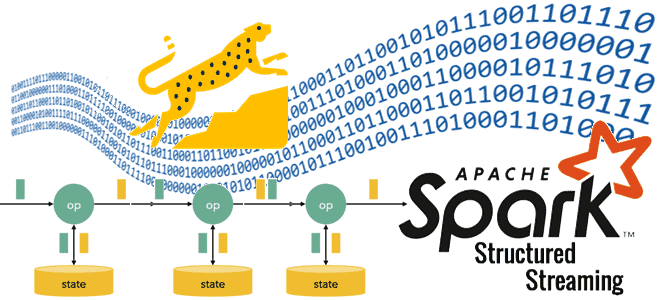
Где stateful-операторы хранят состояния, почему RocksDB лучше HDFSBackedStateStore и как Databricks адаптировал key-value хранилище к особенностям Spark Structured Streaming, чтобы сделать потоковую обработку больших данных еще быстрее. Где stateful-операторы Spark Structured Streaming хранят состояния? Хотя Apache Spark Structured Streaming реализует потоковую парадигму обработки информации, он по-прежнему использует микропакеты, т.е. ограниченные...
Хранение состояний в Apache Spark Structured Streaming и новый State Reader API от Databricks
Где хранятся состояния операторов в stateful-приложениях Apache Spark Structured Streaming, зачем разработчику нужны данные о состояниях, как их получить и чем для этого полезен новый API State Reader от Databricks. Хранение состояние в Apache Spark Structured Streaming В феврале 2024 года компания Databricks выпустила очередную версию Databricks Runtime – среду...
Журналирование событий в Apache Spark и сжатие лог-файлов

Когда журналирование событий может привести к OOM-ошибке, где отслеживать системные метрики приложения Apache Spark, зачем сжимать лог-файлы и как это сделать. Логирование системных метрик в приложении Apache Spark Поскольку фреймворк Apache Spark изначально предназначен для создания высоконагруженных распределенных приложений пакетной и потоковой обработки больших объемов данных, он позволяет отслеживать системные...
4 модели потоковой парадигмы обработки данных
Чем пакетная парадигма обработки данных отличается от пакетной и как она реализуется на практике: принципы работы и воплощение в Big Data на примере Apache Spark, Kafka и Flink. Еще раз о разнице потоковой и пакетной парадигмы обработки данных Пакетная обработка и потоковая обработка — это две разные парадигмы обработки данных....
Обратное давление в потоковой передаче событий
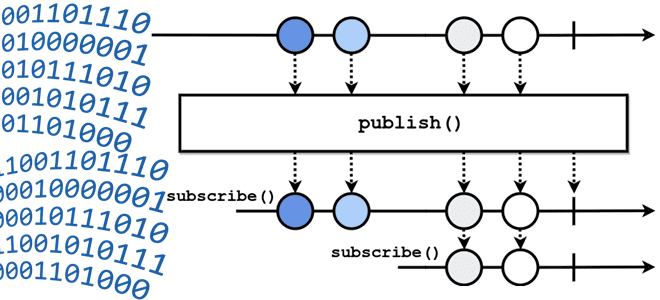
Что означает термин backpressure и зачем создавать обратное давление в streaming-системах: разбираемся с методами управления пропускной способностью потоковой передачи событий на примере Apache Kafka, Flink, Spark и NiFi. Что такое обратное давление: backpressure в конвейерах потоковой обработки данных Понять, как работает сложная концепция, проще всего на простых примерах. Это общее...
Stateful-операторы в Apache Spark Structured Streaming
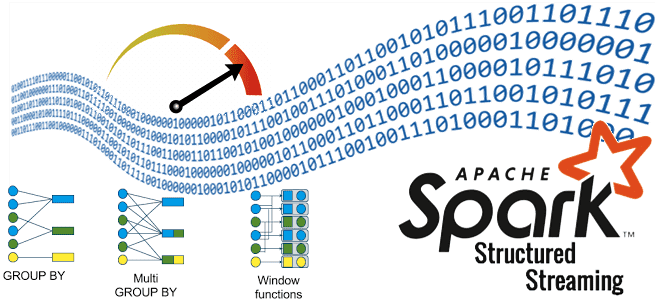
Как выполнение нескольких stateful-операторов в одном потоке снижает стоимость обработки данных: возможности и ограничения Spark Structured Streaming. Про водяные знаки и состояния в потоковой передаче событий. Stateful-операторы и водяные знаки в потоковой обработке данных Благодаря распределенной обработке микропакетов в памяти Spark Structured Streaming позволяет обрабатывать огромные объемы данных очень быстро....
Как Apache Spark планирует и запускает задания в кластере
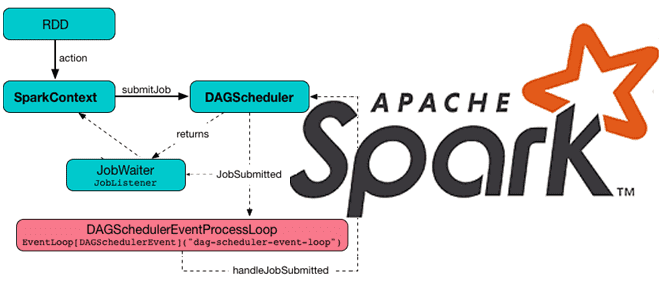
Какие механизмы и компоненты позволяют Apache Spark планировать задания и эффективно утилизировать ресурсы кластера. Чем статическое разделение ресурсов отличается от динамического, и как настроить планировщик для ускорения вычислений. Планирование заданий в Apache Spark Распределенный характер Apache Spark предполагает наличие инструментов для разделения ресурсов между вычислениями. В режиме кластера каждое приложение...
Как настроить оборудование для ускорения работы Apache Spark

Зачем размещать задания Apache Spark на узлах HDFS, какую пропускную способность сети передачи данных выбрать, почему не рекомендуется использовать RAID для жестких дисков, сколько выделить памяти и ядер ЦП. Рекомендации по настройке оборудования для Spark-приложений На практике большинство заданий Spark считывает входные данные из внешней системы хранения, например, файловой системы...
Профилирование PySpark-кода: пример с приложением Apache Spark для Python-разработчика
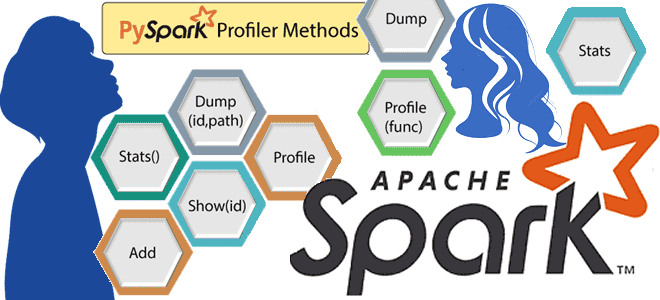
Что такое профилирование кода, зачем это нужно и как работают Python-профилировщики в приложениях Apache Spark. Пример профилирования PySpark-программы. Что такое профилирование и почему это важно для PySpark-приложений Будучи написанном на java и Scala, Apache Spark также поддерживает декларативные API-интерфейсы Python, которые позволяют разработчику писать и запускать код на этом более...
Барьерный режим выполнения в Apache Spark и при чем здесь глубокое обучение
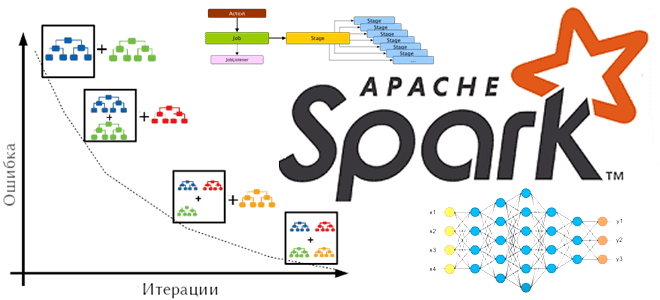
Что такое барьерный режим выполнения в Apache Spark, чем он отличается от вычислительной модели MapReduce, как связан с глубоким машинным обучением и где используется на практике. Что такое барьерный режим выполнения в Apache Spark Способ выполнения заданий Spark определяется режимом выполнения приложения, заданным на уровне фреймворка. На платформе. Именно от...