
Flink часто сравнивают с Apache Spark, другим популярным инструментом потоковой обработки данных. Оба этих распределенных отказоустойчивых фреймворка с открытым исходным кодом используются в высоконагруженных Big Data приложениях для анализа данных, хранящихся в кластерах Hadoop [1] и других кластерных системах. В этой статье мы поговорим, чем похожи и чем отличаются Флинк и Спарк, а также рассмотрим, в каких случаях оптимально выбрать тот или иной продукт.
5 сходств Apache Flink и Spark
Apache Flink и Spark во многом очень похожи: у них одно прикладное назначение и похожие особенности реализации кластерной обработки потоковых данных. Также для них обоих характерны следующие свойства:
- оба продукта вышли из академической среды – Спарк из университета Беркли (UC Berkley), а Флинк – из берлинского ВУЗа TU University [2];
- оба решения поддерживают Лямбда-архитектуру (Lambda Architecture) – универсальный подход, направленный на применение произвольной функции к произвольному набору данных с минимальным период ожидания возвращения искомого значения [3];
- наличие встроенных средств для выполнения графовых операций, машинного обучения или SQL-аналитики – в Спарк за это отвечают компоненты GraphX, MLlib, Spark SQL, а во Флинк – библиотеки Gelly, FlinkML и Table-API соответственно;
- гарантия строго однократной доставки сообщений (exactly once);
- надежность, масштабируемость и отказоустойчивость характерны для обоих продуктов.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
1 августа, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
3 главных отличия Флинк и Спарк
При этом сходстве Флинк существенно отличается от Спарк по следующим характеристикам:
- время задержки (latency) – Flink обеспечивает обработку данных в режиме реального времени с задержкой порядка 1 миллисекунды, тогда как для Spark latency может составлять несколько секунд;
- режим работы с данными – несмотря на то, что Spark является средством потоковой обработки Big Data, он реализует микропакетный подход (micro-batch), а Flink обеспечивает полноценную работу как в поточном, так и в пакетном режимах с помощью разных API – для потоков DataStream API и DataSet API для пакетов;
- зрелость, поддержка сообщества и реализация в коммерческих продуктах – в настоящее время Apache Spark более распространен среди Big Data решений и сообщества специалистов. Для Flink пока характерны некоторые проблемы на уровне реализации, например, высокое потребление CPU, чувствительность к сетевым проблемам [4], но доля этих недостатков снижается с каждым новым релизом.
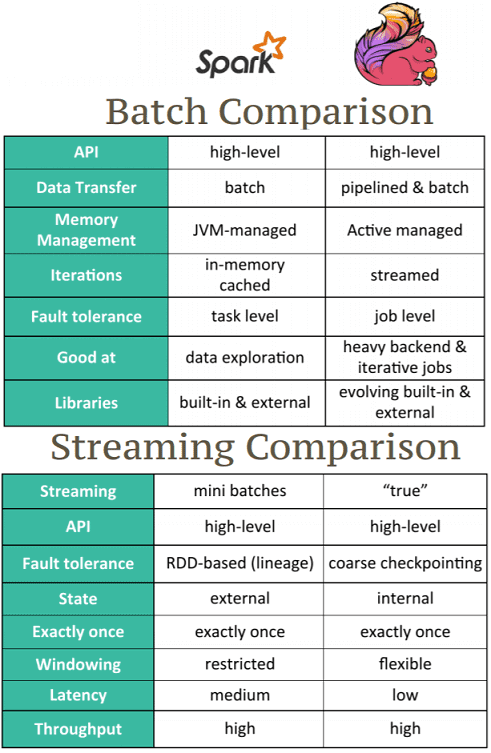
Более подробное сравнение фреймворков читайте в нашей новой статье.
Где используется Apache Flink и способен ли он заменить Spark
По мере развития спроса на потоковую обработку больших данных, популярность Флинк уверенно растет. В частности, Flink используется международной компанией по доставке еды и пассажирским перевозкам Uber и одной из крупнейших платформ интернет-торговли Alibaba [2]. Также стоит отметить, что именно Flink выбран в качестве средства потоковой обработки Big Data в Arenadata, отечественном дистрибутиве Apache Hadoop. В свою очередь, конкурент Флинк, Apache Spark, используется в дистрибутиве хадуп от компании Cloudera (CDH, Cloudera’s Distribution including Apache Hadoop) и применяется в Big Data решениях таких интернет-гигантов, как Amazon, Yahoo!, NASA JPL, eBay Inc., Baidu и др. [5].

Таким образом, еще пока рано говорить о Флинк как о полноценной альтернативе Apache Spark. Однако, если необходимо обеспечить обработку потоков и пакетов Big Data «на лету», собирая данные из Kafka, Amazon Kinesis, HDFS, Cassandra, Google Cloud Platform, HBase и других файловых хранилищ, то Apache Flink может стать хорошим инструментом для графовых вычислений, SQL-аналитики и машинного обучения (Machine Learning).
Потоковая обработка в Apache Spark
Код курса
SPOT
Ближайшая дата курса
16 мая, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Узнайте больше особенностей Apache Spark и Flink, чтобы эффективно использовать их для разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- https://ru.bmstu.wiki/Apache_Flink
- https://medium.com/@chandanbaranwal/spark-streaming-vs-flink-vs-storm-vs-kafka-streams-vs-samza-choose-your-stream-processing-91ea3f04675b
- http://datareview.info/article/lyambda-arhitektura-novyiy-podhod-k-analizu-dannyih/
- https://habr.com/ru/company/ivi/blog/347408/
- http://datareview.info/article/obrabotka-potokovyx-dannyx-storm-spark-i-samza/

