MapReduce можно назвать основой Big Data, т.к. именно данная технология позволяет обрабатывать огромные массивы информации параллельно в распределенных кластерах. Эту вычислительную модель поддерживают множество различных коммерческих и свободных продуктов: Apache Hadoop, Spark, Greenplum, Hive, MongoDB, Phoenix, DryadLINQ и прочие Big Data фреймворки и библиотеки, написанные на разных языках программирования [1]. Сегодня мы рассмотрим главные достоинства и недостатки этой технологии и поговорим о том, как ведущие Big Data разработчики пытаются обойти ее основные проблемы.
Чем хорош MapReduce: основные преимущества модели
Ключевыми достоинствами MapReduce являются следующие [2]:
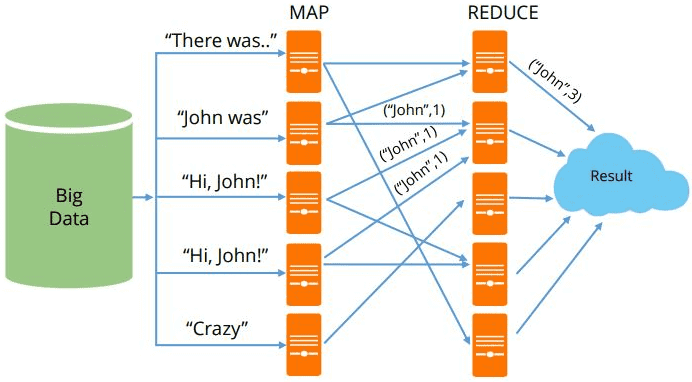
- возможность распределенного выполнения операций предварительной обработки (map) и свертки (reduce) большого объема данных. При этом функции map работают независимо друг от друга и могут выполняться параллельно на разных узлах кластера. Отметим, что на практике количество одновременно исполняемых функций map ограничивается источником входных данных и числом используемых процессоров. Аналогичным образом множество узлов производят свертку (reduce) после того, как каждый из них обработал все результаты функции map с одним конкретным значением ключа.
- быстрота обработки больших объёмов данных за счет распределения операций по вышеописанному принципу. В частности, всего за пару часов MapReduce может отсортировать целый петабайт данных.
- отказоустойчивость и оперативное восстановления после сбоев: при отказе рабочего узла, производящего операцию map или reduce, его работа автоматически передается другому рабочему узлу в случае доступности входных данных для проводимой операции.

Недостатки и альтернативы Big Data решений
Прежде всего, отметим, что для первой версии фреймворка MapReduce, реализованного в Apache Hadoop v1.0, были характерны следующие ограничения [3]:
- предел масштабируемости кластера Apache Hadoop: не более 4K вычислительных узлов и около 40K параллельных заданий;
- сильная связанностьфреймворка распределенных вычислений и клиентских библиотек, реализующих распределенный алгоритм;
- наличие единичных точек отказа и невозможность использования в средах с высокими требованиями к надежности;
- проблемы версионной совместимости: необходимость единовременного обновления всех вычислительных узлов кластера при обновлении платформы Hadoop (установке новой версии или пакета обновлений).
Эти ограничения были устранены в новой версии MapReduce 2.0, выпущенной в 2012 году, за счет изменений в менеджере ресурсов (ResourceManager) и планировщике-координаторе приложений ApplicationMaster, а также появления YARN (Yet Another Resource Negotiator). Этот программный фреймворк выполнения распределенных приложений предоставляет компоненты и API для разработки распределенных приложений различных типов, обеспечивая распределение ресурсов в ответ на запросы от выполняемых приложений и ответственность за отслеживанием статуса их выполнения [3].
В частности, ответственность по управлению ресурсами кластера лежит на ResourceManager, а по планированию/координации жизненного цикла приложений – на ApplicationMaster. При этом каждый вычислительный узел разделен на произвольное количество контейнеров Container, содержащих предопределенное количество ресурсов: CPU, RAM и т.д., за которыми наблюдает менеджер узла (NodeManager) [3].

Тем не менее, эти нововведения не устранили недостатки MapReduce, обусловленные архитектурными особенностями этой вычислительной модели:
- недостаточно высокая производительность – классическая технология, в частности, реализованная в ядре Apache Hadoop, обрабатывает данные ациклично в пакетном режиме. При этом функции Reduce не запустятся до завершения всех процессов Map. Все операции проходят по циклу чтение-запись с жесткого диска, что влечет задержки (latency) в обработке информации.
- ограниченность применения – продолжая вышеотмеченный недостаток, высокие задержки распределенных вычислений, приемлемые в пакетном режиме обработки, не позволяют использовать классический MapReduce для потоковой обработки в режиме реального времени, повторяющихся запросов и итеративных алгоритмов на одном и том же датасете, как в задачах машинного обучения (Machine Learning). Для решения этой проблемы, свойственной Apache Hadoop, были созданы другие Big Data фреймворки, в частности, Apache Spark и Flink.
Например, в отличие от классического обработчика ядра Apache Hadoop c двухуровневой концепцией MapReduce на базе дискового хранилища, Spark использует специализированные примитивы для рекуррентной обработки в оперативной памяти. Благодаря этому многие задачи вычисляются значительно быстрее. Например, многократный доступ к загруженным в память пользовательским данным позволяет эффективно работать с алгоритмами Machine Learning.
Таким образом, достоинства и недостатки MapReduce обусловливают специфику прикладного использования этой вычислительной модели. В частности, эта технология не применяется в чистом виде в потоковых Big Data системах, где требуется оперативно обрабатывать большие объемы непрерывно поступающей информации в режиме реального времени. На практике такое встречается в платформах Internet of Things. Однако, если требование быстрой обработки данных не является критичным и бизнес-приложению подходит пакетный режим работы с данными, как, например, в ETL-системах или индексировании веб-страниц, MapReduce справится с такими задачами на отлично.
Источники

