Продолжая разговор про межрегиональную репликацию Apache Kafka, сегодня рассмотрим 4 способа ее реализации: мультирегиональный кластер, MirrorMaker 2, Cluster Linking в Confluent Server и Confluent Replicator. Чем георепликация Kafka с MirrorMaker 2 отличается от решений Confluent и что выбирать для различных сценариев. Мультирегиональный кластер Confluent Геораспределенная репликация реплицирует данные по кластерам...
2 решения Confluent для мультирегиональной георепликации Apache Kafka
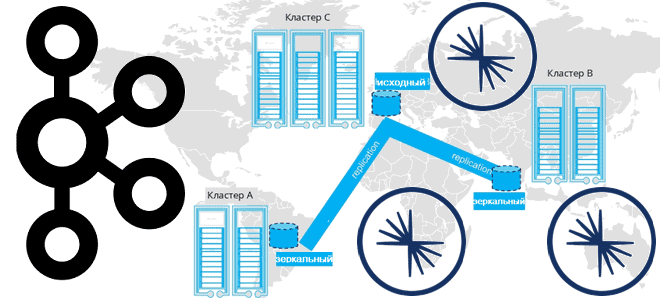
Недавно мы писали про мультирегиональную репликацию Apache Kafka. Сегодня рассмотрим, как выполнить геораспределенную репликацию с помощью Cluster Linking в Confluent Server и Kafka Connect с Confluent Replicator. Cluster Linking для Apache Kafka Связанные кластеры представляют собой 2 или более кластера в разных географических регионах. В отличие от топологии растянутого кластера,...
Мультирегиональная репликация Apache Kafka: кластерные топологии
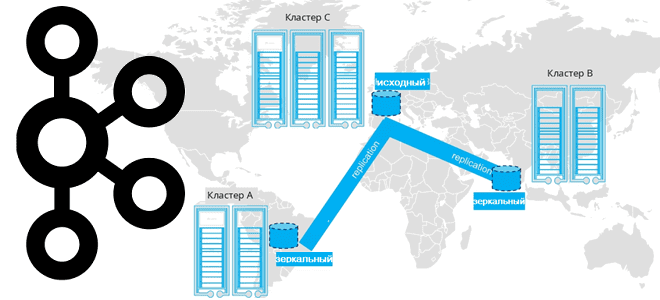
Какую топологию может иметь кластер Apache Kafka при межрегиональной репликации по нескольким ЦОД и как это реализовать. Чем брокеры-наблюдатели отличаются от подписчиков в Confluent Server и при чем здесь конфигурация подтверждений acks в приложении-продюсере. Принципы репликации данных в Apache Kafka Будучи средством интеграции информационных систем в режиме реального времени, Apache...
Сколько стоит инфраструктура Apache Kafka: 2 главные статьи затрат

Какие инфраструктурные компоненты самые дорогие в эксплуатации популярной платформы потоковой передачи сообщений и как снизить затраты на сетевые ресурсы и хранилища данных при использовании Apache Kafka. TCO для Apache Kafka: что учитывать в расчете затрат Поскольку Apache Kafka используется для интеграции информационных систем в режиме реального времени, она становится критически...
3 условия соединения многораздельных потоков в Kafka Streams
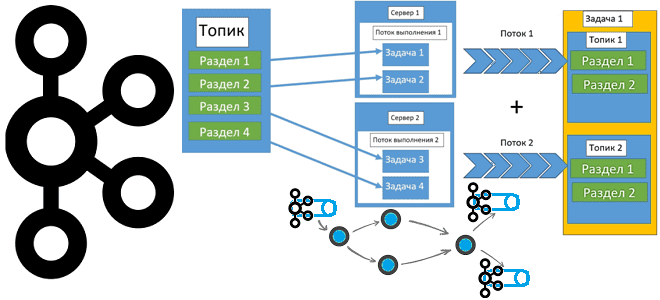
Почему нельзя просто взять и соединить потоки Kafka Streams с разным числом разделов, и как это все-таки сделать без изменения конфигурации топика. Почему нельзя просто взять и соединить потоки Kafka Streams с разным числом разделов Kafka Streams – это клиентская Java-библиотека для разработки потоковых приложений, которые работают с данными, хранящимися...
Динамическое и статическое членство потребителей Apache Kafka
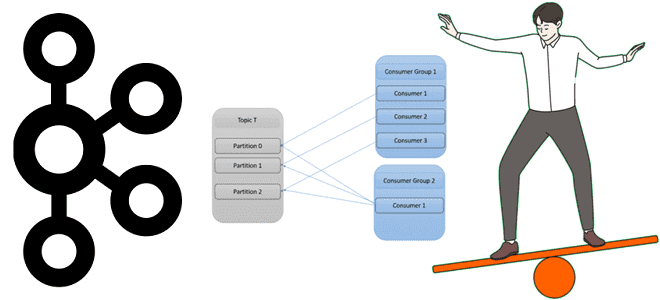
Чем group.instance.id отличается от group.id, зачем нужен member.id, каковы преимущества статического членства в группе потребителей перед динамическим и какие механизмы Kafka обеспечивают ребалансировку клиентских приложений. Еще раз про группы потребителей Apache Kafka Напомним, группы потребителей в Apache Kafka нужны для логического объединения нескольких потребителей с целью повышения надежности потоковой системы....
Когда развернуть еще один кластер Apache Kafka и как им управлять?

Что лучше: один или несколько кластеров Apache Kafka, когда и зачем разворачивать новый кластер вместо масштабирования существующего, какие задачи администрирования поручить локальным DevOps-инженерам, а что решать централизовано. Один или несколько кластеров Apache Kafka? Продолжая разговор про эффективное управление корпоративным кластером Apache Kafka, сегодня рассмотрим, когда и зачем нужно разворачивать новый...
Централизация или независимость: стратегия управления корпоративным кластером Apache Kafka
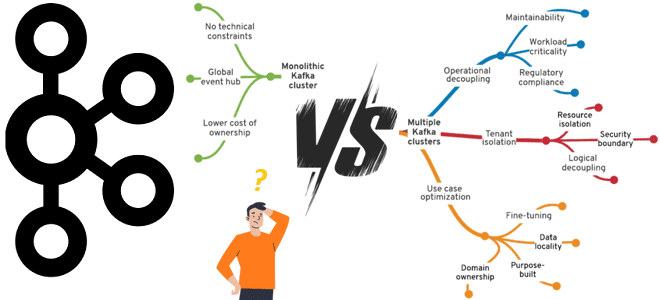
Что выбрать для эффективного управления корпоративным кластером Apache Kafka, от чего зависит уровень централизации и какие факторы влияют на принятие решений. Стратегии управления корпоративным кластером Apache Kafka Типовой вариант использования Apache Kafka – это потоковая интеграция корпоративных приложений. Чтобы эффективно использовать эту платформу потоковой передачи событий в масштабах предприятия, необходимо...
Магический байт в сообщениях и реестр схем Apache Kafka: проблемы и решения
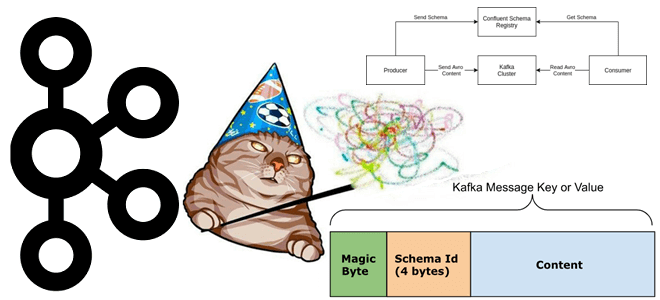
Что такое неизвестный магический байт, почему возникает эта ошибка и как предупредить такое исключение сериализации при работе с Kafka Streams, клиентами Apache Kafka и реестром схем. Что такое магический байт в сообщении Чтобы корректно обработать на стороне потребителя сообщение, считанное из Kafka, необходимо знать его формат, поскольку данные, публикуемые приложением-продюсером...
Как повысить надежность кластера Apache Kafka: сбои публикации и стратегии их устранения
Какие меры принять администратору кластера Apache Kafka, чтобы повысить надежность потоковой экосистемы, использующей эту распределенную платформу как средство интеграции различных приложений. Сбои в потоковой экосистеме и способы их устранения Хотя Apache Kafka считается высоконадежной системой благодаря множеству встроенных механизмов отказоустойчивости, таким как репликация и перевыборы лидера. Впрочем, это не исключает...