Как мы уже писали, в Apache Kafka Streams таблица и поток данных – это базовые и взаимозаменяемые понятия. Сегодня поговорим о том, как работать с этими объектами Big Data с помощью внутренних средств Кафка Стримс, используя готовые методы высокоуровневого языка DSL и низкоуровневый API-интерфейс для распределенной обработки потоковых данных в рамках собственной топологии. Также в эту статью мы включили для вас некоторые примеры программного кода с комментариями.
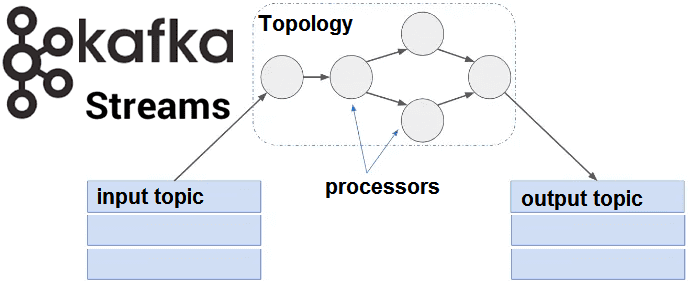
Как реализовать топологию потоковой обработки в Apache Kafka Streams
Существуют 2 способа определения топологии потоковой обработки Big Data в контексте логической абстракции программного кода, о которой мы рассказывали здесь [1]:
- высокоуровневый язык Kafka Streams (DSL, Domain Specific Language), реализующий типовые операции преобразования данных (map, filter, join, aggregation);
- низкоуровневый API-интерфейс обработчика (Processor API), который позволяет разработчику определять и подключать пользовательские обработчики, а также взаимодействовать с хранилищами состояний (state stores).
Именно DSL оперирует следующими высокоуровневыми понятиями:
- KStream – аналог потока (Stream) в Кафка, абстракция потока записей, каждая из которых представляет собой простую пару ключ-значение в неограниченном наборе данных [2];
- KTable– аналог таблицы (Table) в Кафка, абстракция потока изменений (changelog stream), где каждая запись считается вставкой (Insert) или обновлением (Update) в зависимости от существования ключа, поскольку любая существующая строка с тем же ключом будет перезаписана [2];
- GlobalKTable– реплицированные на локальный узел данные с целью сокращения затрат на создание промежуточных топиков и хранение данных в них. Объекты GlobalKTable реплицируют все секции на каждый из узлов приложения Kafka Streams, обеспечивая доступность записи независимо от принадлежности ее ключа к разделу топика Кафка (topic partition) [3].
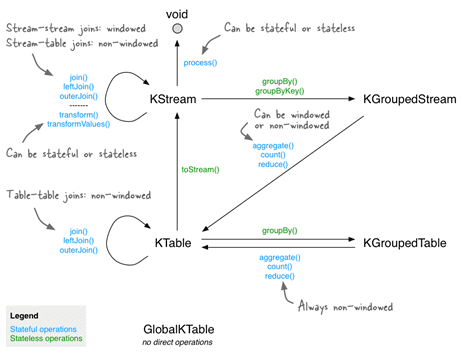
Напомним, что в Kafka Streams таблицу можно явно преобразовывать в поток изменений (changelog stream) с помощью функции KTable#toStream(). Для работы со всеми вышеуказанными понятиями высокоуровневый DSL Kafka Streams предоставляет готовые методы с функциональным стилем.
Например, ниже показаны строки кода по применению метода преобразования строчных символов объекта kStream в заглавные и отправке результатов в выходной топик (topic) Кафка [2].
val upperCaseKStream = kStream.mapValues(_.toUpperCase);
upperCaseKStream.to(«OutTopic») //sending data to out topic
Аналогичный код с использованием API-интерфейса обработчика (Processor API) будет существенно длиннее, поскольку в этом случае разработчику необходимо самостоятельно объявлять переменные и инициировать методы. Однако, именно с помощью API-интерфейса обработчика можно реализовать уникальную топологию обработки информационных потоков, самостоятельно определив узлы (source, stream и sink-processors) и сложную логику их программного поведения. Также можно ввести в эту топологию хранилища состояний (state store) и добавить обработчики-источники данных из топиков Kafka для генерации входных потоков в топологию и обработчики-приемники для отправки выходных потоков в нужные топики Кафка [4].
Ниже показан пример реализации такой топологии, где
- узел обработчика-источника (Source) добавляется в топологию с помощью метода addSource, и в него подается один топик Kafka (source-topic);
- узел обычного обработчика потока (Process) с ранее предопределенным программистом методом подсчета слов во входном потоке данных (WordCountProcessor) добавляется в качестве нижестоящего узла для обработчика-источника (Source) с помощью метода addProcessor.
- постоянное хранилище состояний значения ключа создается и связывается с узлом Process с помощью ранее предопределенной переменной countStoreSupplier;
- наконец, чтобы завершить топологию, метод addSink добавляет узел обработчика-приемника, принимая узел Process в качестве вышестоящего и записывая его в отдельный топик-приемник Кафка. Возможно динамическое определение топика Kafka для сохранения каждой полученной записи от вышестоящего узла.

Отметим, что средствами DSL также можно определить топологию, однако это будет реализовано не в таком явном и понятном виде, как с помощью Processor API [4]. Таким образом, низкоуровневый API-интерфейс обработчика предоставляет клиенту доступ к потоковым данным для выполнения бизнес-логики на входящем потоке данных и отправки результата. Там, где высокоуровневый DSL позволяет применять готовые методы с функциональным стилем, низкоуровневый процессор API предоставляет гибкость для реализации логики обработки в соответствии с бизнес-потребностями [2]. Примеры DSL-методов по группировке данных в определенном временном промежутке смотрите в нашей следующей статье.
Еще больше тонкостей по работе с Apache Kafka Streams API для быстрой обработки больших данных в режиме онлайн на специализированных курсах для руководителей, архитекторов, инженеров, администраторов, аналитиков Big Data и Data Scientist’ов в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
Источники

