Завершая сравнение структур данных Apache Spark, сегодня мы рассмотрим, в каких случаях разработчику Big Data стоит выбирать датафрейм (DataFrame), датасет (DataSet) или RDD и почему. Также мы приведем практический примеры и сценарии использования (use cases) этих программных абстракций, важных при разработке систем и сервисов по интерактивной аналитике больших данных с помощью Spark SQL.
Кэширование разных структур данных Apache Spark
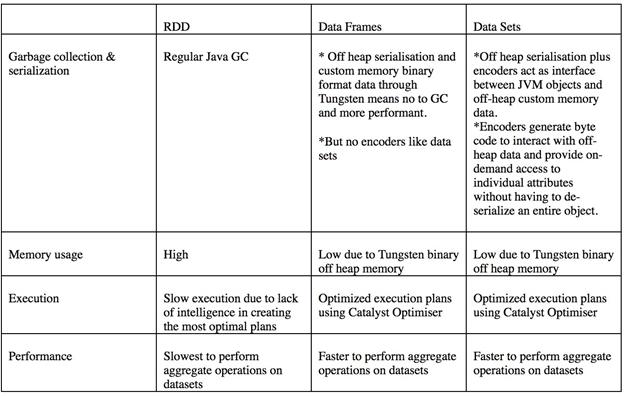
Прежде чем перейти к обоснованию выбора той или иной структуры данных Apache Spark, рассмотрим, как выполняется их кэширование, т.к. это влияет на процесс их использования. Мы уже отмечали, что из-за особенностей сериализации распределенные коллекции данных (RDD) обрабатываются медленнее табличных наборов данных (DataFrame и DataSet). Поэтому для ускорения работы с RDD имеет смысл кэшировать данные в следующих случаях [1]:
- итеративные циклы, которые часто встречаются в алгоритмах машинного обучения (Machine Learning);
- многократный вызов в рамках одного приложения или задания;
- начальная стоимость регенерации набора данных высока, особенно после сложных трансформаций в виде множества операций map и фильтрации по различным условиям;
- высока вероятность отказа работающей задачи (worker).
Как правило, RDD кэшируется с помощью алгоритмов LRU (Least recently used), когда в первую очередь вытесняется элемент, неиспользованный дольше всех. Это происходит каждый раз, когда возникает нагрузка на память. При этом стоит выбирать следующие варианты кэширования [1]:
- память (Native Caching) – кэширование на основе памяти хорошо работает для небольших наборов данных;
- кэширование хранилища без сохранения состояния, поддерживаемый каким-либо видом постоянного хранилища. Первый доступ может быть медленным, но последующие обращения выполняются гораздо быстрее. Такая ситуация возникает, когда к Spark подключены внешние провайдеры, например, виртуальная распределенная файловая система Alluxeo или распределенная база данных и платформа для кэширования, Apache Ignite и т. д.
- диск (кеширование на основе HDFS), что дешево и быстрее, если используются SSD-накопители. Однако, в случае сбоя кластера, состояние и данные будут потеряны.
- Память и диск, объединяющий первый и третий подходы, что позволяет сериализовать данные в байтовый массив и сэкономить место за счет дополнительных затрат на сериализацию и обратный ей процесс (десериализацию).
Подобной проблемы выбора параметров кэширования не возникает при работе DataSet и DataFrame благодаря Tungsten, который явно управляет памятью и динамически генерирует байт-код для оценки выражений. Из-за динамической генерации байт-кода с сериализованными данными можно проводить различные операции, не выполняя десериализации всего объекта [2]. Например, при работе со счетчиками или ассоциативными массивами [1].
Когда и что использовать: выбор между RDD, DataFrame и DataSet
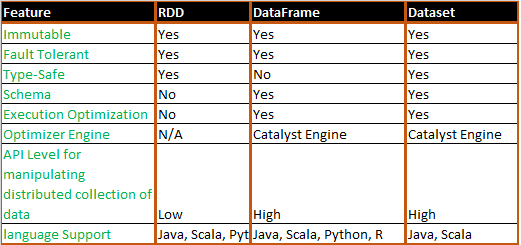
Учитывая ранее описанную специфику разных структур данных Apache Spark, важных с точки зрения разработчика Big Data программ, можно выделить следующие сценарии использования (use cases) для RDD, DataFrame и DataSet.
Итак, работать с RDD целесообразно, если [3]:
- требуется выполнить низкоуровневые преобразования и действия, контролируя набор данных;
- данные неструктурированы, например, потоки медиаинформации или текста;
- объем данных не слишком велик и не требуется строго типизированный код [1];
- необходимо манипулировать данными с помощью функциональных программных конструкций, а не выражений, специфичных для предметной области, т.е. предполагается использовать функциональный стиль программирования, а не доменно-ориентированную разработку.
- необходимо работать с языками программирования Python и R;
- есть возможность отказаться от некоторых преимуществ оптимизации и производительности, доступных в DataFrame и Dataset для структурированных и полуструктурированных данных.
В свою очередь, концепции DataSet и DataFrame рационально использовать в следующих случаях [3]:
- необходима высокая скорость обработки данных;
- нужна богатая семантика, высокоуровневые абстракции и специфичные для домена API;
- обработка требует высокоуровневых выражений, фильтров, map-операций, агрегации, средних значений, суммы, SQL-запросов, столбцового доступа и использования лямбда-функций для полуструктурированных данных;
- используется схема данных или столбцовые форматы (Parquet, ORC), где обработка или доступ к нужным атрибутам выполняется по имени или столбцу;
- нужна быстрая и избирательная работа с некоторыми атрибутами, например, счетчиками, ассоциативными массивами [1];
- необходимо унифицировать и упростить API-интерфейсы в библиотеках Apache
Стоит работать с Dataset, если необходимо получить более высокую степень безопасности типов во время компиляции, иметь типизированные JVM-объекты, а также использовать преимущества оптимизации Catalyst и эффективную генерацию кода в Tungsten. Именно эту структуру данных лучше всего использовать при работе с информацией в сложных предметных областях, например, финансы или телекоммуникации, когда необходимо оперировать с множеством объектов, выполняя над ними сложные бизнес-операции [1]. Подробнее об SQL-оптимизаторе Catalyst мы рассказываем здесь.
Таким образом, выбирая между структурами данных Apache Spark, следует помнить, что RDD предлагает низкоуровневую функциональность и контроль, а DataSet и DataFrame позволяют настраивать вид и структуру, предлагая высокоуровневые и специфичные для домена операции с экономией места на диске и в памяти [3].
В следующей статье мы расскажем подробнее о работе оптимизатора Apache Spark SQL – Catalyst. А получить реальный опыт прикладной работы с этим фреймворком интерактивной аналитики больших данных вы сможете на нашем практическом курсе SPARK2: Анализ данных с Apache Spark в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве.
Источники
- https://medium.com/@shashankbaravani/an-overview-of-spark-performance-optimisations-c6e7eda3201
- https://data-flair.training/blog/apache-spark-rdd-vs-DataFrame-vs-DataSet/
- https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-DataFrames-and-DataSets.html

