
Сегодня рассмотрим кейс международной ИТ-компании AppsFlyer, которая создает SaaS-решения для маркетинговой аналитики в режиме онлайн. В этой статье команда разработки аналитического продукта Data Locker делится опытом оптимизации ETL-приложений Apache Spark для снижения стоимости обработки данных и ускорения вычислений.
Предыстория: слишком много файлов в ETL-решении на Spark и AWS S3 в Data Locker
Чтобы понять, как команде Data Locker удалось повысить стабильность их продукта, снизить стоимость и время задержки доставки данных, сперва рассмотрим контекст проекта. Клиенты по всему миру отправляют данные в AppsFlyer (AF) с мобильных устройств, чтобы движок на базе Apache Spark выполнял атрибуцию и позволял просматривать агрегированные результаты на дэшбордах. Все полученные данные хранятся в одном месте – корпоративном озере (Data Lake).
Большинству клиентов достаточно агрегированных данных на дэшбордах, но некоторым требуются и исходные подробности каждого события, связанного с пользователями. Именно за это отвечает продукт Data Locker, который ежечасно генерирует отчеты в виде файлов в облачное объектное хранилище AWS S3 или Google Cloud Storage. Последовательность действий приложения Data Locker выглядит так:
- считать данные указанных клиентских приложений из озера;
- применить фильтры и преобразования, определяемые пользователем и связанные с управлением, например, соблюдение требований GDPR;
- сохранить полученный набор данных в клиентском каталоге в распределенной файловой системе в виде CSV-файлов одинакового размера не более 10000 строк.
Прежде всего при разработке такого ETL-приложения следует решить, как читать данные: для каждого клиента отдельно или все сразу. Подход «приложение для каждого клиента» более масштабируемый и обеспечивает лучшую изоляцию, но менее рентабелен. Если исходный файл содержит данные N клиентов, Spark читает его N раз, делая это для каждого файла. Поскольку исходные данные не группируются и не сортируются по клиенту, а сортируются только по идентификатору приложения, накладные расходы Data Locker для сотен клиентов с десятками тысяч приложений быстро становятся огромными и неуправляемыми.
Поэтому было решено прочитать все данные клиентов за один раз, сохранить их в памяти, а затем для каждого клиента:
- создать клиентский датафрейм путем, отфильтровав кэшированные датафреймы клиентских приложений;
- подсчитать строки клиентского датафрейма и вычислить количество выходных файлов;
- разбить клиентский датафрейм на количество разделов, равное количеству выходных файлов;
- снова сохранить разделенный датафрейм в клиентский каталог — из-за повторного разделения на предыдущем шаге, на выходе будет нужное количество файлов.
Предложенное решение имеет ряд проблем:
- для больших таблиц в часы пик обработка почасового раздела данных может занимать много времени (до 90 минут);
- высокое и неэффективное потребление ресурсов — когда все ядра заняты, загрузка ЦП кластера составляла 40–50%;
- случайные, обычно невоспроизводимые исключения нехватки памяти OOM (Out Of Memory) на исполнителях, которые замедляли работу приложений и приводили к их сбою.
Существует альтернативный подход, основанный на способности Spark ограничивать количество выходных записей, но он может создавать файлы очень разных размеров, чего следует избежать. Таким образом, разработчики Data Locker пришли к выводу о том, что необходимо создавать собственное ETL-решение по передаче файлов в облачное объектное хранилище средствами Apache Spark.
Оптимизация разделов и клиентских каталогов
Возвращаясь к рассмотренным вариантам решения, еще раз отметим неэффективность фильтрации клиентских приложений дважды для каждого клиента: один раз на этапе подсчета и еще раз при сохранении данных. Эта фильтрация требует значительных затрат ресурсов ЦП, особенно на обработку каждой строки в кэшированном наборе данных, который содержит все данные клиентов. Однако, действительно ли требуется точное количество строк для расчета количества выходных файлов? Можно получить его без применения фильтров и вызова счетчика отфильтрованного фрейма данных? Узнать верхнюю границу этого значения, можно просуммировав количество строк для каждого клиентского приложения. Например, выполнение команды df.groupby(app_id).agg(count) занимает максимум около минуты для самых больших таблиц в формате Parquet и структуре хранения данных, оптимизированной для чтения с помощью ID приложения. Так можно получить приблизительное количество строк датафрейма для расчета количества выходных файлов, относительная точность подходит для большинства практических случаев.
Но иногда при таком подходе создается неоправданное количество очень маленьких файлов. Поэтому следует записать количество файлов на основе предполагаемой верхней границы, а если это число будет слишком мало, можно повторно сгенерировать отчет. Узнать, сколько строк на самом деле поможет счетчик файлов в клиентском каталоге. Хотя это более эффективно, чем подсчет отфильтрованного датафрейма, оно опровергает изначальную идею исключения двойного подсчета. Здесь могут помочь аккумуляторы Apache Spark, которые позволяют записывать данные и подсчитывать записанные строки одновременно без заметного снижения производительности. Например, код на Spark Scala для этого будет выглядеть так:
def withRowsCounter(
df: DataFrame, client: String): (DataFrame, LongAccumulator) = {
val counter = df.sparkSession.sparkContext
.longAccumulator(s”rows-counter-for-$client”)
val countUdf = udf { () => counter.add(1); null }
val column = “triggerCounter” (df.withColumn(column, countUdf())
.filter(s”$column IS NULL”)
.drop(column),
counter)
}
Эта функция возвращает два значения: датафрейм данных и аккумулятор количества строк. Оценив примерную верхнюю границу и фактическое количество строк, можно исправить случаи некорректного подсчета. Тестирование показало, что с этим подходом приложения работают примерно на 20% быстрее, а загрузка ЦП снижается с 40–50% до <5%, включая пики загрузки 70–80%.
На этапе кэширования создается датафрейм с количеством разделов, вычисленных нетривиальным способом. Данные фактически считываются из озера данных и сохраняются в памяти. Следующее вычисление представляет собой перемешивание: каждый входной раздел (Map) подготавливает файл данных для чтения выходным разделом (Reduce). Этот файл отсортирован по идентификатору раздела Reduce для ускорения доступа к данным. Затем каждый Reducer связывается с каждым Mapper’ом для получения данных. Проблема в том, что каждое соединение передает слишком мало данных, и иногда Reducer связывается с Mapper’ом, чтобы убедиться в их фактическом отсутствии. А слишком большое количество входных разделов замедляет работу приложения из-за выполнения многих операций ввода-вывода, не использующих ЦП.
Для решения этой задачи стоит помнить, что количество клиентов и выходных файлов на одного клиента фиксированы. Можно повлиять только на количество Reducer’ов разделов для каждого клиента, из которого будут считываться данные. При этом, даже если удастся уменьшить общее количество разделов, Mapper’ы все равно должны знать, в каких разделах есть данные для них. Данные клиента по-прежнему могут находиться в слишком большом количестве разделов, и их слишком большое сокращение, например, с помощью метода coalesce() ухудшит масштабируемость. Нужно сгруппировать данные через каталоги, сохранив данные каждого клиента в его собственном каталоге S3 с помощью следующего кода:
df.join(broadcast(app2client), “app_id”)
.write
.partitionBy(“client”)
.parquet(s3CachePath)
Тестирование показало, что стало возникать множество исключений S3 SlowDown при записи промежуточных данных, т.к. Spark записывает выходной файл для каждого раздела датафрейма, если в нем есть хотя бы одна строка для выхода.
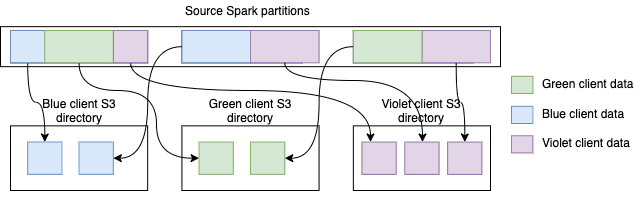
В результате Spark создал около 750 тысяч файлов, что слишком много для AWS S3. Следует сгруппировать данные клиента во входном датафрейме так, чтобы только небольшая часть входных разделов давала данные в заданный выходной каталог. В Apache Spark это можно решить с помощью функции repartitionByRange():
val cacheFilesNumber =
Math.max(1, totalEstimatedCount / 500000).toInt
df.join(broadcast(app2client), “app_id”)
.withColumn(“__randomize__”, rand(0))
.repartitionByRange(
cacheFilesNumber, col(“client”), col(“__randomize__”))
.drop(“__randomize__”)
.write
.partitionBy(“client”)
.parquet(s3CachePath.toString)
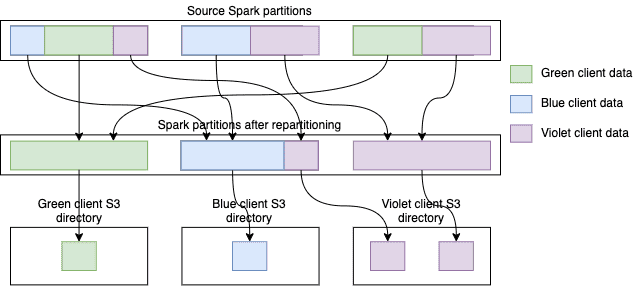
Разделив данные клиентов, можно избирательно обработать любого из них, просто прочитав данные из его каталога. Количество запросов MapReduce становится намного меньше, а каждый запрос содержит больше строк. У этого подхода тоже есть свои накладные расходы: кэш S3 должен быть сгенерирован заранее. А, поскольку данные клиентов больше не находятся в памяти, только практика может показать, целесообразно ли его применять. Тесты производительности показали в 5 раз меньше время выполнения и в 8 раз меньше время вычислений по сравнению с исходным решением. Другие тесты подтвердили отличную масштабируемость и сниженное потребление памяти (отсутствие ошибок OOM), что позволило сэкономить за счет использования более дешевых инстансов EC2.
Узнайте больше про администрирование и использование Apache Spark для разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

