Недавно мы рассказывали про Airflow Kubernetes Executor, который позволяет выполнять задачи DAG-графа Эйрфлоу в среде Kubernetes, развертывая Docker-контейнер на отдельном пользовательском модуле (pod). Сегодня рассмотрим, какие еще есть исполнители задач в Apache Airflow, как они используются при автоматизации batch-процессов обработки больших данных и с какими проблемами можно столкнуться при их практическом использовании.
Что такое Executor в AirFlow: немного об исполнителях задач
Напомним, в Airflow задача соответствует узлу DAG-графа, который выполняет какое-либо действие, например, запустить команду оболочки bash, python-скрипт, задание Apache Spark и пр. Перед выполнением задача сначала планируется и помещается в очередь, отсортированную по порядку добавления. Характер выполнения задачи зависит от используемого Executor’а.
Как мы уже отметили выше, KubernetesExecutor – это один из возможных видов исполнителей задач в Airflow. Помимо него, также существуют следующие исполнители [1]:
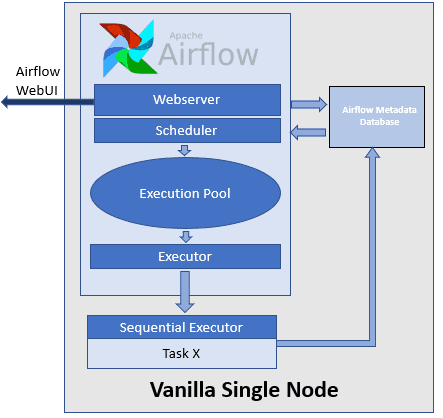
- SequentialExecutor, установленный по умолчанию в airflow.cfg у параметра executor – наиболее простой вид обработчика (worker), который работает только с одной задачей в каждый момент времени, не позволяя запускать одновременно несколько параллельных задач. Обычно этот вид исполнителя на практике используется редко, применяясь, в основном, для отладки и тестирования.
- LocalExecutor, который может выполнять задачи параллельно, запуская несколько DAG’ов одновременно путём порождения дочерних процессов. Однако, исполнитель этого типа ограничен ресурсами узла, на котором он запущен и, в случае его сбоя, запущенные задачи перестают выполняться до момента возвращения машины в работу. Тем не менее, при небольшом количестве задач, LocalExecutor можно использовать на практике, поскольку это сравнительно просто, быстро и не требует настройки дополнительных сервисов.
- CeleryExecutor, реализованный на базе Celery – библиотеки на языке Python для управления распределённой очередью заданий. Этот исполнитель легко масштабировать благодаря тому, что любой обработчик (worker), развернутый на новом узле кластера готов выполнять требуемую работу. Так повышается отказоустойчивость, поскольку при сбое любого worker’а его работа будет передана любому другому из работающих. Для использования CeleryExecutor необходима дополнительная настройка брокера сообщений, например, резидентная NoSQL-СУБД Redis или RabbitMQ. Подробнее о том, что такое брокер сообщений RabbitMQ и чем он отличается от Apache Kafka, мы рассказывали здесь.
- DaskExecutor на базе Dask – библиотеки параллельных вычислений на языке Python, которая может масштабироваться на кластер из 100 узлов, поддерживая методы машинного обучения с помощью технологий NumPy/Pandas/Lists, а также цепочки задач в виде DAG-графов [2]. Как и Celery, Dask самостоятельно не поддерживает очереди. Поэтому, если задача Airflow была создана с очередью, об этом будет выдано предупреждение, а сама задача будет отправлена в кластер [3]. Подробнее о том, что такое Dask, читайте в нашей новой статье.
Исполнители могут влиять на производительность кластера, поэтому их надо учитывать при настройке параметров для масштабирования, о чем мы рассказываем здесь.
Data Pipeline на Apache Airflow
Код курса
AIRF
Ближайшая дата курса
22 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
2 проблемы с исполнителями и способы их решения
После определения цепочки задач в виде DAG-графа, последовательность их выполнения можно представить следующим образом [4]:
- СУБД с метаданными, например, PostgreSQL, хранит записи обо всех задачах DAG-графа и их статусе (в очереди, запланировано, выполняется, успешно выполнено, не выполнено и пр);
- планировщик (Sheduler) читает метаданные из этой СУБД, чтобы проверить состояние каждой задачи и решить, что и в каком порядке нужно сделать;
- планировщик передает информацию исполнителю, чтобы тот выделил ресурсы для фактического выполнения задач по мере их постановки в очередь.
Планировщик запускает экземпляр исполнителя, указанного в конфигурационном файле airflow.cfg. Разница между исполнителями сводится к ресурсам, которые у них есть, и к тому, как они будут использовать эти ресурсы для распределения работ. В частности, при работе с LocalExecutor задачи будут выполняться как локальные подпроцессы; в других случаях – задачи выполняются удаленно, на разных рабочих узлах (worker’ах) [5]. При этом на практике возникают некоторые проблемы с типовыми исполнителями.
В частности, для всех DAG-графов предполагается только один конкретный executor из-за того, что на одном рабочем узле запускается лишь один исполнитель. В конфигурационном файле это задается следующим образом [6]:
# The executor class that airflow should use. Choices include# SequentialExecutor, LocalExecutor, CeleryExecutorexecutor = LocalExecutor
Однако, на практике иногда необходимо, чтобы разные DAG’и выполнялись по-разному. Обойти это ограничение можно с помощью подграфа DAG (SubDAG), передав ему исполнителя с помощью оператора (SubDagOperator) [6]:
bar_subdag = SubDagOperator(
task_id='bar',
subdag=my_subdag('foo', 'bar', default_args),
default_args=default_args,
dag=foo_dag,
executor=SequentialExecutor()
)
Data Pipeline на Apache Airflow
Код курса
AIRF
Ближайшая дата курса
22 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Если же задачи одного DAG-графа не всегда могут быть запланированы на одной машине, то, при разделении их по разным worker’ам, необходимо сохранение состояния задания и его совместное использование. Например, требуется локально выполнить обработку какого-либо файла с использованием BashOperator или PythonOperator. Однако, LocalExecutor выполняет задачу на том же узле, где запущен планировщик. А CeleryExecutor ставит задачи в очередь для обработки с помощью Celery-библиотеки. Обойти такое ограничение можно с помощью общего сетевого хранилища на всех машинах, где работают исполнители. Благодаря этому планировщик и веб-сервер могут совместно использовать папку с DAG-файлами и работать на разных компьютерах [7]. Читайте в нашей новой статье о гибридном исполнителе CeleryKubernetes Executor, который позволяет пользователям одновременно использовать CeleryExecutor и KubernetesExecutor для запуска конкретной задачи из очереди задач.
Data Pipeline на Apache Airflow
Код курса
AIRF
Ближайшая дата курса
22 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Другую специфику практической работы с Airflow для эффективного управления batch-процессами обработки больших данных вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- https://khashtamov.com/ru/apache-airflow-introduction/
- https://docs.dask.org/en/latest/
- https://airflow.apache.org/docs/stable/executor/dask.html
- https://www.astronomer.io/guides/airflow-executors-explained/
- https://airflow.apache.org/docs/stable/scheduler.html
- https://stackoverflow.com/questions/38750172/possible-to-set-different-executor-for-each-airflow-dag
- https://issue.life/questions/48755948

