Чтобы максимально приблизить обучение Airflow к практической работе дата-инженера, сегодня мы рассмотрим, какие еще есть альтернативы для оркестрации ETL-процессов и конвейеров обработки больших данных. Читайте далее, что такое Luigi, Argo, MLFlow и KubeFlow, где и как они используются, а также почему Apache Airflow все равно остается лучшим инструментом для оркестрации заданий в области Big Data.
Еще раз об оркестрации задач в Big Data и Machine Learning: что это такое и зачем нужно
Обычно развитие data—driven инициатив начинается с ручного управления задачами. Например, для машинного обучения (Machine Learning) это будут процессы очистки данных, обучения моделей, отслеживание результатов и развертывание решений на рабочем сервере (production). Эти процедуры растут и усложняются по мере увеличения команды и продвижения самого продукта. В частности, растет количество повторяющихся шагов, повышается зависимость задач друг от друга и степень их важности (критичность) для бизнеса. Таким образом, появляется целый конвейер (pipeline) задач, которые нужно запускать с некоторой периодичностью в определенном порядке. Далее такой data pipeline становится еще сложнее, превращаясь в сеть задач или направленный ациклический граф (DAG, Direct Acyclic Graph).
Инструменты оркестровки рабочих процессов (workflow) позволяют определять DAG, показывая взаимозависимость входящих в него задач. Далее эти задачи запускаются по нужному расписанию в правильном порядке с отслеживанием прогресса и отправкой уведомлений о возникших сбоях. Например, в состав data pipeline’а могут входить такие задачи, как считывание сообщений из топиков Apache Kafka, их обогащение историческими данными из HDFS с помощью Spark или Hive. При этом периодичность и порядок запуска задач может изменяться в зависимости от бизнес-логики, о чем мы рассказывали здесь на примере оптимизации накладных расходов в управлении data pipeline’ами с помощью Apache AirFlow в Airbnb. С учетом популяризации DataOps-идей, суть любого инструмента оркестровки сводится к обеспечению централизованных, повторяемых, воспроизводимых и эффективных рабочих процессов. Таким образом, средство workflow-оркестрации выступает в качестве единого центра управления для всех автоматизированных задач. В этом контексте на конец 2020 года наиболее известными и часто используемыми оркестраторами для Big Data и Machine Learning процессов являются следующие 5 фреймворков, которые мы рассмотрим далее.
Apache Airflow и еще 4 средства оркестровки Data Pipiline’ов
Сегодня наиболее популярным в области Big Data считается Apache Airflow – система управления рабочими процессами с открытым исходным кодом, изначально созданная в Airbnb и позже доступная под лицензией Apache 2.0. О принципах работы, достоинствах и недостатках этого фреймворка мы подробно рассказывали в этом материале.
Наиболее известной альтернативой Apache Airflow можно назвать Luigi – библиотеку Python, которую можно установить с помощью инструментов управления пакетами, таких как pip и conda., Luigi также предназначен для управления рабочими процессами посредством их визуализации в виде DAG-конвейера. Этот фреймворк проще в эксплуатации, чем Airflow, но имеет меньше функций и больше ограничений [1], о которых мы поговорим в следующий раз.
Если Apache AirFlow и Luigi воплощают идеи DataOps, облегчая работу инженера данных с конвейерами их обработки, то Argo и KubeFlow ближе к DevOps-инструментам, т.к. тесно связаны с технологиями контейнеризации. В частности, Argo представляет собой расширение Kubernetes, где каждая задача запускается как отдельный модуль этой платформы контейнеризации. В отличие от Apache AirFlow и Luigi, Argo использует YAML, а не Python для определения DAG-задач. Argo предназначен для оркестровки любых задач в экосистеме Kubernetes. А основанный на нем Kubeflow фокусируется на операциях машинного обучения, таких как отслеживание экспериментов, настройка гиперпараметров и развертыванию модели Machine Learning в production. Еще одним отличием Kubeflow от Argo является язык определения задач: в Argo это YAML, а в Kubeflow – Python.
Таким образом, Kubeflow, как и MLFlow можно отнести к инструментарию MLOps для комплексного и автоматизированного управления жизненным циклом систем Machine Learning. При этом Kubeflow полагается на Kubernetes, а MLFlow – это библиотека Python, которая помогает добавить отслеживание экспериментов в существующий код машинного обучения. Kubeflow позволяет создать полноценный DAG, каждая задача которого представляет собой модуль Kubernetes. MLFlow имеет встроенные функции для развертывания ML-моделей scikit-learn в Amazon Sagemaker или Azure ML. Подробнее о технической реализации MLOps-идей на облачных платформах и других особенностях внедрения этого подхода мы писали здесь.
Резюмируя сходства и отличия рассмотренных инструментов оркестрации рабочих процессов для задач обработки больших данных и машинного обучения, отметим, что они значительно отличаются друг от друга и не могут считаться непосредственными конкурентами. При том, что основным критерием выбора средства оркестровки является его основное назначение, указанное выше, и ключевые функциональные возможности, альтернативные варианты также можно сравнить между собой по следующим критериям [2]:
- зрелость, выраженная в виде зависимости возраста проекта от количества исправлений и коммитов;
- популярность как степень распространения на практике и количество звезд на GitHub;
- простота установки, настройки и эксплуатации;
- глубина специализации и уровень адаптируемости;
- язык программирования как основной способ взаимодействия с фреймворком.
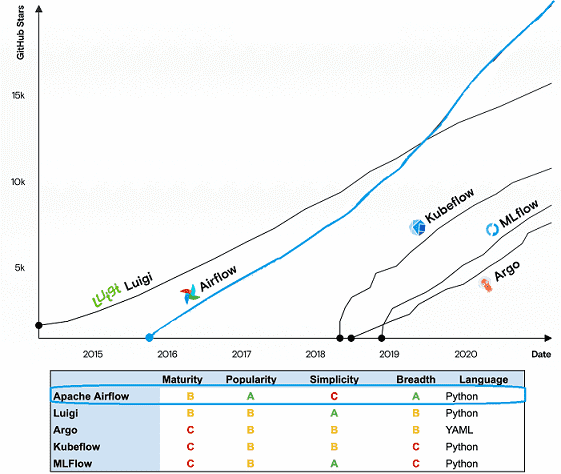
По этим критериям позицию лидера занимает Apache AirFlow, а на втором месте Luigi. Завтра мы поговорим о сходствах и различиях этих систем. Читайте в нашей новой статье еще про одну альтернативу AirFlow — оркестратор Apache Hop с наглядным GUI.
А узнать особенности администрирования и эксплуатации Apache Airflow в production на реальных проектах цифровизации частного бизнеса, а также государственных и муниципальных предприятий, вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
1. https://www.astronomer.io/guides/airflow-vs-luigi/
2. https://www.datarevenue.com/en-blog/airflow-vs-luigi-vs-argo-vs-mlflow-vs-kubeflow

