Продолжая разбираться с In-Memory СУБД Tarantool и Arenadata Grid, сегодня рассмотрим, как эти резидентные базы данных интегрируются с Apache Kafka. Читайте в нашей статье, что такое коннекторы и процессоры, а также как записать в топик Кафка сообщение, SQL-запрос или часть таблицы.
Arenadata Grid и Apache Kafka: коннектор + процессоры
Напомним, что Tarantool, который лежит в основе Arenadata Grid, представляет собой сервер приложений на языке Lua, интегрированный с резидентной СУБД. При этом In-Memory движок базы данных хранит все в оперативной памяти, а дисковый движок эффективно записывает данные на жесткий диск, используя журнально-структурированные деревья и разбиение на диапазоны [1]. Tarantool и Arenadata Grid поддерживают потоковую обработку данных (stream processing). В частности, интеграция с Apache Kafka для чтения и записи сообщений из топиков реализована с помощью специальных процессоров (обработчиков) и коннектора.
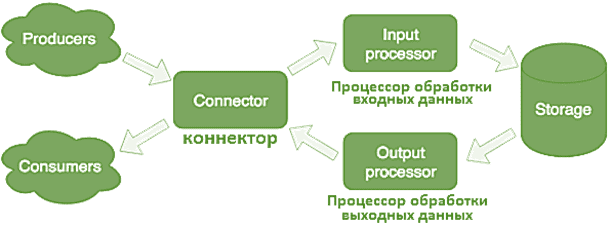
Коннектор связывает In-Memory СУБД с внешними системами, в т.ч. Apache Kafka: принимает запросы, делает парсинг и отправляет информацию в процессор обработки входных данных (input processor). Tarantool поддерживает протоколы HTTP и SOAP, а также работу с топиками Apache Kafka. Если в результате парсинга запроса получена ошибка, коннектор вернет ее. При успешной обработке запроса коннектор сообщит об этом, даже если последующая его обработка будет неудачной и возникнет ошибка. Это позволяет работать с системами, которые не повторяют запросы или, наоборот, делают это слишком настойчиво. Чтобы не потерять данные, используется ремонтная очередь, в которую сперва попадает запрос и удаляется из нее после успешной обработки [2].
В Arenadata Grid коннектор к Кафка (adg_kafka_connector) включает в себя публичные методы отправки и получения сообщений: send_messages_to_kafka(topic_name, messages, opts) и get_messages_from_kafka соответственно. Также коннектор содержит метод для передачи метрик в систему их сбора get_metric, который возвращает набор значений в формате JSON. Еще в состав коннектора входят Kafka producer и Kafka consumer, каждый со своим набором публичных и приватных методов для отправки и получения сообщений из топиков Кафка [3].
Зачем нужны процессоры обработки данных: читаем и пишем Big Data в топики Кафка
Процессор обработки входных данных используется для преобразования и обработки информации из внешних систем, в т.ч. Apache Kafka. Он содержит публичные и приватные методы для получения сообщений из топиков Кафка и данных в форматах AVRO и CSV [3]. Сперва Input processor классифицирует все полученные данные по характерным признакам и вызывает подходящие обработчики – программный код на языке Lua, запускаемый в изолированной песочнице, чтобы не повредить работающую систему. Здесь данные могут быть трансформированы с помощью произвольного количества задач, реализующих требуемые преобразования. Песочница поддерживает запросы на чтение, изменение и добавление данных, а также агрегацию результатов, в т.ч. MapReduce [2].
Процессор обработки выходных данных (Output processor) применяется для преобразования и обработки данных, которые следует отправить во внешние системы, в т.ч. Apache Kafka. Таким образом, Output processor используется, если о поступлении новых данных следует оповестить внешних потребителей. Когда данные сохранены, они могут передаваться в отдельный обработчик, например, для преобразования к виду, который требует потребитель. После этого данные передаются в коннектор для отправки. Здесь тоже используется ремонтная очередь: если запрос не принят, можно вручную повторить попытку позже [2].
В Arenadata Grid выходной процессор также содержит публичные методы для отправки через коннектор adg_kafka_connector в топик Кафка как единичного сообщения в формате «ключ-значение» (key-value), так и целого набора записей: send_simple_msg_to_kafka(topic_name, key, value) и send_messages_to_kafka(topic_name, messages, opts) соответственно. А, поскольку, Arenadata Grid поддерживает позиционируется как мощная СУБД для больших данных, она позволяет так отправлять в Apache Kafka произвольные SQL-запросы и строки из конкретной таблицы через коннектор adg_kafka_connector с помощью методов send_query_to_kafka(topic_name, query, opts) и send_table_to_kafka(topic_name, table, filter, opts) соответственно [5].
Завтра мы продолжим рассматривать Arenadata Grid и Tarantool, разберем несколько интересных примеров внедрения этих Big Data систем, а также поговорим про основные недостатки IMDB-СУБД. Также в следующей статье поговорим про интеграцию Apache Kafka c Greenplum на примере Arenadata DB. А как именно интегрировать Apache Kafka с внешними источниками и организовать потоковую обработку Big Data, вы узнаете на наших практических курсах по Кафка в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-профессионалов (менеджеров, архитекторов, инженеров, администраторов, аналитиков и Data Scientist’ов) «Школа Больших Данных» в Москве:
Источники
- https://www.tarantool.io/ru/doc/1.10/intro/
- https://habr.com/ru/company/mailru/blog/466155/]
- https://docs.arenadata.io/adg/Roles/adg_kafka_connector/index.html
- https://docs.arenadata.io/adg/v2.3.1/Roles/adg_input_processor/index.html
- https://docs.arenadata.io/adg/v2.3.1/Roles/adg_output_processor/index.html

