
Apache AVRO не случайно считается очень востребованным форматом и популярной системой сериализации данных, который активно в Kafka. Сегодня рассмотрим, как сериализуются данные в AVRO, каким образом это связано со структурами JSON и при чем здесь реестр схем Confluent.
Еще раз про AVRO и сериализацию данных
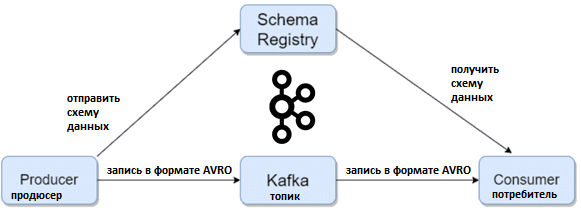
Apache Kafka часто используется в качестве инструмента потоковой передачи данных от одного микросервиса. Kafka принимает от приложения-продюсера в качестве входных данных байты и публикует их в топик для потребителя, что занимает много времени в случае множества записей. При этом на стороне потребителя не всегда выполняется проверка формата и структуры данных, полученных через сериализатор Kafka.
Важную роль в производительности этой системы играет сериализация данных, отправляемых в топики. Поскольку двоичные данные хранятся на жестком диске более эффективно, чем необработанный текст, не удивительно, что бинарный формат AVRO предпочтительнее, чем JSON-файлы. А по сравнению с Google Protobuf, в AVRO можно указать, какие поля являются обязательными, т.е. должны быть заполнены. Кроме того, этот формат сериализации не зависит от языка программирования и поддерживает JSON-структуры и эволюцию схемы данных, когда добавляются новые или удаляются существующие поля. В частности, именно поэтому платформа онлайн-обучения Udemy выбрала Apache AVRO вместо Google Protobuf в своей системе мониторинга событий пользовательского поведения, о чем мы недавно писали в этой статье.
Отправка данных в виде байтов приводит к проблемам их проверки и задержке, справиться с которыми можно с помощью реестра схем Confluent, о котором мы рассказывали здесь. Schema Registry обеспечивает нужный уровень обслуживания для метаданных, предоставляет Restful-API для хранения и получения схем AVRO, а также поддерживает эволюцию схемы, храня историю всех версий. Еще реестр схем предоставляет несколько параметров совместимости, позволяя изменять схемы в соответствии с этими параметрами. Наконец, Schema Registry предоставляет сериализаторы, которые подключаются к клиентам Kafka, обрабатывают хранение и извлечение схемы для сообщений в формате AVRO.
Таким образом, можно сказать, что реестр схем предоставляет потребителям и продюсерам Kafka способ управления AVRO-схемами для передачи данных. А формат AVRO обеспечивает миграцию схемы данных для систем, построенных по микросервисной архитектуре, полностью определяя структуру, тип и значение данных.
Рассмотрим пример *.avsc-файла AVRO-схемы, которая описывает структуру данных на понятном человеку языке JSON (JavaScript Object Notation) в виде текста с парами «ключ/значение». Предположим, необходимо хранить данные о студентах: идентификатор, имя, адрес и телефон. Тогда AVRO-схема данных для таких записей будет храниться в файле с расширением *.avsc и выглядит следующим образом:
{
«type»: «record»,
«name»: «studentInfo»,
«namespace»: «com.domain.avro»,
«fields»: [
{
«name»: «studentId»,
«type»: «long»
},
{
«name»: «studentName»,
«type»: «string»
},
{
«name»: «studentAddress»,
«type»: [«null», «string»]
},
{
«name»: «studentTel»,
«type»: [«null», «string»]
}
]
}
Для генерации схем AVRO можно воспользоваться плагином Maven, парсером или методами API.
Apache Spark и Kafka: читаем данные в AVRO и JSON
Рассмотрим пример, когда за потоковую обработку данных, хранящихся в топиках Apache Kafka, отвечает Spark-приложение. Spark считывает данные из этой распределенной платформы потоковой передачи событий в датафрейм:
Dataset<Row> kafka_df = spark.read().format(“kafka”).option(“kafka.bootstrap.servers”, “host1:port1,host2:port2”).option(“subscribe”, “topic1,topic2”).option(“startingOffsets”, “{\”topic1\”:{\”0\”:23,\”1\”:-2},\”topic2\”:{\”0\”:-2}}”).option(“endingOffsets”, “{\”topic1\”:{\”0\”:50,\”1\”:-1},\”topic2\”:{\”0\”:-1}}”).load();
Этот датафрейм состоит из семи столбцов, которые определяют атрибуты каждого сообщения, полученного из Kafka:
- Ключ – key;
- Значение – vаlue;
- Топик – tорiс;
- Раздел – раrtitiоn;
- Смещение – оffset;
- Метка времени – timestаmр;
- Тип метки времени – timestаmрTyрe.
Столбцы Key и Vаlue используются для извлечения смысла сообщения, наиболее ценная колонка содержит данные, которые можно расширить в датафрейм. Причем сами данные могут быть представлены в Kafka в нескольких форматах.
Например, в виде JSON, если схема данных имеется:
StructType json_schema=”schema of the dataframe”
Dataset<Row> input = kafka_df.withColumn(“data”,
functions.from_json(kafka_df.col(“value”), schema)).select(“data.*”);
Этот метод подходит, когда схема данных определена и не меняется, что редко бывает в реальном мире. При отсутствии схемы, если столбец vаlue содержит строки JSON, их можно преобразовать для дальнейшей обработки:
Dataset<Row> input = sparkSession.read().json(kafka_df.selectExpr(“CAST(value AS STRING)
as value”).map(Row::mkString, Encoders.STRING()))
При этом двоичный столбец vаlue преобразуется в строку в формате JSON, а функция MAP помогает преобразовать набор данных <Rоw> в набор данных <String>. Чтение этого набора данных, содержащего строки JSON с использованием метода АРI reаd().jsоn() поможет создать исходный набор данных для дальнейшей обработки. Также это можно выполнить с помощью Javа RDD:
JavaRDD<String> store = kafka_df.selectExpr(“CAST(value AS STRING) as value”).toJavaRDD().map(x->x.mkString());
Dataset<Row> input = spark.read().json(store);
Эти методы пригодятся в сценариях изменения схемы, когда ее описание отсутствует.
Для изменения данных в AVRO-формате необходимо, чтобы схема была представлена в форме строки JSON. К примеру, данные опубликованы в Kafka, столбец Vаlue отмечен как обязательный.
output.selectExpr(“to_json(struct(*)) AS
value”).write().format(“kafka”).option(“kafka.bootstrap.servers”,
“host:port”).option(“topic”, “topic_name”).save();
Если данные хранятся сразу в AVRO:
output.select(package$.MODULE$.to_avro(struct(“*”)).as(“value”)).write().format(“kafka”).option(“kafka.bootstrap.servers”, “localhost:9093”).option(“topic”,”test_avro”).save();
Идея в обоих случаях в том, чтобы создать поле value как столбец с типом «структура» с вложенными столбцами, и записать его в папку, откуда его можно извлечь и использовать для восстановления датафрейма.

Описанные методы могут быть использованы для чтения и записи данных в Apache Kafka.
Узнайте больше про администрирование и эксплуатацию Apache Kafka для эффективной аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://vidhitakher.medium.com/how-to-use-avro-schema-for-serialization-with-kafka-dc319cfa484d
- https://docs.confluent.io/platform/current/schema-registry/index.html
- https://sidgarg-exp.medium.com/how-to-read-the-kafka-stream-data-of-json-and-avro-type-and-write-it-to-another-kafka-stream-49797524d15
- http://avro.apache.org/docs/1.7.6/index.html

