
Хорошие курсы инженеров данных – это не просто обучение отдельной Big Data технологии, такой как Apache Hadoop, Spark или Kafka, а жизненные примеры их практического использования в реальном бизнесе. Поэтому сегодня мы приготовили для вас кейс оптимизации стоимости и скорости OLAP—аналитики больших данных в облачном Delta Lake на Amazon Web Services (AWS) с помощью API дельта-таблиц и CDC-подхода.
Архитектура OLAP-системы на базе Delta Lake в AWS с Kafka и Spark
Вчера мы рассматривали возможности ускорения OLAP-аналитики больших данных на базе Delta Lake, Apache Presto и Spark SQL за счет создания предварительно агрегированного набора данных для генерации различных BI-отчетов. Чтобы еще более повысить эффективность такого подхода, сегодня рассмотрим, как улучшить его развертывание в публичном облаке AWS с точки зрения бизнеса. В качестве оптимизируемых параметров выступают скорость аналитической обработки данных OLAP (Online analytical processing) и затраты на AWS-сервисы.
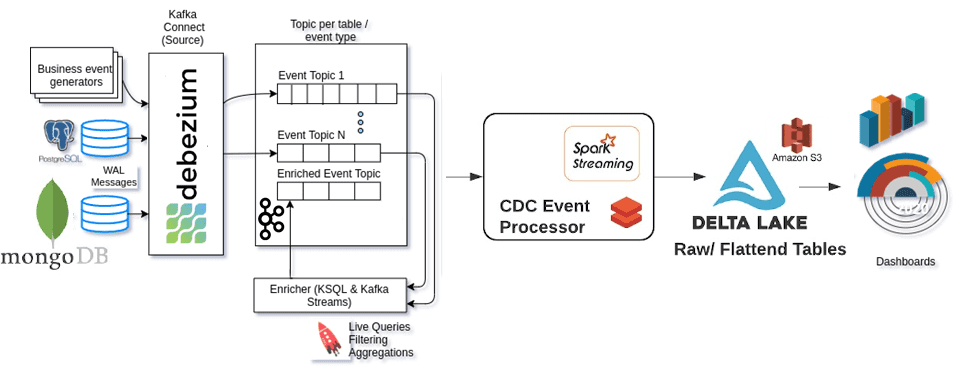
Для ускорения процессов аналитической обработки больших данных в архитектуру OLAP-системы заложен CDC-подход (Change Data Capture), основанный на работе с измененными данными. Быстрый уровень хранилища данных c поддержкой ACID-транзакций обеспечивает Delta Lake от Databricks на базе Apache Spark, развернутый в облаке AWS. В качестве источников данных выступают корпоративные OLTP- приложения на основе MongoDB и PostgreSQL. За реализацию CDC-подхода отвечает Debezium – распределенная open-source платформа с набором коннекторов для различных СУБД, совместимых с Apache Kafka Connect. Захват потока событий из OLTP-систем и их загрузка в AWS S3 обеспечивается с помощью Spark Structured Streaming. Delta Lake записывает данные в формате Parquet и поддерживает несколько версий файлов для загрузки данных [1].
Оптимизация затрат на облачные Big Data сервисы
Стоимость вышеприведенной OLAP-системы можно снизить за счет оптимизации расходов на AWS S3. Напомним, расходы на сервисы AWS рассчитываются только за время фактического использования нужных сервисов [2]. Таким образом, в случае объектного хранилища S3 cтоимость затрат складывается из числа вызовов API GetObjects/ListObjects в корзинах S3. API-интерфейсы Delta Lake вызывают API-интерфейсы AWS S3 через следующие методы дельта-таблиц [3]:
- DeltaTable.forPath – создание дельта-таблицы для данных по заданному пути, используя заданный SparkSession;
- DeltaTable.merge – объединяет данные из исходного DataFrame на основе заданного условия объединения и возвращает объект DeltaMergeBuilder, который можно использовать для указания действий обновления, удаления или вставки над строками, которые соответствуют условию;
- DeltaTable.vacuum — рекурсивно удаляет файлы и каталоги в таблице, которые не нужны для поддержания более старых версий до заданного порога хранения и возвращает пустой DataFrame при успешном завершении.
Для загрузки данных из таблиц PostgreSQL или коллекций MongoDB был написан специальный обработчик, который выполняет синтаксический анализ сообщения JSON от Debezium, играя роль единственной CRUD-операции в PostgreSQL и MongoDB.
Таким образом, оптимизация расходов на API-вызовы к AWS через дельта-таблицы была выполнена следующим образом [1]:
- Поскольку инициализация API дельта-таблицы выполняет сканирование каталога <DeltaTable_Path>/_delta_log /, целесообразно вызывать DeltaTable.forPath только один раз во время инициализации Spark-задания, которое внутренне обращается к AWS S3 ListObjects.
- Вместо первоначального вызова API DeltaTable.vacuum в конце каждого выполнения микро-пакета, чтобы очистить старые версии данных дельта-таблицы, целесообразно делать это только раз в день, т.к. это также обращается к AWS S3 GetObjects/ListObjects и DeleteObjects API.
- Запуск OPTIMIZE API с настроенным интервалом времени, как в API VACUUM, позволяет объединить небольшие файлы в файлы эквивалентного размера 128 МБ.
- API DeltaTable.merge (core API) выполняет фактическую операцию вставки/обновления/удаления определенных записей.
Debezium позволяет получить полную запись в случае вставки/обновления из PostgreSQL и частичную запись для определенных случаев обновления из MongoDB.
Однако, несмотря на создание партицированных таблиц в Databricks, для некоторых обновлений, таких как $set в MongoDB, не удавалось получить значение столбца раздела за все время. Это приводило к необходимости полного сканирования AWS S3 для API DeltaTable.merge, чтобы найти и обновить старую запись. В результате существенно возрастало время аналитической обработки и ее стоимость. Избежать полного сканирования API DeltaTable.merge позволит предоставление значений столбцов для разделов таблицы с операциями обновления. Поэтому для частичных записей MongoDB выполнялся поиск в источнике (MongoDB) с помощью ObjectId, чтобы получить полные атрибуты записи нужной коллекции и загрузить последнюю запись на AWS S3.
В результате всех этих действий число API-вызовов к S3 существенно уменьшилось, сократив около 55% ежедневных расходов на AWS. Про другой пример OLAP-системы на Apache Kafka читайте в нашей новой статье.
Как разработать и развернуть собственные системы аналитики больших данных с Apache Kafka, Spark и другими технологиями Big Data, а также повысить их техническую и экономическую эффективность, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для разработчиков
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- https://raveendra-allam.medium.com/deltalake-delta-io-cost-optimisation-on-aws-s3-cb3c0e7598f2
- https://aws.amazon.com/ru/pricing/?nc2=h_ql_pr
- https://docs.delta.io/latest/api/java/io/delta/tables/DeltaTable.html

