
Продолжая говорить про обучение Airflow, сегодня мы рассмотрим ключевые преимущества и основные проблемы этой библиотеки для автоматизации часто повторяющихся batch-задач обработки больших данных (Big Data). Также мы собрали для вас пару полезных советов, как обойти некоторые ограничения Airflow на примере кейсов из Mail.ru, IVI и АльфаСтрахования.
Чем хорош Apache AirFlow: главные плюсы
Проанализировав прикладное назначение и функциональные возможности Apache Airflow, можно сделать выводы, что главными положительными качествами этого фреймворка для разработки, планирования и мониторинга пакетных процессов работы с большими данными являются следующие:
- небольшой, но полноценный инструментарий создания процессов обработки данных и управления ими – 3 вида операторов (сенсоры, обработчики и трансферы), расписание запусков для каждой цепочки задач, логгирование сбоев [1];
- графический веб-интерфейсдля создания конвейеров данных (data pipeline), который обеспечивает относительно низкий порог входа в технологию, позволяя работать с Airflow не только инженеру данных (Data Engineer), но и аналитику, разработчику, администратору и DevOps-инженеру. Пользователь может наглядно отслеживать жизненный цикл данных в цепочках связанных задач, представленных в виде направленного ациклического графа (Directed Acyclic Graph) [2].
- Расширяемый REST API, который относительно легко интегрировать Airflow в существующий ИТ-ландшафт корпоративной инфраструктуры и гибко настраивать конвейеры данных, например, передавать POST-параметры в DAG [3].
Data Pipeline на Apache AirFlow и Arenadata Hadoop
Код курса
ADH-AIR
Ближайшая дата курса
по запросу
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
- Программный код на Python, который считается относительно простым языком для освоения и профессиональным стандартом де-факто для современного специалиста в области Big Data и Data Science: инженера, аналитика, разработчика больших данных и специалиста по машинному обучению [4].
- Интеграция со множеством источников и сервисов – базы данных (MySQL, PostgreSQL, DynamoDB, Hive), Big Data хранилища (HDFS, Amazon S3) и облачные платформ (Google Cloud Platform, Amazon Web Services, Microsoft Azure) [2].
- Наличие собственного репозитория метаданных на базе библиотеки SqlAlchemy, где хранятся состояния задач, DAG’ов, глобальные переменные и пр. [5].
- Масштабируемость за счет модульной архитектуры и очереди сообщений для неограниченного числа DAG’ов [5].
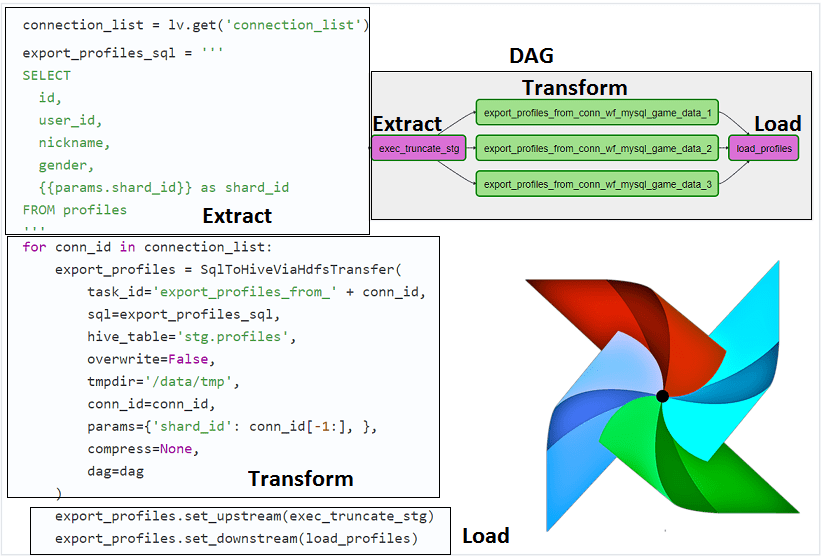
Ключевые ограничения и способы их обхода
Обратной стороной вышеотмеченных достоинств являются следующие недостатки:
- наличие неявных зависимостей при установке, например, дополнительные пакеты типа greenlet, gevent, cryptography и пр. усложняют быстрое конфигурирование этого фреймворка [5];
- большие накладные расходы (временная задержка 5-10 секунд) на постановку DAG’ов в очередь и приоритизацию задач при запуске [4];
- необходимость наличия свободного слота в пуле задач и рабочего экземпляра планировщика. Например, Data Engineer’ы компании Mail.ru выделяют сенсоры (операторы для извлечения данных, операция Extract в ETL-процессе) в отдельный пул, чтобы таким образом контролировать количество и приоретизировать их, сокращая общую временную задержку (latency) [4];
- пост-фактум оповещения о сбоях в конвейере данных, в частности, в интерфейсе Airflow логи появятся только после того, как задание, к примеру, Spark-job, отработано. Поэтому следить в режиме онлайн, как выполняется data pipeline, приходится из других мест, например, веб-интерфейса YARN. Именно такое решение по работе с Apache Spark и Airflow было принято в онлайн-кинотеатре IVI [3].
Data Pipeline на Apache Airflow
Код курса
AIRF
Ближайшая дата курса
22 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
- Разделение по операторам — каждый оператор Airflow исполняется в своем python-интерпретаторе. Файл, который создается для определения DAG – это не просто скрипт, который обрабатывает какие-то данные, а объект. В процессе выполнения задачи DAG не могут пересекаться, так как они выполняются на разных объектах и в разное время. При этом на практике иногда возникает потребности, чтобы несколько операторов Airflow могли выполняться в одном Spark-контексте над общим пространством dataframe’ов. Реализовать это можно с помощью Apache Livy – REST-API сервиса для взаимодействия с кластером Spark, как сделано в компании АльфаСтрахование [6], о чем мы подробнее рассказываем здесь.
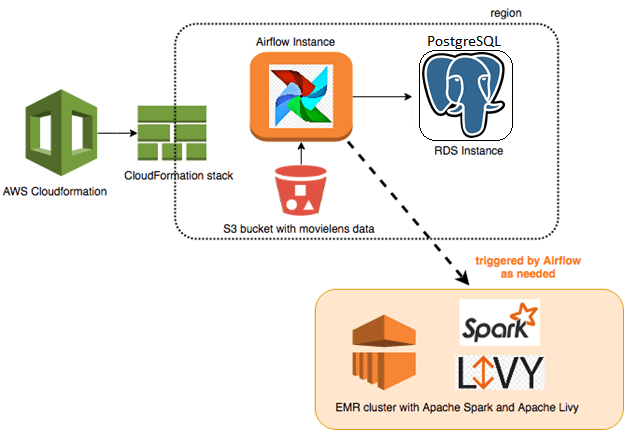
В следующей статье мы рассмотрим, как реализовать DevOps-подход, развернув эйрфлоу в кластере Kubernetes. Более подробно про ограничения Apache AirFlow и способы борьбы с ними в production читайте в нашем новом материале. А как применять на практике преимущества Apache AirFlow со Spark и обойти его недостатки для эффективного управления большими данными, вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:

