Рассматривая практическое обучение Kafka, сегодня мы поговорим, зачем нужен Zookeeper и можно ли использовать Кафка без этой централизованной службы синхронизации распределенных сервисов. Читайте в нашей статье о роли Zoo в системах обработки больших данных (Big Data) и о том, может ли Apache Kafka эффективно работать без Zookeeper, а также как это реализовать.
Что такое Apache Zookeeper и зачем он нужен Kafka, а также другим Big Data системам
Apache Zookeeper – это централизованная служба для поддержки информации о конфигурации, именования, обеспечения синхронизации распределенных приложений и предоставления групповых служб. За счет своего API, Зукипер берет на себя координацию распределенных сервисов, позволяя разработчику Big Data сосредоточиться на логике своего приложения. С развитием основных технологий больших данных (Apache Hadoop, HBase, Kafka), Zoo стал стандартом де-факто для отслеживания состояния распределенных данных, синхронизации приложений и координации всего кластера [1].
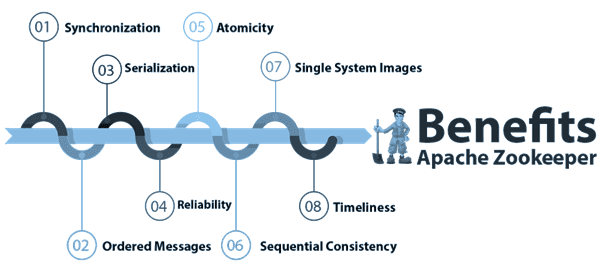
Сам по себе ZooKeeper является распределенным приложением, которое предоставляет услуги для создания новых распределенных программ. Подробнее о том, как работает Zoo, мы расскажем в отдельной статье, а пока рассмотрим основные выгоды от использования этого сервиса [1]:
- простота распределенной координации, включая возможность распределения узлов по разным дата-центрам;
- автоматическая синхронизация за счет взаимного исключения и сотрудничества между серверными процессами;
- упорядоченность сообщений и управление их очередями с гарантией доставки;
- сериализация– кодирование данных по заданным правилам;
- транзакционность – атомарность передачи данных (полностью и успешно или вообще нет);
- последовательная согласованность обновлений, когда они применяются в том же порядке, в каком они были отправлены;
- единообразие системы, когда независимо от сервера подключения, клиент всегда увидит одно и то же представление нужного сервиса;
- своевременность обновления представления о системе по заданному временному интервалу;
- отказоустойчивость – сохранность данных и работоспособность, когда один из серверов очереди недоступен.
Как Кафка использует Зукипер и в чем здесь проблема
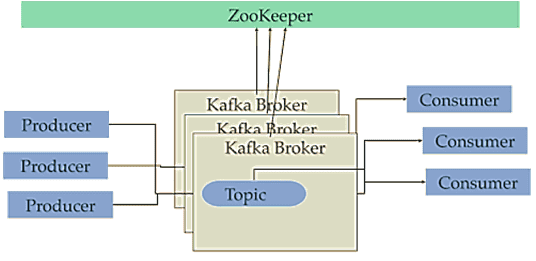
Apache Kafka использует ZooKeeper для хранения метаданных о разделах (partitions) своих топиков (topics) и брокерах, а также для выбора брокера в качестве контроллера Кафка [2]. Проще говоря, Зукипер информирует каждого брокера Kafka о текущем состоянии кластера. Благодаря этого каждому клиенту Kafka (издателю/подписчику) нужно всего лишь подключиться к какому-либо брокеру, а обновление метаданных у него произойдет автоматически [3].
Таким образом, Зукипер нужен Кафке для обеспечения надежной согласованности состояния кластера, его конфигурации и обнаружения одноранговых узлов. Однако, на практике такая зависимость Kafka от Zoo сбивает с толку новичков в Big Data, усложняя развертывание Кафка [4].
Кроме того, для любой Big Data системы на базе этой централизованной службы характерны следующие недостатки [1]:
- избыточное количество серверов;
- дополнительное время на синхронизацию данных во всех узлах очереди.
Также некоторая рассогласованность между Кафка и Зукипер может привести к проблемам запуска брокера сообщений. Например, когда после перезагрузки сервера Kafka не видит Zoo из-за того, что еще не запустился сетевой интерфейс [5]. Подобная проблема несогласованности состояний в Зукипер и в приложениях потоковой обработки событий возникает из-за разной скорости смещения в топиках Кафка. При этом состояние в Zoo может не соответствовать тому, что хранится в памяти контроллера Big Data приложения. Это решается только через периодическую синхронизацию, но в реальности между этими периодами может возникнуть рассогласование [2].
Еще стоит отметить, что при отказе Зукипер или разрыве соединения его с Кафка, пользователи могут потерять сообщения. Впрочем, частично это проблема решается с помощью настройки свойства acks на стороне producer’а [6]. Как это сделать на практике, расскажут наши курсы по Kafka.
Чем заменить Зукипер: Atomix, Jocko, Consul и еще пара альтернатив Zoo
Вышеперечисленные недостатки Zookeeper привели к появлению альтернативных решений для централизации распределенных сервисов. В частности, одним из них является Consul от компании HashiCorp – служба для подключения и защиты сервисов на любой платформе выполнения, в публичном или частном облаке. Он основан на Serf — легковесном и эффективном децентрализованном инструменте, который обеспечивает обнаружение сбоев, услуг и пользовательских событий, а также членство в кластере. Serf использует Gossip-протокол для распространения проверок работоспособности и обнаружения сбоев, что подходит для кластеров любого размера. На практике вместе с библиотекой Serf также используется решение Ralf для достижения консенсуса и выбора лидера. Сочетание этих инструментов также применяется в другой альтернативе Zoo – брокере Josco [4].
Администрирование кластера Kafka
Код курса
KAFKA
Ближайшая дата курса
29 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Еще одним вариантом замены Zookeeper является Atomix – управляемая событиями Java-инфраструктура для распределенных систем. Java-примитивы в ней (maps, блокировки и счетчики) поддержаны одним из распределенных протоколов (Raft, Gossip или Primary-Backup). Библиотека поставляет строительные блоки, которые позволяют реализовать управление кластером, членство в группах, выбор лидера, управление распределенным параллелизмом, разбиение и репликацию. Для хранения метаданных Kafka рекомендуется использовать протокол Raft, т.к. нужны гарантии строгой согласованности. При замене Zookeeper на Atomix процесс развертывания Кафка упростится, т.к. эта Big Data система не будет полагаться на внешний сервис [6].
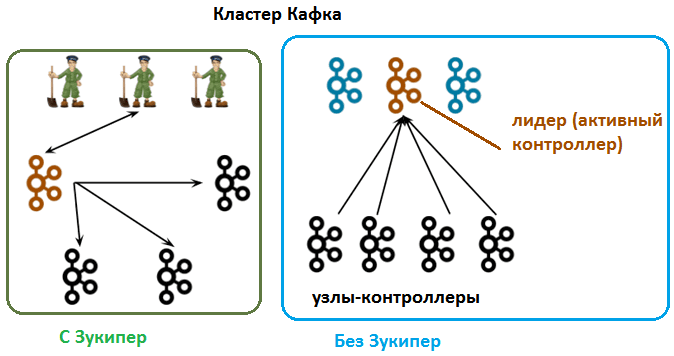
Более того, стремление избежать зависимости от сервиса привело к тому, что сами разработчики Apache Kafka в компании Confluence решили заменить Зукипер внутренним инструментом. Для этого в октябре 2019 года началась разработка решения под названием Self-Managed Metadata Quorum. Предполагается, что метаданные должны храниться не во внешней системе, а в самой Kafka, чтобы избежать проблем с рассогласованием между состояниями контроллера и Zookeeper. Вместо того, чтобы отправлять уведомления брокерам, брокеры должны просто использовать события метаданных из журнала событий. Это гарантирует, что изменения метаданных всегда будут поступать в одном и том же порядке. Брокеры смогут хранить метаданные локально в файле. При запуске им нужно только прочитать то, что изменилось с контроллера, а не считывать все состояние целиком. Это позволит поддерживать больше разделов (partitions) с меньшим энергопотреблением CPU. Узлы контроллеров будут образовывать кворум и сами автоматически выбирать лидера для управления журналом метаданных и обработки всех удаленных вызовов (RPC) из брокеров. Все контроллеры реплицируют данные с лидера, обеспечивая «горячее» резервирование в случае его отказа. Таким образом все контроллеры теперь будут отслеживать последнее состояние, и восстановление после сбоя контроллера не потребует много времени на передачу состояния новому контроллеру. А за счет кворума такой кластер будет работоспособным даже при отказе нескольких узлов. Ожидается, что такая архитектурная концепция будет реализована в ближайшем будущем [2]. Таким образом, возможно, уже в 2020 году Zookeeper уже не будет обязательным компонентом Apache Kafka, а также Hadoop, HBase и других кластеров Big Data. Как это реализовано в новой версии Kafka, выпущенной в апреле 2021 года, читайте здесь.
В следующей статье мы рассмотрим особенности использования Кафка в высоконагруженных системах и способы повышения ее производительности. Станьте профессионалом по управлению кластерами Apache Kafka, пройдя обучение Кафка на специализированных практических курсах в «Школе Больших Данных» — лицензированном учебном центре для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://ru.bmstu.wiki/Apache_ZooKeeper
- https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum
- https://stackoverflow.com/questions/23751708/is-zookeeper-a-must-for-kafka
- https://thehoard.blog/building-a-kafka-that-doesnt-depend-on-zookeeper-2c4701b6e961
- https://ru.stackoverflow.com/questions/589362/Проблемы-с-запуском-apache-kafka-после-перезагрузки-сервера
- https://medium.com/@lukasz.antoniak/apache-kafka-leaves-the-zoo-bef529ba82b7

