Не претендуя на лавры Мэри и Тома Поппендиков, которые впервые освятили применение Lean в разработке ПО, сегодня мы расскажем, как идеи бережливого производства реализуются в области Big Data. Читайте в нашей статье про принцип вытягивания в Apache Kafka, концепцию «точно вовремя» в Apache Spark, SMED в Kubernetes и облачных кластерах on-demand, карты потоков создания ценностей и конвейеры больших данных в цифровизации бизнес-процессов, систему 5S в резидентных СУБД и канбан-подход в Airflow.
Lean-вытягивание сообщений в Apache Kafka
В управлении производством Lean-термины вытягивание (pull) и выталкивание (push) противопоставляются друг другу, при этом их не совсем корректно интерпретируют следующим образом: выталкивание – это работа на склад, а вытягивание – на заказ (реальный спрос). Более верным считается следующее определение: вытягивающая система явно ограничивает объем незавершенного производства, который может быть, а выталкивающая не накладывает никаких явных ограничений на объемы незавершенного производства [1]. В области Big Data ярким примером вытягивания и выталкивания можно назвать модели работы с сообщениями в брокерах Apache Kafka и RabbitMQ. Напомним, клиент или потребитель сообщений Kafka сам вытягивает (pull) нужные данные из топика, ориентируясь на смещение. В RabbitMQ, наоборот, брокер реализует всю логику работы с сообщениями, проталкивая их потребителям (push). Поэтому, в отличие от Apache Kafka, RabbitMQ не гарантирует строго однократную доставку сообщений (exactly once), которая обеспечивает отсутствие потери или дублирования информации.
Точно вовремя или отложенные вычисления Apache Spark
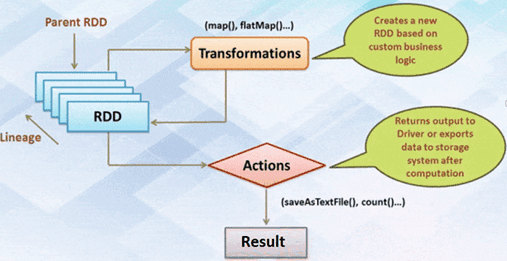
Принцип Just in Time в Big Data отражает концепция отложенных или ленивых вычислений в Apache Spark, когда операции обработки данных откладываются до тех пор, пока не понадобится их результат. Например, при работе с RDD (Resilient Distributed Dataset, надежная распределенная коллекция данных типа таблицы), которая является основным вычислительным примитивом Spark, результат вычисляется не сразу. Сначала преобразование, примененное к информации, просто запоминается, а его непосредственное выполнение происходит только тогда, когда для действия необходимо отправить результат. В других структурах данных Apache Spark, DataFrame и DataSet вычисления также производятся только тогда, когда появляется действие, к примеру, результат отображения, сохранение вывода. Подробнее об этом мы писали здесь.
Быстрая переналадка: DevOps-подход и гибкое масштабирование кластеров Big Data
Горизонтальная масштабируемость, когда вычислительная мощность кластера наращивается с помощью простого добавления новых узлов, — важное достоинство многих Big Data систем. Например, такое преимущество имеют Apache Kafka, HBase, Cassandra, Hive, NiFi, AirFlow, Spark, Flink, Storm и Samza.
Другой пример принципа быстрой переналадки в технологиях больших данных относится к DevOps-технологиям. В частности, активное применение Kubernetes для быстрого тестирования и развертывания новых приложений и сред исполнения, упакованных в контейнеры. Подобная практика быстрой переналадки кластера прослеживается в гибридных облаках, когда корпоративная ИТ-архитектура построена на сочетании публичных и частных облачных решениях. Например, частные облака могут использоваться для конфиденциальных приложений и данных, а публичные – для других вычислительных задач. Основной плюс гибридного подхода – гибкое масштабирование по запросу (on demand), когда мощность облачного кластера меняется в зависимости от текущих задач, обеспечивая максимально эффективное использование ресурсов с точки зрения экономики. Kubernetes, как и гибридные облака, вошли в ТОП-5 трендов 2020 года в области Cloud Computing [2].
Data pipeline как поток создания ценностей: цифровизация VSM и расширенная аналитика Big Data для автономной диагностики и непрерывного улучшения
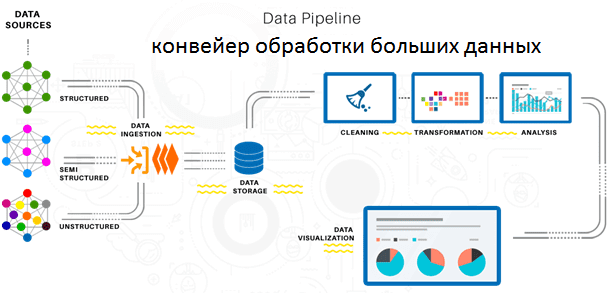
Как мы уже рассказывали, картирование потоков создание ценностей помогает не только визуализировать производственную деятельность, но и определить ее узкие места за счет анализа основных показателей каждого процесса. Современное понимание информации как основного средства обеспечения жизнедеятельности любого предприятия и цифровизация всех его бизнес-процессов позволяет составить VSM автоматически. Например, устройства интернета вещей (Internet of Things) обеспечивают непрерывный сбор данных с технологического оборудования, а дальнейшая работа с этой и другой корпоративной информацией автоматизирована в виде конвейеров обработки данных (data pipelines). При этом ведется непрерывный анализ работы каждого такого конвейера с помощью средств расширенной аналитики больших данных: алгоритмов машинного обучения и других методов искусственного интеллекта. Таким образом Big Data реализует еще один принцип Lean: автономную диагностику оборудования и оптимизацию его работы.
Элементы системы 5S и канбан: быстрые вычисления и статусы задач
Из всех 5 шагов системы 5S в технологиях Big Data наиболее ярко используется принцип соблюдения порядка, когда упорядоченное и точное расположение и хранение необходимых вещей позволяет быстро и просто их найти и использовать. В частности, именно эта идея заложена в вычислительную модель Apache Spark. Напомним, Spark, в отличие от классического обработчика ядра Hadoop c двухуровневой концепцией MapReduce на базе дискового хранилища, выполняет рекуррентные вычисления в оперативной памяти. Благодаря отсутствию операций записи и чтения с жесткого диска, задачи выполняются значительно быстрее, обеспечивая многократный доступ к загруженным в память пользовательским данным. Поэтому Spark MLLib позволяет эффективно работать с алгоритмами машинного обучения.
Подобный принцип размещения данных в памяти для быстрой работы с ними реализован в резидентных СУБД, в частности, Redis. Однако, по мере роста данных возникают проблемы с производительностью Big Data системы. Поэтому в дополнение к in-memory базам используются серверы постоянной памяти (Persistent memory services). Именно эту технологию, наряду с расширенной аналитикой данных, исследовательское бюро Gartner включило в 10 самых перспективных трендов 2020 года в области Data&Analytics [3].
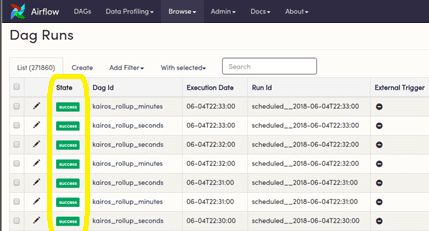
Наконец, визуализация статусов задач по принципу канбан-доски реализована во многих Big Data системах мониторинга и управления потоками данных. В частности, графический веб-интерфейс Apache Airflow позволяет наглядно отслеживать состояние задач, маркируя цветом статус их успешного выполнения или случаи сбоя.
В следующей статье мы рассмотрим, какие виды потерь по концепции Lean существуют в ИТ и как их устранить средствами Big Data. Другие особенности применения принципов бережливого производства в кейсах цифровизации бизнеса и аналитики больших данных вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Источники

