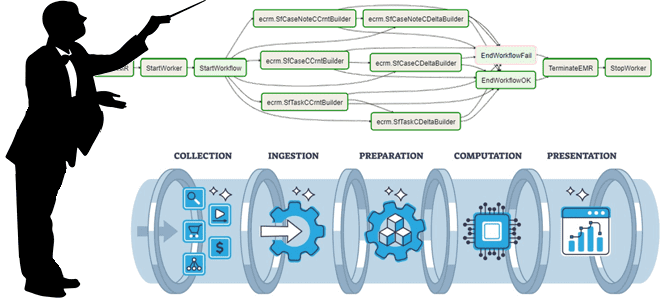
Как организовать упрощенное и продвинутое управление зависимостями между разными ETL-конвейерами, когда нужна централизованная оркестрация рабочих процессов и чем хороша стандартизация активов данных, отчетов и вычислительных процедур. Лучшие практики проектирования конвейеров для дата-инженера. Проектирование дата-конвейеров с минимальными зависимостями Для многих компаний, выстроивших процессы обработки данных в виде конвейеров, актуальна проблема управления...
Apache AirFlow 2.8: обзор предновогоднего релиза

14 декабря 2023 года вышел очередной релиз Apache AirFlow, который содержит более 20 новых фичей, 60 улучшений и 50 исправлений. Знакомимся с самыми главными для дата-инженера новинками выпуска 2.8. ТОП-10 новинок Apache AirFlow 2.8 Многие обновления в версии 2.8 направлены на расширение возможностей создания DAG, улучшение ведения журналов и исправление...