Продолжая разговор про Apache Kafka Streams, сегодня мы расскажем, как API этой мощной библиотеки упрощает жизнь DevOps-инженеру и разработчику Big Data систем. Читайте в нашей статье, как Kafka Streams API эффективно обрабатывать большие данные из топиков Кафка на лету без использования Apache Spark, а также быстро создавать и развертывать распределенные приложения с привычными DevOps-инструментами без дополнительных кластеров.
Что такое Apache Kafka Streams API
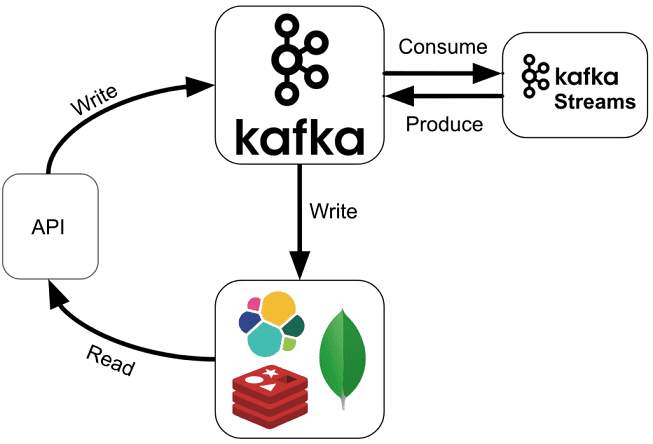
Apache Kafka Streams API – это интерфейс программирования, который позволяет распределенным приложениям в режиме реального времени обрабатывать данные, хранящиеся в Кафка, реализуя стандартные классы этой платформы потоковой обработки без развертывания отдельных кластеров. Благодаря этому инструменту можно организовать потоковую обработку данных прямо внутри кластера Кафка, без привлечения дополнительных технологий, таких как, например, Apache Spark или Storm. В частности, разделы топиков (topic partition) станут становится потоками (stream partition) для параллельной обработки [1]. Таким образом, Кафка Стримс API полностью скрывает сложность обслуживания отправителей (producer) и потребителей (consumer) сообщений топиков (topic) Кафка, позволяя сосредоточиться на логике обработки информационных потоков [2].
API Streams Apache Kafka, доступный через библиотеку Java, основан на следующих важных концепциях потоковой обработки [3]:
- управление состоянием приложения;
- быстрые и эффективные агрегации и объединения;
- различие между временем события и временем его обработки;
- непрерывная обработка данных, поступающих с опозданием и помехами.
Зачем Кафка Стримс API нужен DevOps-инженеру
API Kafka Streams помогает вывести обработку информационных потоков из мира Big Data за счет упрощения процессов разработки и развертывания. Программы, создаваемые с помощью Кафка Стримс API – это обычные приложения Java, которые можно упаковать, развернуть и контролировать без отдельных кластеров и специализированной инфраструктуры.
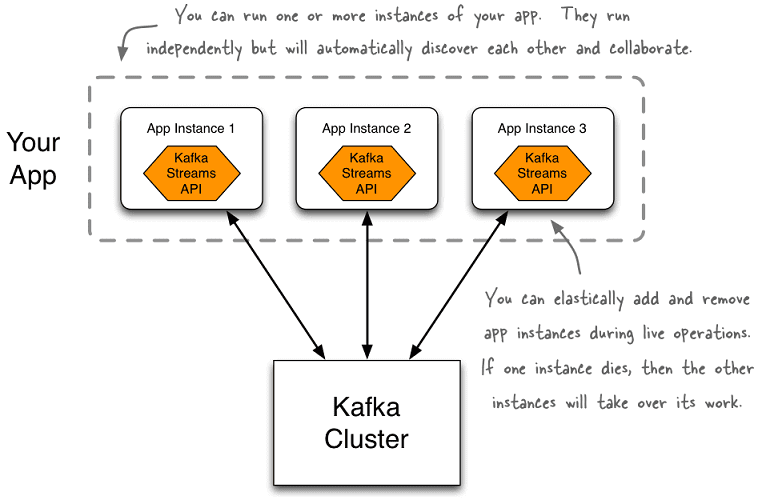
Разработанное таким образом приложение можно запустить в одном или нескольких экземплярах на клиентских компьютерах по периметру кластера Kafka – в случае распараллеливания программы автоматически найдут друг друга и будут обрабатывать данные совместно. При этом гарантируется высокая отказоустойчивость: даже если на одном из экземпляров возникнет сбой, остальные автоматически возьмут на себя его работу без потери данных.
Что особенно важно для быстрого и эффективного развертывания, API Kafka Streams реализует девиз «Создавайте приложения, а не инфраструктуру!», используя любую DevOps-технологию (Puppet, Chef, Ansible, Docker, Mesos, YARN, Kubernetes и пр.). Такой интегрированный подход резко контрастирует с другими инструментами потоковой обработки, которые требуют установки и эксплуатации отдельных кластеров обработки и аналогичной тяжеловесной инфраструктуры со своим собственным набором специальных правил использования и взаимодействия [3]. Подробнее о главных достоинствах API-интерфейса Кафка Стримс читайте в нашей новой статье.
Примеры использования API Kafka Streams в реальных проектах Big Data
На практике Кафка Стримс API применяется в широком наборе отраслей и вариантов использования (use cases). Отметим наиболее типичные сценарии разработки с этой технологией [3]:
- приложения для туристических компаний и travel-агрегаторов, чтобы в режиме онлайн искать наиболее подходящие для клиентов предложения, обеспечивать cross-продажи дополнительных услуг и обрабатывать бронирования;
- банковские сервисы для обнаружения и минимизации мошеннических транзакций, а также для агрегации источников данных о потенциальных рисках в реальном времени;
- логистические приложения для быстрого, надежного и оперативного онлайн-отслеживания поставок;
- сервисы для оптовых ритейлеров и розничных продавцов, которые позволят в режиме реального времени принимать управленческие решение о лучших предложениях, персонализированных рекламных акциях, ценообразовании и управлении запасами;
- корпоративные и отраслевые продукты для промышленных компаний, обеспечивающие оптимальную производительность производственных линий, оперативное получение информации о логистических цепочках в реальном времени и мониторинга телеметрических данных с конечного оборудования (автомобили, IoT-устройства, технологические датчики и пр.) для принятия своевременных решений о необходимости проверки и профилактического ремонта.
Как работать с Apache Kafka Streams API в реальных проектах больших данных, узнайте на специализированных курсах для руководителей, архитекторов, инженеров, администраторов, аналитиков Big Data и Data Scientist’ов в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
Источники

