Сегодня мы поговорим о заблуждениях насчет базового инфраструктурного понятия хранения и обработки больших данных – экосистеме Hadoop и развеем 3 самых популярных мифа об этой технологии. А также рассмотрим применение Cloudera, Hortonworks, Arenadata, MapR и HDInsight для проектов Big Data и машинного обучения (Machine Learning).
Миф №1: Hadoop – это сложно
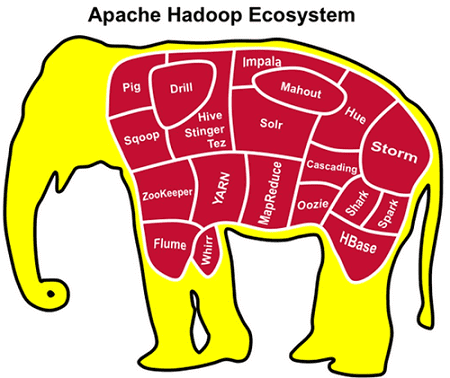
Если настраивать инфраструктуру для Big Data проектов «с нуля», взяв за основу классический дистрибутив проекта Hadoop, развернуть экосистему для больших данных будет довольно трудоемким и длительным процессом, с которым справится не каждый системный администратор. Как правило, чтобы сократить время развертывания и сложность администрирования, используют готовые решения на основе Hadoop: Cloudera, Hortonworks, Arenadata, MapR или HDInsight [1]. Эти продукты уже содержат в себе не только 4 основных модуля хадуп (файловая система HDFS, MapReduce, Yarn и Hadoop Common) от Apache Software Foundation. Также в них присутствуют дополнительные инструменты для обработки разноформатных данных и интеллектуального анализа информации (Data Mining), в том числе с использованием машинного обучения [2]:
- решения для управления потоками данных (Flume, Sqoop);
- фреймворки для распределённой и потоковой обработки, а также брокеры сообщений (Spark, Storm, Kafka)
- нереляционные СУБД и SQL-движки для Big Data аналитики (HBase, Hive, Impala, Shark, Drill);
- высокоуровневый процедурный язык для выполнения запросов к большим слабоструктурированным наборам данных (Pig);
- координаторы и планировщики задач (Zookeeper, Hue, Oozie, Azbakan);
- средства Machine Learning (Mahout, Spark MLlib).
В готовых решениях все эти инструменты уже интегрированы между собой и сопровождаются полным пакетом программной документации, что облегчает процессы администрирования и поддержки инфраструктуры для больших данных [1]. Разумеется, за удобство надо платить – об этом следующий пункт.

Миф №2: хадуп – это дорого
Сам по себе дистрибутив Apache Hadoop совершенно бесплатен, последняя версия которого всегда доступна для скачивания на официальном сайте Apache Software Foundation [3]. Однако, вышеупомянутые интегрированные решения на основе этой технологии (Cloudera, Hortonworks, MapR, HDInsight) являются коммерческими продуктами, за использование которых необходимо платить. Тем не менее, совсем необязательно разворачивать Big Data инфраструктур на собственных мощностях, инвестируя большие деньги в создание своего кластера. Множество провайдеров предлагают в аренду защищенные облачные системы хранения и обработки больших данных с круглосуточной поддержкой, взимая плату только за фактическое время использования процессорных ядер по модели PaaS (Platform as a Service). Среди наиболее популярных и надежных облачных платформ для Big Data проектов сегодня можно назвать решения Amazon Web Services, Microsoft Azure, Mail.Ru Cloud Solutions, Google Cloud Platform, SAP Cloud Platform, Яндекс.Облако, OnCloud, а также сервисы от компаний Техносерв и КРОК [4]. Подробнее о достоинствах и недостатках облачных кластеров читайте здесь, а детальному сравнению популярных PaaS-решений для Big Data мы посвятили отдельную статью.
Миф №3: Швейцарский нож 21 века – универсальное и автоматическое решение для Data Science
Этот миф содержит большую долю правды, т.к. действительно Hadoop является основой для работы с большими данными и потенциально может быть использован в любых проектах Big Data. Однако, даже при использовании готовых коммерческих решений (Cloudera, Hortonworks, Arenadata, MapR или HDInsight), в состав которых уже включены средства предварительной обработки и аналитики, сами по себе они решат главную задачу Data Science: превращение сырых данных в сведения, полезные для бизнеса. Ошибочно рассматривать Hadoop как универсальный черный ящик, который сам волшебным образом преобразует любую, в т.ч. «мусорную» информацию в работающие модели машинного обучения. Специалисты, ответственные за администрирование и поддержку Big Data инфраструктуры (data engineer, data administrator), не заменят исследователя или аналитика больших данных (data scientist, data analyst), который решает прикладные задачи, формулируя бизнес-гипотезы и тестируя их с помощью алгоритмов Machine Learning. Hadoop и основанные на нем решения являются лишь программным инструментом, который хорошо работает лишь в руках опытного профессионала, но абсолютно бесполезен сам по себе.
Основы и детали Hadoop для проектов Big Data и Machine Learning: настройка, администрирование и использование на наших компьютерных курсах обучения всех категорий пользователей, от «чайников» до профессионалов – хадуп для инженеров, администраторов и аналитиков больших данных в Москве:
- INTR: Основы Hadoop
- HADM: Администрирование кластера Hadoop
- DSEC: Безопасность озера данных Hadoop
- HDDE: Hadoop для инженеров данных
- BAHU: Основы Hadoop для пользователей
Источники