Что такое MSCK REPAIR TABLE в Apache Hive, зачем нужна эта команда, ее достоинства и недостатки, а также альтернативные варианты для задач пакетной дата-инженерии. Разбираем на примере конвейера обработки данных в ML-приложениях при работе с Data Lake.
Команда MSCK REPAIR TABLE в Apache Hive
В ML-приложениях особенно важно, как озеро данных (Data Lake) интегрируется в конвейеры обработки данных. Особенно, когда конвейер генерирует и сохраняет данные в озере, и на следующем этапе необходимо запросить их. В большинстве случаев генерируемые данные распределяются по разделам (партиционируются) и сопоставляются с внешними таблицами. Разделы могут быть основаны на типе модели, версии модели, датах, ключевых фичах и пр.
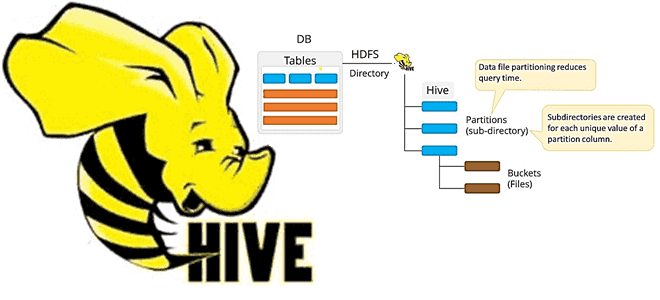
Сами данные при этом хранятся в озере данных, чаще всего на Hadoop HDFS или объектных хранилищах типа AWS S3. Таким образом, нужно обновить хранилище метаданных, например, Apache Hive, прежде чем запрашивать его. Напомним, Apache Hive представляет собой NoSQL-хранилище данных для выполнения пакетных запросов к большим наборам данных, хранящимся в Hadoop HDFS, с использованием средств SQL. Чаще всего именно хранилище метаданных Hive используется для хранения метаданных в вычислительном фреймворке Apache Spark, что мы описываем здесь. Однако, на больших объемах конвейер не сможет загрузить и управлять фильтром сортировки в памяти.
Рассмотрим ML-систему как направленный ациклический граф (DAG, Directed Acyclic Graph), узлами которого являются операторы: один узел загружает ML-модель, другой – загружает и фильтрует данные прогноза, третий – собирает отфильтрованные и/или прогнозные данные и пр. Отдельные узлы полностью не зависят от озера данных, а некоторым необходимо запускать SQL-запросы или приложения Spark для преобразования данных, созданных на предыдущих шагах.
Анализ данных с Apache Spark
Код курса
SPARK
Ближайшая дата курса
13 мая, 2024
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
На практике для обновления хранилища метаданных Hive чаще всего используется таблица восстановления msck. Она восстанавливает все разделы в каталоге таблицы и обновляет хранилище метаданных Hive. При создании таблицы с помощью предложения PARTITIONED BY разделы создаются и регистрируются в Hive MetaStore, что мы рассматриваем здесь. Однако, если партиционированная таблица создается на основе существующих данных, разделы не регистрируются автоматически в хранилище метаданных, для регистрации разделов необходимо запустить команду MSCK REPAIR TABLE. Если таблица кэшируется, команда очищает кэшированные данные таблицы и все зависимые от нее зависимости. Кэш будет неактивно заполнен при следующем обращении к таблице или зависимым данным.
По мере роста данных, появляются тысячи разделов и подразделов, эта команда становится очень медленной. В объектных хранилищах (AWS S3 или Google Cloud Storage) множество объектов и запросов заголовков в папках еще больше снижают скорость выполнения. Предположим, есть ежедневный прием данных в HDFS, откуда генерируются внешние таблицы Hive с разделами по дате. Следует ежедневно запускать таблицу восстановления MSCK REPAIR TABLE после загрузки нового раздела в папку HDFS, т.к. Hive хранит список разделов для каждой таблицы в своем хранилище метаданных. Когда новые разделы добавляются непосредственно в HDFS, хранилище метаданных и, следовательно, Hive не знает о них, если пользователь не запустит команду добавления новых разделов.
Таким образом, в Hive нужно передать новые добавленные разделы, причем с точки зрения современной дата-инженерии делать это следует автоматически. Однако, это не так просто из-за сбоев, повторных попыток отправки данных, разных графиков запуска и загрузки данных в озеро данных. В итоге задача сводится к следующим шагам:
- Сохранить или получить время последнего добавления разделов;
- Получить путь ко всем файлам, добавленным в папку верхнего уровня между 1-мы шагом и текущим моментом;
- Разделить отформатировать результаты в отдельные команды добавления разделов, учитывая возможность многоуровневых разделов;
- Просмотреть результат и запустить кластер с помощью Spark-задания.
Как это реализовать, рассмотрим далее.
Пример альтернативной реализации
Сохранить или получить время последнего добавления разделов можно с помощью перезаписи вставкой. Например, для Google Cloud Storage это может выглядеть так:
INSERT OVERWRITE DIRECTORY ‘gs://<your bucket name>/<some folder>’ ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ STORED AS TEXTFILE select CURRENT_TIMESTAMP;
Другой способ — использовать GCS-перехватчики или хуки, которые можно поместить в функцию и вызвать с помощью Python-оператора сразу после того, как оператор Spark в DAG используется для добавления разделов.
from airflow.providers.google.cloud.hooks.gcs import GCSHook Import datetime hook = GCSHook( google_cloud_storage_conn_id=<your connection id> ) with open(‘addpartitions.state’, ‘w’) as partitionfile: partitionfile.write(datetime.datetime.now().strftime(‘%Y-%m-%d’)) hook.upload(<your bucket>, <your folder>,’addpartitions.state’)
Получить список всех файлов, созданных с определенной даты можно также с помощью GCSHook, используя API list_by_timespan:
list_of_files = hook.list_by_timespan(<your bucket>,timespan_start=time_start, timespan_end=time_end, prefix=<path to the top folder of your table external folder >)
Переменная time_start – это время, сохраненное в последний раз на шаге 1, а time_end – это текущее время, now(), когда будут добавляться новые разделы. Прочитать файл можно также с помощью хука, получив результат в виде строки.
time_string = hook.download(<your bucket>, <path to the file where the time has been stored just after the last time partitions were added>).decode(“utf-8”) time_start = datetime.datetime.strptime(last_time_partitions_added_string, ‘%Y-%m-%d’) timespan_end = datetime.datetime.now()
Далее нужно удалить имена папок в соответствии с схемой разделов, например, префикс – это внешняя папка верхнего уровня, из которой начинаются многоуровневые разделы:
list_of_partitions = [x.split(prefix)[1].split(‘/’)[1:-1] for x in list_of_files]
Два вышеописанных шага входят в функцию, которая вызывается через Python-оператор. Возвращаемое значение функции, которое передается как python_callable в Python-операторе, автоматически сохраняется в XCom, что позволит получить это значение в любом месте после использования идентификатора задачи Python-операторв. Поэтому нужно просто вернуть list_of_partitions из функции.
get_partitions_to_add = PythonOperator(dag=dag,task_id=”get_partitions_do”,provide_context=True,python_callable=get_partitionstoadd_by_time_span,op_kwargs=args_dict,retries=0) def get_partitionstoadd_by_time_span: utc=pytz.UTC last_time_partitions_added_string = hook.download(<your bucket>, <path to the file where the time has been stored just after the last time partitions were added>).decode(“utf-8”) time_start = utc.localize(datetime.datetime.strptime(last_time_partitions_added_string,’%Y-%m-%d’).replace(hour=0,minute=0)) time_end = utc.localize(datetime.datetime.now().replace(hour=23,minute=59)) hook = GCSHook(google_cloud_storage_conn_id=<my connection id>) list_of_files = hook.list_by_timespan(bucket_name=<my bucket>,timespan_start=time_start, timespan_end=time_end, prefix=<top folder mapped to external table>) list_of_partitions = [x.split(prefix)[1].split(‘/’)[1:-1] for x in list_of_files] return list_of_partitions
Наконец, используя DataprocSubmitPySparkJobOperator, можно вызывать контекст Spark с помощью файла Python и запускать его в созданном кластере DataProc через озеро данных. Если файл Python использует какой-либо оператор импорта, такой как pyspark.sql, который не установлен в среде Composer/Airflow, DAG не будет компилироваться. Аналогично, если файл находится внутри самой папки DAG и упоминается в ней. В этом случае вам нужно поместить файл где-то еще в облаке и просто сопоставить его:
import sys from pyspark.sql import SparkSession import ast if __name__ == “__main__”: #print(sys.argv) list_of_partitions = sys.argv[1] list_of_partitions = ast.literal_eval(list_of_partitions) spark = SparkSession.builder.master(“yarn”).enableHiveSupport().getOrCreate() # and not for the coolest part for part in list_of_partitions: # I am assuming a table with following partition scheme #PARTITIONED BY (run date, modelname string, lastpredictdate date, lastpredicthr bigint) spark.sql(“ALTER TABLE youdb.yourtable ADD IF NOT EXISTS PARTITION(run=’” + part[0].split(‘=’)[1] + “‘, modelname=’” + part[1].split(‘=’)[1] + “‘, lastpredictdate=’” + part[2].split(‘=’)[1] + “‘, lastpredicthr=” + part[3].split(‘=’)[1] + “)” )
После сохранения этого кода в виде Python-файла, например, add_partitions.py, оператор Spark выглядит так:
run_spark_job = DataprocSubmitPySparkJobOperator(dag=dag,task_id=”add_partitions_do”,
#main=”{}/dags/yourdag/scripts/add_partitions.py”.format(<your composer bucket>), #”. This does not work if pyspark is not installed in airflow
main=”gs://<your bucket>/<some folder>/add_partitions.py”,
# note the get_partitions_do below. Its the task id of the get_partitions_to_add Operator
arguments= [“{{ task_instance.xcom_pull(task_ids=’get_partitions_do’) }}”],cluster_name=<your dataproc cluster>,region=<your dataproc region>,
# set_timestamp below is the task id of another PythonOperator which calls a function which returns a timestamp to help create a new job name every time
job_name=”addpartitions-” + “{{ task_instance.xcom_pull(task_ids=’set_timestamp’) }}”,gcp_conn_id=<your connection id>)
Главное действие происходит, когда spark.sql запускает команду ADD Partition в цикле for для каждого нового раздела, который нужно добавить. Именно здесь можно выполнить перезапись вставки, как упоминалось в первом шаге, включив эту строку после цикла for в файле add_partitions.py.
spark.sql(“INSERT OVERWRITE DIRECTORY ‘gs://<your bucket name>/<some folder>’ ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ STORED AS TEXTFILE select CURRENT_TIMESTAMP;” )
Описанное решение снизит время восстановления таблицы msck в несколько раз. Это огромный выигрыш, когда следующие шаги конвейера обработки данных ждут заполнения Hive Metastore, чтобы запрашивать последние прогнозы.
Узнайте больше практических примеров по работе с Apache Spark и Hive для эффективной аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Hadoop SQL администратор Hive
- Анализ данных с Apache Spark
- Интеграция Hadoop и NoSQL
- https://medium.com/@b.debanjan/using-airflow-and-spark-operator-to-add-partitions-to-hive-metastore-8fead452da5d
- https://docs.microsoft.com/ru-ru/azure/databricks/sql/language-manual/sql-ref-syntax-ddl-repair-table
- https://community.cloudera.com/t5/Support-Questions/MSCK-REPAIR-HIVE-EXTERNAL-TABLES/td-p/229066

