
Чтобы обучение Airflow было максимально приближенным к практике, сегодня мы поговорим про особенности реального внедрения этого фреймворка для разработки, планирования и мониторинга пакетных процессов обработки больших данных (Big Data) с учетом современного DevOps-подхода. Читайте в нашей статье, зачем вообще нужна связка Apache Эйрфлоу с Kubernetes и как это реализовать технически.
Что общего между AirFlow и Kubernetes и при чем здесь DevOps
Напомним, Kubernetes – это программное обеспечение для автоматизации развёртывания, масштабирования и управления контейнеризированными приложениями. В области Big Data эта платформа управления контейнерами позволяет параллельно запускать множество задач, распределённых по тысячам приложений (микросервисов), расположенных на различных кластерах: публичном облаке, собственном датацентре, клиентских серверах и т.д. Сегодня Kubernetes считается профессиональным стандартом де-факто для каждого DevOps-инженера, обеспечивая непрерывную интеграцию, развертывание и поставку программного обеспечения.
Data Pipeline на Apache Airflow
Код курса
AIRF
Ближайшая дата курса
22 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
В свою очередь, Airflow тоже поддерживает DevOps-подход по управлению конфигурацией как кодом. В частности, этот фреймворк позволяет пользователям создавать многоступенчатые конвейеры данных (data pipeline) в виде DAG-диаграмм (Directed Acyclic Graph, направленный ациклический граф) с помощью веб-GUI и программного кода на языке Python. Простота и удобство пользования, а также прочие достоинства этого фреймворка обусловливают широкий круг его пользователей. Чтобы разработчики Data Flow, Data Scientist’ы, аналитики и инженеры данных могли работать с ним независимо друг от друга и без опасений кому-то помешать, можно упаковать Airflow в Docker-контейнер, который будет развернут отдельно для каждого пользователя [1]. Например, именно так поступили DevOps-специалисты онлайн-кинотеатра IVI, чтобы сэкономить ресурсы и не заводить для тестировщиков выделенного стенда рабочего окружения [2].
Таким образом, каждый пользователь может запускать произвольные модули и конфигурации Kubernetes и полностью управлять своими средами выполнения, ресурсами и данными, превращая эйрфлоу в универсального оркестровщика своих рабочих процессов [1].
Как работать с эйрфлоу на кубернетес
Можно выделить следующие сценарии использования связки Airflow и Kubernetes (K8s) [3]:
- запуск самого эйрфлоу в кластере K8s;
- использование этого фреймворка для запуска задач (jobs) в кластере K8s.
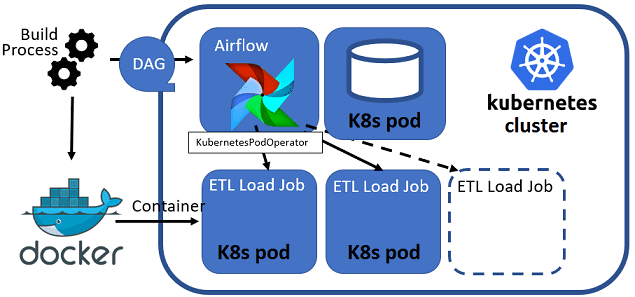
Обычно для запуска эйрфлоу в кластере Kubernetes используют надежный docker-образ puckel/docker-airflow, который собирается автоматически и содержит entrypoint-скрипт. Он нужен, чтобы контейнер мог работать в роли планировщика, веб-сервера или обработчика (воркера) задач и т.д. Также можно самостоятельно создать нужный docker-образ для своего production-окружения [3].
Чтобы запустить собственный data pipeline на эйрфлоу, развернутом в кластере Kubernetes, можно добавить DAG-файлы в docker-образ во время его сборки. Однако, при любом изменении цепочки задач, т.е. DAG’а, придется собирать этот образ заново. Вместо этого можно хранить DAG-файлы на внешнем томе, монтируя его в соответствующие поды (планировщик, веб-сервер, обработчик эйрфлоу) при запуске. Но более оптимальным считается использовать отдельный контейнер git-sync в поде (pod) кубернетес для периодической синхронизации DAG-файлов с указанным git-репозиторием без перезапуска самого Airflow [3].
Data Pipeline на Apache AirFlow и Arenadata Hadoop
Код курса
ADH-AIR
Ближайшая дата курса
по запросу
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Напомним, что DAG, смысловое объединение нескольких задач, которые нужно выполнить в строго определенной последовательности по определенному расписанию, состоит из набора операторов. Именно оператор описывает, какие экземпляры заданий нужно создать и что конкретно будет происходить во время выполнения каждого из них. Существует множество готовых операторов. Также, благодаря открытому API на языке Python, можно разработать собственные [3].
Для работы с эйрфлоу в кластере Kubernetes есть 2 готовых оператора — Airflow Kubernetes Operator:
- от компании Google, альфа-версия которого представлена на GitHub с января 2019 года, однако пока не является официальным продуктом корпорации [4];
- от самой платформы K8s, доступный с 2018 года [1].
Оба этих оператора Airflow позволят разработчику Data Flow, Data Scientist’у, аналитику и инженеру данных упаковывать, тестировать и развертывать каждое ETL-задание изолированно с помощью Docker и Kubernetes [5]. В следующей статье мы рассмотрим, как это работает.
Другие примеры практического использования Apache AirFlow для автоматизации процессов работы с большими данными вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- https://kubernetes.io/blog/2018/06/28/airflow-on-kubernetes-part-1-a-different-kind-of-operator/
- https://habr.com/ru/company/ivi/blog/456630/
- https://ealebed.github.io/posts/2020/развертывание-apache-airflow-в-kubernetes/
- https://github.com/GoogleCloudPlatform/airflow-operator
- https://medium.com/twodigits/master-devops-data-architecture-with-apache-airflow-kubernetes-and-talend-60368e63e14f

