
Мы уже рассказали, что такое нормализация данных и зачем она нужна при подготовке выборки (Data Preparation) к машинному обучению (Machine Learning) и интеллектуальному анализу данных (Data Mining). Сегодня поговорим о том, как выполняется нормализация данных: читайте в нашем материале о методах и средствах преобразования признаков (Feature Transmormation) на этапе их генерации (Feature Engineering).
Нормализация данных: методы и формулы
Существует множество способов нормализации значений признаков, чтобы масштабировать их к единому диапазону и использовать в различных моделях машинного обучения. В зависимости от используемой функции, их можно разделить на 2 большие группы: линейные и нелинейные. При нелинейной нормализации в расчетных соотношениях используются функции логистической сигмоиды или гиперболического тангенса. В линейной нормализации изменение переменных осуществляется пропорционально, по линейному закону.
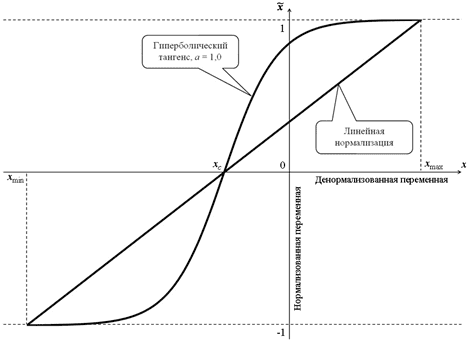
На практике наиболее распространены следующие методы нормализации признаков [1]:
- Минимакс — линейное преобразование данных в диапазоне [0..1], где минимальное и максимальное масштабируемые значения соответствуют 0 и 1 соответственно;
- Z-масштабирование данных на основе среднего значения и стандартного отклонения: деление разницы между переменной и средним значением на стандартное отклонение;
- десятичное масштабирование путем удаления десятичного разделителя значения переменной.
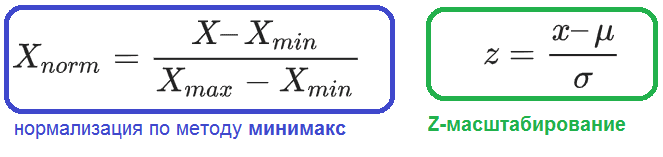
На практике минимакс и Z-масштабирование имеют похожие области применимости и часто взаимозаменяемы. Однако, при вычислении расстояний между точками или векторами в большинстве случае используется Z-масштабирование. А минимакс полезен для визуализации, например, чтобы перенести признаки, кодирующие цвет пикселя, в диапазон [0..255] [2].
Как нормализовать данные для машинного обучения и Data Mining
Чтобы выполнить нормализацию данных, нужно точно знать пределы изменения значений признаков: минимальное и максимальное теоретически возможные значения. Этим показателям будут соответствовать границы интервала нормализации. Когда точно установить пределы изменения переменных невозможно, они задаются с учетом минимальных и максимальных значений в имеющейся выборке данных [3].
На практике data scientist нормализует данные с помощью уже готовых функций интегрированных сред для статистического анализа, например, IBM SPSS, SAS или специальных библиотек: Scikit-learn, Auto-sklearn, pandas и т.д. Кроме того, аналитик данных может написать собственный код на языке R или Python для почти любой операции Data Preparation [4].

Подробно о том, как нормализовать данные и другие аспекты Data Preparation в нашем новом образовательном курсе для аналитиков Big Data в Москве: подготовка данных для Data Mining. Присоединяйтесь!
Источники

