В этой статье мы поговорим про Apache AirFlow — эффективный инструмент для пакетных ETL-задач при работе с большими данными (Big Data): что это такое, как работает и чем полезен для инженера данных (Data Engineer). Также рассмотрим несколько практических примеров реального использования этой библиотеки для разработки, планирования и мониторинга batch-процессов.
Что такое ETL и при чем здесь Apache AirFlow
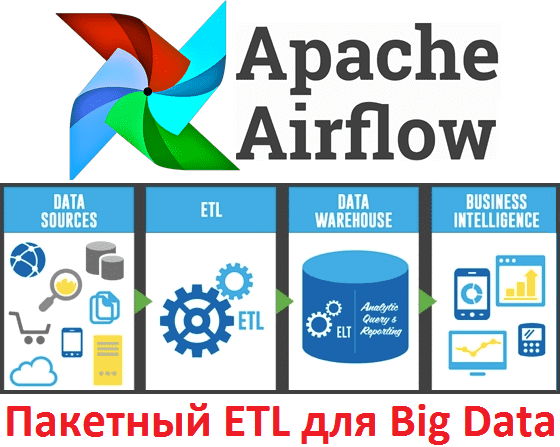
Процессы ETL (Extract, Transform, Load) являются неотъемлемой частью современных систем бизнес-аналитики (BI, Business Intelligence) и используются для интеграции множества корпоративных информационных систем с целью унификации и анализа хранимых в них данных [1]. Можно сказать, что сегодня ETL – это обязательный компонент корпоративной инфраструктуры на базе технологий Big Data, когда исходные («сырые») данные превращаются в информацию, пригодную для бизнес-анализа. ETL включает следующие этапы:
- извлечение данных (Extract) из различных источников (пользовательские и системные логи, реляционные СУБД, внешние датасеты, например, из соцсетей и прочих веб-сайтов);
- преобразование (Transform), когда к информации применяются различные операции бизнес-логики — фильтрация, группировка и агрегирование, чтобы преобразовать сырые данные в готовый к анализу датасет;
- загрузка (Load) – отправка обработанной информации в место конечного использования – озеро данных (Data Lake), СУБД, витрина данных, облачное приложение и т.д.
Существует множество готовых ETL-систем, реализующих функции загрузки информации в корпоративное хранилище данных, например, Informatica PowerCenter, Oracle Data Integrator, SAP Data Services, Oracle Warehouse Builder, Talend Open Studio, Pentaho и др. [1]. Однако, на практике, когда речь идет о больших объемах данных на высоких скоростях и уже существующей инфраструктуре Big Data, мало кто использует подобные коробочные решения. Например, в этом случае типичный набор задач может выглядеть так: создать выборку данных из HDFS и нескольких реляционных СУБД, обработать информацию и сохранить результат в таблицу Apache Hive. При этому каждый процесс может быть распараллелен с помощью, например, Apache Spark [2].
Таким образом, Data Engineer сталкивается с необходимостью создания собственных конвейеров доставки и обработки данных (data pipeline) с помощью специальных ETL-фреймворков. При выборе такого инструмента для Big Data стоит помнить про 2 типа обработки данных: потоковую (stream) и пакетную (batch). С задачами непрерывной маршрутизации и доставки потоковых данных успешно справляется Apache NiFi, о котором мы рассказывали здесь.
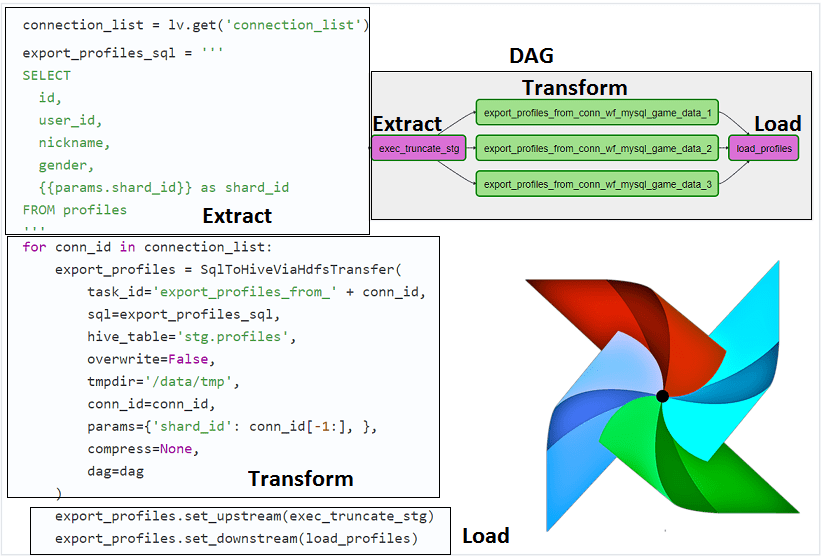
А для пакетных Big Data pipelines предназначен Apache Airflow — open-source набор библиотек для разработки, планирования и мониторинга рабочих процессов. Этот инструмент написан на языке программирования Python и позволяет создавать и настраивать цепочки задач как в визуальном режиме с помощью наглядного web-GUI, так и писать программный код Python. Задачи конвейера данных, которые надо выполнить в строго определенной последовательности по определенному расписанию в рамках единой смысловой цепочки, принято называть DAG (Directed Acyclic Graph, направленный ациклический граф) [3].
3 примера применения эйрфлоу в Big Data
При том, что AirFlow принято называть ETL-инструментом, он не является классической ETL-системой, а лишь помогает представить процесс извлечения-преобразования-загрузки данных в виде единого проекта на Python. При этом предоставляет возможность автоматизации управления DAG’ами, масштабирования задач и мониторинга их исполнения. Поэтому AirFlow широко используется для реализации ETL-процессов в Big Data системах различных прикладных областей.
Например, компания Mail.ru использует AirFlow для пакетных ETL-задач. Еще в 2017 году этот фреймворк обеспечивал ежедневную автоматизацию около 7 тысяч DAG’ов, от загрузки данных в корпоративное хранилище из множества разных источников (примерно 250 рахных СУБД), до организации витрин данных. В частности, почти 2,5 тысячи ELT-задач связаны с Data Lake на базе Apache Hadoop. При общей положительной оценке AirFlow, специалисты Mail.ru отмечают и его недостатки, в частности, большие накладные расходы (временная задержка 5-10 секунд) на [3]:
- постановку DAG’ов в очередь,
- приоритезицию задач при запуске;
- зависимость от наличия свободного слота в пуле и рабочего экземпляра планировщика задач.
С подобными проблемами столкнулся и онлайн-кинотеатр ivi, который используется Airflow для запуска и мониторинга Spark-приложений. Тем не менее, этот инструмент управления batch-процессами позволил оптимизировать управление конвейерами данных, гарантируя, что каждый data pipeline запускается точно по расписанию. А в случае сбоя информация об этом оперативно появится в веб-GUI, а саму цепочку задач можно быстро перезапустить одной кнопкой [4].
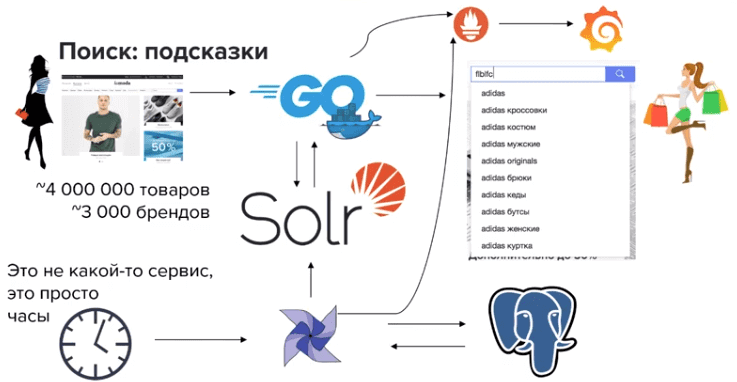
Также интересен опыт отечественного маркетплейса одежды и аксессуаров Lamoda. Ритейлер с помощью AirFlow реализовал на своем сайте сервис подсказок, который помогает пользователям найти нужную вещь среди 4 миллионов товаров и 3 тысяч брендов. Примечательно, что подсказки выводятся в зависимости от сезона, уровня продаж и предпочтений пользователей. В этом кейсе, помимо AirFlow, также используются другие инструменты стека Big Data и не только [5]:
- Apache Solr — платформа полнотекстового поиска с открытым исходным кодом;
- PostgreSQL — свободная объектно-реляционная система управления базами данных;
- Docker — программное обеспечение для автоматизации развёртывания и управления приложениями в средах с поддержкой контейнеризации;
- Grafana – многоплатформенное программное обеспечение с открытым исходным кодом для аналитики и интерактивной визуализации – диаграммы, графики и оповещения для Интернета при подключении к поддерживаемым источникам данных;
- Prometheus – бесплатное программное приложение для мониторинга событий, которое записывает метрики в реальном времени в базу данных временных рядов с использованием модели HTTP-запроса, гибкими запросами и оповещениями в режиме реального времени.
В следующей статье мы расскажем про ключевые преимущества и недостатки AirFlow. А технические подробности, как Data Engineer может применять этот инструмент для пакетных ETL-задач и других процессов эффективного управления данными, вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Источники
- https://chernobrovov.ru/articles/etl-chto-takoe-zachem-i-dlya-kogo.html
- https://habr.com/ru/company/alfastrah/blog/466017/
- https://habr.com/ru/company/mailru/blog/339392/
- https://habr.com/ru/company/ivi/blog/456630/
- https://www.youtube.com/watch?v=nY9pA02CoiI&list=PLgZXqi5nH1m2EfbrLLqnvg9rY1doSi4ko&index=31

