
В этой статье разберем кейс построения экосистемы управления Big Data с озером данных на примере федеральной фармацевтической сети — российской Ассоциации независимых аптек (АСНА). Читайте в этом материале, зачем фармацевтическому ритейлеру большие данные, с какими трудностями столкнулся этот проект цифровизации и как открытые технологии (Arenadata Hadoop, Apache Spark, NiFi и Hive), взаимодействуют с проприетарными решениеми Informatica Big Data Management и 1С, а также облачными сервисами Azure.
Постановка задачи от бизнеса: проблемы, возможности и ограничения
АСНА позиционирует себя не просто информационным агрегатором по локальным и сетевым аптекам, а высокотехнологичной data-driven компанией с уникальной бизнес-моделью, в которой ключевую роль играет управление данными. Поэтому обеспечение их чистоты, качества и надежности является ключевой бизнес-задачей. Поскольку количество партнеров и поставщиков постоянно увеличивается, требование к быстрой масштабируемости Big Data системы стало одним из самых приоритетных [1]. Чтобы пояснить масштаб работы с большими данными, перечислим некоторые бизнес-показатели [2]:
- 250+ контрактов с различными производителями фармпрепаратов;
- более 9000 товарных идентификаторов в маркетинговых контрактах, где следует контролировать ассортимент на уровне маркетингового соглашения;
- около 2500 контрактов с разными аптечными сетями по всей России;
- около 10000 аптек, в каждой из которых необходим контроль маркетингового ассортимента.
Необходимость комплексной Big Data экосистемы управления данными вызвана следующими проблемами [2]:
- ежедневная загрузка и обработка данных длилась порядка 18 часов на 6500 аптек;
- интеграция и валидация данных также занимали чрезмерно много времени;
- процедуры закрытия контрольного периода и сверки данных были слишком сложными, постоянно какая-то информация не загружалась;
- добавление новых аптек длилось очень долго;
- при однодневном сбое некоторых процессов обработки данных, приходилось стабилизировать работу всех систем за недельный период.
Кроме решения этих проблем, перед новой экосистемой управления большими данными также стояла задача оперативного формирования бизнес-отчетности для конечных пользователей: поставщиков, аптек-партнеров и сотрудников АСНА (менеджеры, аналитики) [3].
Ход проекта: Data Lake и DWH
Проект стартовал в 2016 году, когда данные компании находились в двух хранилищах данных MS SQL Server. При этом качество данных было не высоким (так называемые «грязные» данные), отсутствовали мастер-данные и единая подсистема НСИ. Для анализа и обработки данных использовался набор разнородных приложений. В 2017 году была выбрана архитектура DWH и Data Lake на базе открытых Big Data технологий: Apache Hadoop, Hive, Spark, NiFi, а также коммерческое решение по управлению данными от Informatica.
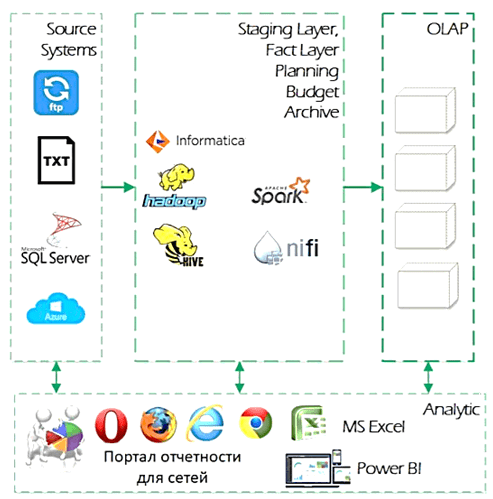
В процессе практической эксплуатации выяснилось, что эта архитектура не совсем соответствует требованиям к быстроте получения и удобстве представления аналитических отчетов. В частности, были выявлены следующие ограничения [2]:
- данные, над которыми постоянно выполняются транзакционные изменения (операции удаления, обновления, вставки), лучше оставить в реляционной СУБД, а не в NoSQL-хранилище (КХД на базе Apache Hadoop);
- так называемые «горячие» данные, которые нужны для быстрых операционных расчетов тоже целесообразнее оставить в реляционной СУБД;
- NoSQL-инструменты отлично справляются с обработкой неструктурированных данных, но они не заменят традиционные OLAP-кубы для BI-аналитики;
- высокая доступность выборки данных в HDFS компенсируется низкой скоростью выдачи результатов конечному потребителю.
Поэтому в 2018 году озеро данных было модифицировано и стало выполнять роль операционного слоя первичных данных или стейджинга (Staging Layer) для реляционного КХД, которое используется как слой фактов (Fact Layer) для планирования бюджетов. Подробнее про послойную архитектуру КХД мы рассказывали здесь. Также в 2018-2019 годах была внедрена интегрированная обработка данных с помощью Hadoop и Informatica, разработана единая подсистема НСИ и мастер-данных в условиях постоянных изменений. Еще появилась валидация данных и стали использоваться методы машинного обучения (Machine Learning) для задач консолидации НСИ. Data Lake сети АСНА до сих совершенствуется: в частности, ведется разработка архивного хранения и API-интерфейсов [2].
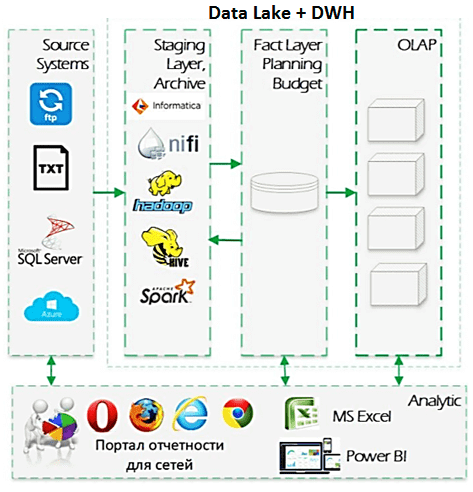
Итоговая архитектура Big Data решения
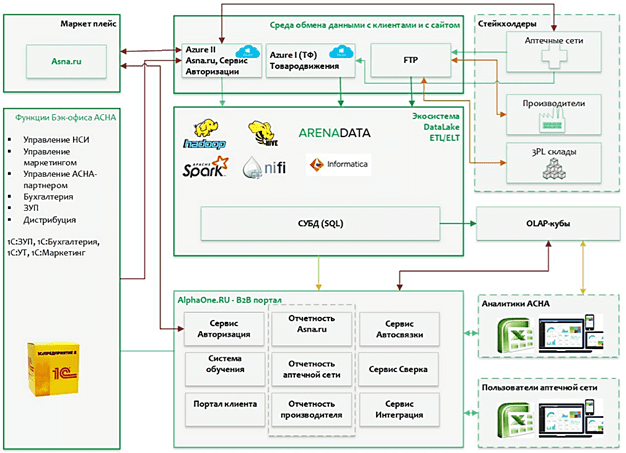
Рассмотрим архитектуру созданного Big Data решения подробнее. «Сырые» данные хранятся в Data Lake на базе отечественного дистрибутива Arenadata Hadoop. Потоковые ETL/ELT-процессы организованы с помощью Apache NiFif. В качестве SQL-on-Hadoop инструмента используется Apache Hive, что позволяет обращаться к данным в HDFS через SQL-подобные запросы (HiveQL). С помощью Apache Spark выполняется аналитика больших данных. Через облачные сервисы Azure организовано взаимодействие между внутренними системами 1С, которые поддерживают учетные функции бэк-офиса АСНА, и экосистемой управления Big Data (Data Lake И КХД).
В рамках этой системы Informatica Big Data Management выполняет парсинг файлов данных, проверяет форматы данных на соответствие заранее определенным требованиям, удаляет дубликаты строк, преобразует данные в единую структуру, проводит обогащение данных внутренней подсистемой НСИ и отвечает за архивирование. Также Informatica Big Data Management обеспечивает распределение вычислительной нагрузки между разными платформами с помощью технологии pushdown. Она позволяет превратить маппинг в скрипт и выбрать среду для его запуска, чтобы комбинировать сильные стороны разных платформ и достигать их максимальной производительности. Еще одним полезным свойством Informatica Big Data Management является эффективная работа с отображениями (маппингами) данных. Это позволило формировать adhoc-отчёты на кластере с использованием Apache Spark, а затем ставить маппинг на периодическую загрузку в аналитическое хранилище на Greenplum без привлечения новых дополнительных технологий [3].
Таким образом, такая комплексная Big Data система помогает конечному пользователю получать результаты аналитических запросов через визуальные дашборды, формировать отчетность, определять эффективность бизнес-инициатив и управленческие решения, основанные на объективных данных. В частности, это позволяет рассчитывать фактические показатели по продажам, возвратам, остаткам, закупкам, маркетинговым мероприятиям и отслеживать прочие важные бизнес-метрики [1].
В следующей статье мы продолжим разговор про озера данных и рассмотрим 3 примера Data Lake на промышленных предприятиях. Больше технических подробностей по организации Data Lake на базе Apache Hadoop для эффективного хранения и обработки больших данных в рамках проектов цифровизации своего бизнеса вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Hadoop
- Администрирование кластера Hadoop
- Hadoop для инженеров данных
- Безопасность озера данных Hadoop
- Администрирование кластера Arenadata Hadoop
- Основы Arenadata Hadoop
- Интеграция Hadoop и NoSQL
Источники

