Сегодня рассмотрим, как выполняются операции чтения и записи в Apache HBase, а также с помощью каких приемов можно их ускорить. Как рассчитать оптимальное количество регионов в таблице, зачем отключать версионирование, почему размер ключа строки должен быть небольшим и еще 7 полезных лайфхаков для администратора HBase-кластера.
Оптимизация записи данных в Apache HBase
Apache HBase активно используется в качестве хранилища данных во множестве реальных проектов по всему миру. Эта популярная колоночная NoSQL-СУБД работает поверх распределенной файловой системы HDFS и обеспечивает возможности BigTable для Hadoop. HBase реализует отказоустойчивый способ хранения больших объёмов разреженных данных и обеспечивает случайный доступ в реальном времени к данным в Hadoop в сочетании с удобством пакетной обработки.
Распределенный характер HBase реализует механизм регионирования, когда данные распределяются по разным физическим машинам кластера по принципу автоматической горизонтальной группировки строк таблиц, соответствующих определенному диапазону подряд идущих первичных ключей, в единый диапазон – регион. За обслуживание одного или нескольких регионов отвечают региональные сервера (RegionServer), а за распределение регионов по региональным серверам — главный узел в кластере, MasterServer. О том, целесообразно ли размещать несколько региональных серверов на одном узле кластера HBase мы писали здесь.
При сбое регионального севера его регионы быстро назначаются новым серверам, а распределенный лог опережающей записи ((Write Ahead Log, WAL) делится по регионам и распределяется между региональными серверами, которые воспроизводят WAL для восстановления более раннего состояния. Воспроизведение WAL может быть медленным, что приводит к блокировке при очень низкой производительности чтения и записи в это время.
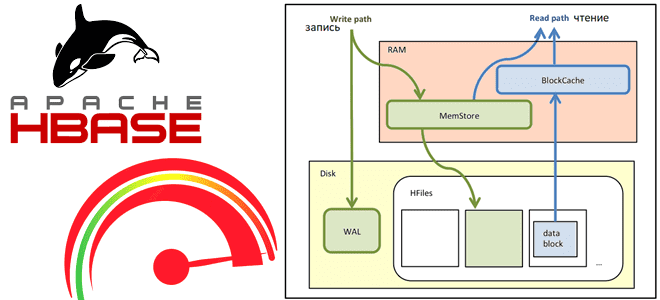
Apache HBase не поддерживает SQL-хапросы, а для операций с данными использует собственный язык, в котором есть команды для выполнения базовых crud-операций с данными. Например, команда put используется для добавления новой или обновления существующей записи в таблице. Сам процесс записи данных в HBase реализуется следующим образом:
- PUT-запрос идет к распределенному WAL-файлу с сохраненными данными для восстановления. Записи HBase по умолчанию записываются в WAL, на диск в последовательный файл, используемый для восстановления.
- затем данные записываются в MemStore — буфер на запись, специально выделенная область памяти для накопления данных перед постоянной записью. MemStore хранится в памяти региональных серверов. Для каждого региона и семейства столбцов существует отдельный MemStore. После записи данных в MemStore возвращается подтверждение (ack).
- после того, как в MemStore накопилось достаточно данных для постоянной записи, буфер очищается, и создается очередной 1 HFile, который записывается на диск. Сами данные физически хранятся на HDFS, в специальном формате HFile, отсортированные по значению первичного ключа (RowKey). Одной паре (регион, column family) соответствует как минимум один H-файл. Если у одного региона заполнен буфер записи, он очищается, и все остальные буферы для других семейств столбцов также будут очищены.
Оптимизировать Hbase для высокой нагрузки операций записи можно следующим образом:
- поскольку после заполнения буфера записи MemStore, который по умолчанию занимает до 2 МБ, можно увеличить размер MemStore, чтобы сократить число очисток диска.
- Чтобы у MemStore было больше места для записи данных, рекомендуется держать количество регионов низким, а размер региона – большим (от 8 ГБ и более). Это же позволит реже выполнять слияние H-файлов.
- Изменив значение порога сжатия через свойство hstore.compactionThreshold можно увеличить количество файлов для незначительного уплотнения (Minor Compaction), которое выполняется в фоновом режиме и не слишком нагружает систему. При этом может потребоваться изменение параметров hbase.hstore.blockingstorefiles и hbase.hstore.compaction.max.
- увеличение значения свойства hbase.regionserver.thread.compaction.small повысит количество потоков, доступных для незначительного уплотнения.
- Аналогично можно увеличить пределы локального и глобального (hbase.regionserver.global.MemStore.upperlimit, hbase.regionserver.global.MemStore.lowerlimit) давление перед созданием H-файлов.
- Предварительное разделение таблицы позволит добавить хэш-префикс для ускорения поиска строк.
Как выполняются операции чтения в Apache HBase и каким образом можно их оптимизировать, рассмотрим далее.
Администрирование кластера HBase
Код курса
HBASE
Ближайшая дата курса
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
Оптимизация чтения
Чтение данных в Apache HBase происходит следующим образом:
- клиент получает местоположение мета-таблицы HBase от сервису синхронизации данных Zookeeper, кэширует информацию и местоположение и напрямую обращается к региональному серверу для запроса. Повторная ссылка на метатаблицу выполняется только в случае сбоя запроса. Метатаблица представляет собой B-дерево, хранящее стартовый ключ, идентификатор региона и региональный сервер.
- данные для чтения с регионального сервера могут находиться в BlockCache (кэш на чтение, позволяющий экономить время на часто читаемых данных), MemStore или во множестве H-файлов. Сперва читает BlockCache, потом MemStore, а лишь затем H-файлы. Если на диске много несжатых H-файлов, возможно, придется прочитать их все. Это называется read amplification и замедляет процесс чтения.
Таким образом, HBase гарантирует строгую согласованность чтения: как только запись возвращается, все операции чтения будут видеть одни и те же данные. О том, как ограничить доступ к данным в таблицах HBase определенным пользователям, читайте в нашей новой статье.
Оптимизировать операции чтения в HBase при высокой нагрузке помогут следующие рекомендации:
- для небольших сканирований можно увеличить размер блочного кэша и уменьшить количество H-файлов до начала незначительного сжатия, чтобы на диске всегда было небольшое количество файлов, которые можно просмотреть во время чтения. Также рекомендуется периодически запускать основное сжатие (Major Compaction), во время которого происходит физическое удаление данных, ранее помеченных соответствующей меткой tombstone. Это дополнительно повысит локальность данных и сократит количество H-файлов.
- для объемных сканирований лучше уменьшить размер блочного кэша или даже совсем отключить его.
Как объединить эти советы, чтобы оптимизировать операции чтения и записи в Apache HBase, смотрите далее. А ка реализуются ACID-требования к транзакциям в этой NoSQL-СУБД, читайте в нашей новой статье.
Интеграция Hadoop и NoSQL
Код курса
NOSQL
Ближайшая дата курса
Продолжительность
40 ак.часов
Стоимость обучения
120 000 руб.
10 лучших практик по работе с HBase
Агрегировав вышерассмотренные подходы к оптимизации операций чтения и записи, сформируем лучшие практики работы с Apache HBase:
- Предварительное разделение — таблица по умолчанию создается с одним регионом, т.е. все операции чтения-записи идут на один региональный сервер. Это приводит к большой нагрузке на производительность при разделении регионов. Поэтому следует избегать автоматического разделения регионов, особенно для таблиц с небольшим количеством регионов. В случае большой нагрузки на запись, регион может быть не в состоянии разделить и увеличить свой размер в 5-10 раз относительно первоначального значения (по умолчанию). Лучше всего предварительно разделить таблицу, определив количество регионов на основе ожидаемого размера нагрузки.
- Хэширование префикса ключа, чтобы предупредить неравномерное распределение нагрузки или монотонное увеличение ключей. Наличие хэш-префикса гарантирует примерно 99%-е равномерное распределение нагрузки.
- Определение ключа строки и его размера — лучше создавать rowKey так, чтобы он мог удовлетворить все сценарии путем получения или небольшого сканирования префикса. Рекомендуется задавать размер ключа строки небольшим, т.к. он повторяется с каждым столбцом при сохранении. Стоит внимательно задавать количество столбцов на rowKey — HBase масштабируется до сотен столбцов на ключ строки. Но при попытке получить такой ключ строки без фильтров, может истечь тайм-аут получения или возникнут проблемы с памятью (OOM, Out Of Memory) из-за огромных размеров данных. Поэтому лучше перепроектировать вариант использования, если в нем действительно нужны тысячи столбцов.
- Управление версиями – HBase позволяет сохранить версию данных, по умолчанию до 3-х раз. Если нет потребности читать данные предыдущих версий, следует установить для параметра VERSIONS значение 1 при создании таблицы в команде create. При этом управление версиями работает всегда, даже значение 1 для параметра VERSIONS на самом деле не отключает версионирование – каждый put-запрос по-прежнему создает новую версию данных, но сохраняется только последняя.
- Установка размера региона в зависимости от варианта использования. Маленькие регионы хороши, если данных не так много, и нужно достаточное количество разделений для распределения нагрузки или загрузки их с помощью Apache Spark, где большие регионы могут не поместиться либо снижать производительность. Для больших таблиц предпочтительны большие размеры регионов, от 4 ГБ. Для очень больших таблиц размер региона стартует от 16 ГБ.
- Количество регионов в таблице кратно количеству узлов в кластере. Если в кластере HBase сотни узлов, в таблице может быть минимум 10–20 регионов. Также можно задать количество регионов на основе потенциального размера таблицы и размера региона по умолчанию.
- Количество столбцов в семействе должно быть как можно меньше, в идеале 1, максимум 3. HBase рассматривает семейство столбцов как отдельную таблицу, кроме случаев сброса данных на диск — данные всех столбцов в семействе сбрасываются на диск, создавая еще большую фрагментацию. Единственным преимуществом нескольких столбцов в одном семействе – возможность получать данные из 2 или более семейств за один вызов get/scan.
- Включение сжатия экономит место на диске. Например, кодеки Snappy и Gzip сжимают данные в 4–5 и 7–10 раз соответственно. При этом стоит помнить о росте накладных расходов на ЦП в связи со сжатием и распаковкой данных во время записи и чтения, что может немного увеличить задержки чтения.
- Указание времени жизни данных (TTL, Time To Life) — если HBase используется в качестве кэша, можно указать TTL уровня столбца или уровня семейства столбцов, тогда строки с истекшим сроком действия будут очищены при незначительном сжатии.
- Указание диапазона при сканировании данных или фильтрация столбцов в get-запросе позволит снизить количество операций поиска на диске и уменьшит передачу данных по сети.
Узнайте больше подробностей по администрированию и использованию Apache HBase для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

