
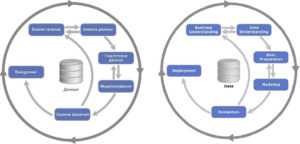
Посмотрев выступление Станислава Гафарова [1], руководителя направления по развитию ИТ-систем АО «СберТех», от 24.04.2018 на митапе AI Community и AI Today для специалистов по Data Science в офисе Авито [2], мы составили ТОП-7 ошибок при работе с данными по методологии CRISP-DM.
На основании жизненного цикла работы с информацией по стандарту CRISP-DM, эксперт выделяет 3 типа ошибок [1]:
- ошибки бизнеса и понимания данных;
- ошибки подготовки данных и моделирования;
- ошибки развертывания модели в промышленную эксплуатацию.
Далее подробно описаны ошибки каждого типа, возникающие при анализе информации, работе с большими данными (Big Data) и машинном обучении (Machine Learning).
1. Фаза Business Understanding: недостаточная подготовка к использованию CRISP-DM
CRISP-DM предполагает довольно высокий уровень зрелости бизнес-процессов по модели CMMI, о которой мы рассказывали здесь. Поэтому, если ваши процессы недостаточно формализованы, плохо документированы, вы только приступаете к сбору и анализу данных, а команда не готова принять методологию CRISP-DM и работать по ней, попытка внедрения этого стандарта не увенчается успехом.
2. Фаза Business Understanding: экстраполяция частного случая на общую ситуацию
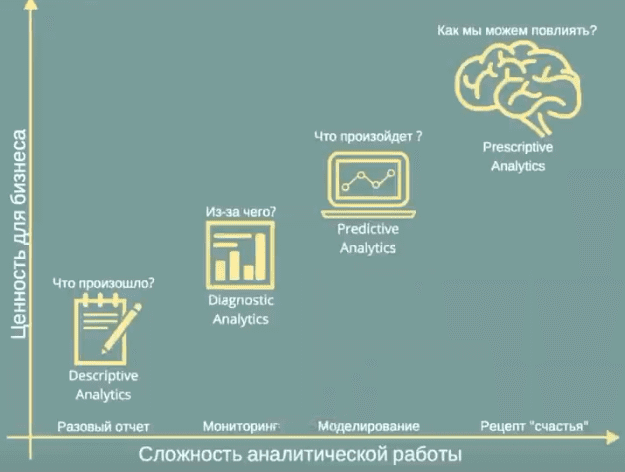
Когда модель машинного обучения (Machine Learning) построена только на единичном наборе данных вместо полноценной выборки, она не может считаться объективной и, скорее всего, противоречит реальной ситуации. Поэтому не следует строить модель на разовом отчете и сразу демонстрировать ее бизнесу (руководству и заказчикам), пропустив этапы мониторинга, диагностической и предиктивной аналитики, а также другие шаги, которые предписывает CRISP-DM.
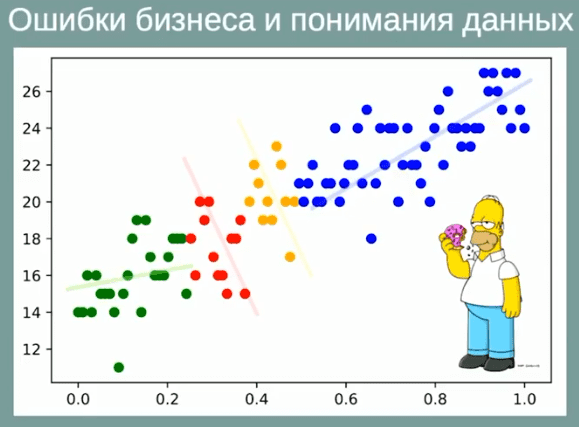
3. Фаза Data Understanding: игнорирование особенностей внутри локальных групп при учете только общих тенденций
Анализируется и принимается во внимание лишь общий тренд по всей выборке или глобальные экстремумы, без учета показателей внутри групп. Здесь имеет место парадокс Симпсона – явление в статистике, когда при наличии двух групп данных, в каждой из которых наблюдается одинаково направленная зависимость, при объединении этих групп общий тренд меняется на противоположный [3]. Этот эффект иллюстрирует неправомерность обобщений по нерепрезентативным выборкам и может привести к ошибочным выводам по локальным группам или всему набору данных.
4. Фаза Data Understanding: мнимая корреляция между несвязанными факторами
Даже если наблюдается закономерность между различными переменными, они не всегда зависимы между собой на самом деле. Может, имеет место мультиколлинеарность или между факторами в реальности отсутствует причинно-следственная связь. Например, можно построить линейный график зависимости числа выданных ипотечных кредитов от количества падающих метеоритов, но это не значит, что такая закономерность есть в реальности.
5. Фаза Data Preparation: ошибки подготовки данных по CRISP-DM
Если при настройке инфраструктуры для Data Mining было уделено недостаточно внимания вопросам хранения данных, в частности, не настроено партиционирование (partitioning) или верная индексация таблиц, то могут возникнуть ошибки при загрузке и выгрузке данных. В свою очередь, это приведет к низкой скорости получения и доставки информации и невозможности ее оперативной обработки. Все это отрицательно скажется на этапах моделирования и последующей аналитике, а потом и на общем итоге.
6. Фаза Modelling: ошибки моделирования
Когда в модель Machine Learning загружается чрезмерное количество предикторов (фич, от английского features), может возникнуть переобучение алгоритма, сократится скорость вычислений, а итоговый результат не будет истинным. Поэтому в моделирование стоит пускать только действительно значащие переменные. От этой ошибки убережет грамотная подготовка данных, выполненная на предыдущем этапе CRISP-DM.
7. Фаза Deployment: ошибки развертывания по CRISP-DM
При запуске модели Machine Learning в промышленную эксплуатацию (production) возможны следующие ошибки:
- недостаточное качество кода, например, его писал не профессиональный программист, а data scientist, специализирующийся на исследовании данных, а не разработке программного обеспечения, отсутствует code review и/или программная документация;
- отсутствие этапа тестирования или недостаточное покрытие кода тестами;
- отсутствие архивов моделей и данных, на которых выполнялась разработка и тестирование модели машинного обучения;
- деградация моделей Machine Learning, когда реальность, для которой они предназначены, изменилась, а сами модели – нет.
Подготовка данных для Data Mining на Python
Код курса
DPREP
Ближайшая дата курса
по запросу
Продолжительность
32 ак.часов
Стоимость обучения
72 000 руб.
Хотите избежать все эти и другие ошибки использования CRISP-DM в своей практике? Приходите к нам на занятия, где мы научим вас профессиональным приемам работы с большими данными (Big Data) и машинным обучением (Machine Learning). Вы освоите необходимые теоретические знания и прикладные умения, необходимые для эффективной работы аналитика и исследователя данных (data scientist), а также программиста, инженера и администратора. Выбирайте свой курс по нужной специализации, записывайтесь на занятия и приходите в наш образовательный центр! До встречи в классе!
Источники

