
Иван Гуз, директор по аналитике и клиентскому сервису Avito, 24.04.2018 на митапе AI Community и AI Today для специалистов по Data Science в офисе компании [1] рассказал о самых главных проблемах, которые подстерегают исследователя данных на практических проектах и от чего не убережет даже подробно проработанный стандарт CRISP-DM. Из его доклада [2] мы выделили топ-20 популярных ошибок и варианты их решений. Часть из них уже упоминалась в статье, посвященной выступлению Станислава Гафарова, руководителя направления по развитию ИТ-систем АО «СберТех» [3], которое состоялось в рамках того же мероприятия [1]. А в сегодняшнем материале мы подробно описываем трудности каждой фазы CRISP-DM – читайте внимательно, чтобы избежать подобных ошибок в своей практике!
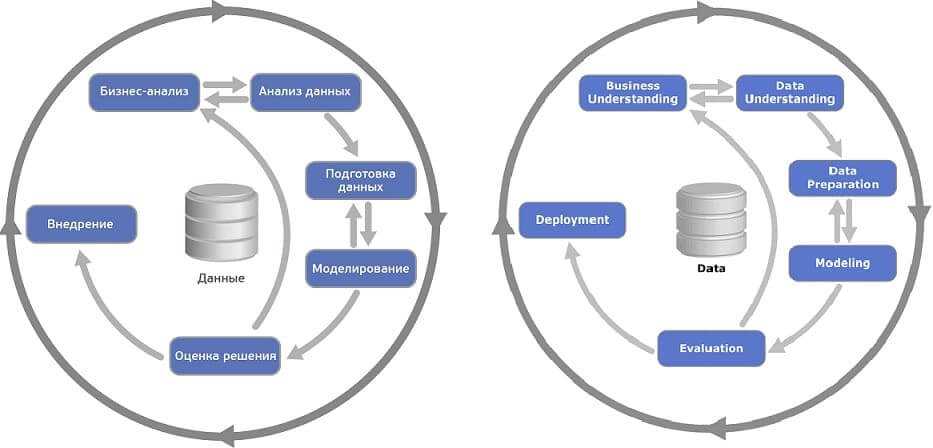
5 проблем бизнес-анализа по CRISP-DM
- Неточная постановка задачи: расплывчатые формулировки и недоказанность обоснований не позволят четко сформулировать запрос и успешно реализовать его. Часто Data Scientist полагается на исходные сведения от руководства или бизнес-аналитиков, пропуская этап самостоятельного погружения в предметную область. Чтобы точно определить целевой смысл применения технологий Big Data и Machine Learning, нужно, прежде всего, задать несколько простых вопросов: что это за проблема и действительно ли она стоит траты ресурсов (сил, времени и денег)? Как часто она повторяется: это системное несоответствие или частный случай? Как решение именно этой проблемы поможет бизнесу: принесет новых клиентов, понизит показатель оттока (Churn Rate), увеличит выручку или снизит расходы?
- Несогласованность окружения: когда заказчик и спонсоры проекта не определены, вероятность его успешного завершения близится к нулю [4]. Под заказчиком подразумевается конечный пользователь продукта – внешний или внутренний потребитель, а спонсором является тот, кто выделяет ресурсы – конкретный менеджер, начальник отдела или руководство компании в целом. Проблема, для решения которой планируется использовать большие данные и машинное обучение, должна обсуждаться и согласовываться именно с заказчиком. А спонсора больше волнуют финансовые и временные показатели проекта [4].
- Пропуск макетирования: если Data Scientist сразу приступает к реализации, не согласовав с заказчиком эскизы будущего решения, то в нем, скорей всего, будет отсутствовать ряд важных функций. А стоимость внесения изменений в программный продукт возрастает экспоненциально [5]. Поэтому важно сразу, на этапе бизнес-анализа CRISP-DM, предложить заказчику визуальные эскизы (mock-ups) будущего продукта, демонстрирующие его основные функции для решения четко сформулированной проблемы.
- Отсутствие измеряемых показателей: чтобы «продать» продукт заказчику, необходимо определить конкретные бизнес-метрики, которые улучшит продукт. Например, рост конверсии продаж на 5%, снижение оттока клиентов (Churn Rate) на 20% и т.д.
- Низкий уровень корпоративной цифровизации, управленческой и аналитической зрелости: важна не только степень упорядоченности и повторяемости бизнес-процессов, как предполагает модель CMMI, о которой мы уже рассказывали здесь. Если в компании отсутствует регулярный сбор отчетности, не отлажены процедуры и средства хранения информации, то говорить о полноценной работе по стандарту CRISP-DM, как минимум, преждевременно.

3 проблемы анализа данных по CRISP-DM
- Отсутствие четко сформулированной гипотезы, например, о влиянии фаз луны и направления ветра на средний чек покупки. Чтобы избежать этой проблемы, еще раз ответьте на вопросы: для чего разрабатывается модель машинного обучения (Machine Learning) и какова конечная цель программного решения на основе больших данных (Big Data)?
- Недостаточная вовлеченность заказчиков и экспертов: иногда даже 30-минутная беседа со специалистами предметной области будет более эффективна, чем 3-х часовое исследование «сырых» данных (raw data: документы, транзакции, записи в КИС и пр.). Кроме того, необработанные данные могут «врать»: до этапа «чистки» они содержат ошибки, опечатки и несогласованности, которые затрудняют понимание и задерживают работу Data Scientist.
- Эксклюзивные решения: разовые скрипты для визуализации данных, которые невозможно повторить, ручные операции по преобразованию данных и отсутствие документации приведут к отсутствию информации о происхождении данных (Data provenance) и истории их обработки (Data Pipeline). Избегайте «магии»: все, что вы делаете с данными, должно быть понятно, объяснимо, документировано и повторяемо.

5 проблем подготовки данных
- Слишком сложная инфраструктура, когда Data Scientist на начальном этапе работы уделяет чрезмерно много внимания техническим моментам в ущерб анализу бизнеса и данных. Не пытайтесь создать совершенный продукт сразу, CRISP-DM – это итерационная методология, которая отлично укладывается в SCRUM-подход [6].
- Мнимая простота: множество одноразовых скриптов с ручными операциями, которые не укладываются в стройную систему data pipelines. Следует найти разумный баланс между функциональностью data-инфраструктуры и затратами на ее создание и настройку.
- Отсутствие документации – эта проблема характерна и для других фаз CRISP-DM, однако, возникнув на этапе подготовки данных, она увеличит длительность последующих шагов и итераций процесса в целом. Сведения о процессе изменения данных всегда должны быть доступны и понятны.
- Смещение данных, когда информация для анализа характерна лишь для конкретного случая, а не всей выборки. Пускайте в работу весь набор данных (dataset) без искусственных ограничений, которые искажают достоверность сведений.
- Затянутость этапа, когда фаза подготовки длится чрезмерно долго. Не пытайтесь идеально сделать все и сразу, наращивайте техническую сложность своих моделей машинного обучения постепенно, от итерации к итерации. Пользуйтесь преимуществами SCRUM-подхода [6], применяя его на каждой фазе CRISP-DM.

3 проблемы на этапе моделирования
- Чрезмерный фокус на алгоритмах машинного обучения, когда Data Scientist слишком концентрируется на выборе и настройке наилучшего инструмента, забыв про данные, их подготовку и особенности предметной области. Помните, что даже самая интересная модель Machine Learning – это лишь средство достижения цели, которую перед вами поставил бизнес.
- Излишняя сложность моделей, в т.ч. чересчур большое количество предикторов. Не стоит объявлять фичами (feature) каждое свойство вашего объекта: отбрасывание лишних факторов, которые вряд ли влияют на ожидаемый результат, ускорит ваши расчеты и сохранит вам самый важный ресурс – время.
- Переобучение модели, когда примеры из обучающей выборки отработаны отлично, а из тестовой – плохо. Универсальных рецептов решения этой проблемы нет, в зависимости от конкретного случая нужно применять регуляризацию, байесовское сравнение, раннюю остановку или другие дополнительные приемы Machine Learning и статистические методы для ограничения сложности модели машинного обучения.

1 проблема фазы оценки по CRIPS-DM
Если результат моделирования вас не устраивает, качество модели Machine Learning слишком низкое, следует вернуться к этапам анализа и подготовки данных, проработав их более тщательно: добавить/убрать предикторы, исключить мультиколлинеарность факторов, переформулировать гипотезу и т.д.
3 проблемы этапа развертывания (внедрения)
- Отсутствие экспериментов на реальных данных, когда разработанное решение не тестировалось в «боевых» условиях. Перед запуском продукта в промышленное использование необходимо провести его тестовую эксплуатацию, чтобы отловить все ошибки и вовремя их исправить, не нарушая штатное течение бизнес-процессов.
- Недостаток коммуникаций с заказчиком: отсутствие обратной связи от конечного пользователя приведет, как минимум, к тому, что продуктом будет неудобно пользоваться, а как максимум – к тому, что им пользоваться вообще не будут. Самые лучшие тестировщики – это ваши заказчики, заинтересованные в удобном и эффективном инструменте для решения своих бизнес-целей.
- Отсутствие мониторинга качества модели в реальных условиях, когда не ведется наблюдение за тем, какие результаты выдает модель Machine Learning при новых входных данных и как часто возникают ситуации с ее переобучением. Ответы на эти вопросы помогут вам вовремя внести изменения в модель, чтобы и дальше применять ее с пользой для бизнеса.
Как практически решить эти и другие проблемы? Узнайте все об эффективной работе с большими данными (Big Data) и машинным обучением (Machine Learning) на наших прикладных курсах! Современные методы, средства и инструменты для аналитика и исследователя данных (Data Scientist), программиста, инженера, администратора и даже пользователя Big Data-инфраструктуры. Выбирайте программу по своей специализации, записывайтесь на занятия и приходите в наш обучающий центр! Увидимся в классе!
Источники

