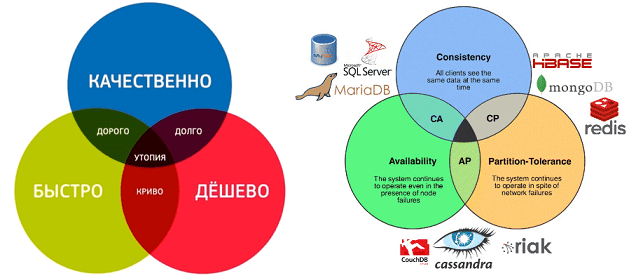
В этой статье мы расскажем про краеугольный камень распределенных Big Data систем – CAP-теорему, в которой одновременно возможно реализовать только 2 свойства из 3-х, по аналогии с треугольником ограничений в проектном менеджменте «Быстро-Качественно-Дешево». Также рассмотрим, за что критикуют модель CAP и почему современные NoSQL-СУБД стоит рассматривать с позиций BASE и PACELC.
Что такое CAP-теорема и причем здесь Big Data
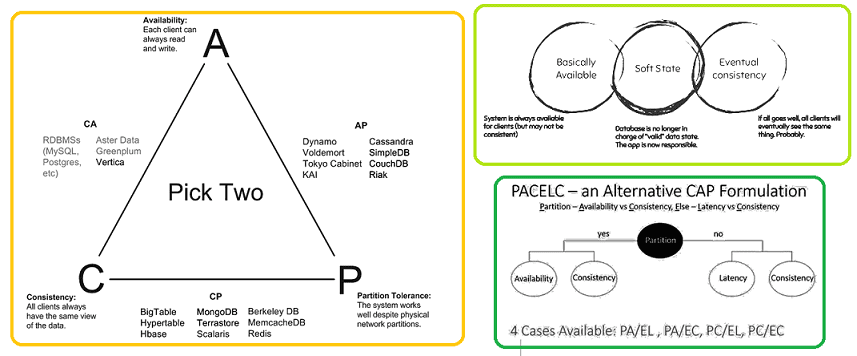
Напомним, CAP-теорема описывает возможность распределенных систем одновременно обеспечивать только 2 свойства из 3-х: согласованность (Consistency), доступность (Availability) и устойчивость к разделению (Partition tolerance). Эта гипотеза была высказана профессором Эриком Брюером в 2000-м году, а 2-мя годами е формальное доказательство опубликовали Сет Гилберт и Нэнси Линч из MIT. Обычно о CAP-теореме говорят в контексте Big Data систем на базе NoSQL-хранилищ, которые жертвуют согласованностью данных в пользу доступности и устойчивости к разделению. При этом распределённое решение обеспечивает корректный отклик от каждого из работающих узлов кластера [1].
Hadoop SQL администратор Hive
Код курса
HIVE
Ближайшая дата курса
по запросу
Продолжительность
8 ак.часов
Стоимость обучения
24 000 руб.
Отметим, что положения CAP-теоремы относятся к распределенным системам вообще, а не только к базам данных. В частности, Apache ZooKeeper, централизованная служба синхронизации распределенных сервисов, которая часто используется в Big Data системах, тоже может быть рассмотрена с позиции CAP-ограничений. Однако, сегодня нет необходимости в таком категоричном разделении систем по CA/CP/AP-классам, которые предусматривает CAP-теорема. Более того, подобная кластеризация даже считается ошибочной, поскольку широкая трактовка CAP-положений не учитывает потребности современных распределенных баз данных и Big Data приложений, а потому ее применение к этим системам не совсем корректно [2].
Критика концепции
При всей понятной на первый взгляд концепции тройственной ограниченности, CAP-теорему критикуют за чрезмерное упрощение важных понятий, что приводит к неверному пониманию первоначального смысла модели. В результате этого теорема из строгого, математически доказанного утверждения превращается в маркетинговый термин с расплывчатым смыслом. Наиболее явно это выражается в следующих случаях [2]:
- Согласованность (Consistency) в САР означает линеаризуемость, а не фиксацию завершенной транзакции, как в ACID. Напомним, линеаризуемость – это локальное и неблокируемое свойство программы, при котором результат любого параллельного выполнения операций эквивалентен их последовательному выполнению. Для любого другого потока выполнение линеаризуемой операции является мгновенным: операция либо не начата, либо завершена [3]. В реальности это значит, что информация во всех репликах, включая кэшированные данные, должна быть одна и та же. Достичь этого не очень просто.
- Определение доступности (Availability) ничего не говорит про временную задержку обработки данных (latency), при большом значении которой систему сложно назвать доступной на практике.
- Устойчивость к разделению (Partition tolerance) означает, что для связи используется асинхронная сеть, которая может терять или задерживать сообщения, что характерно для любой Интернет-системы. Поэтому создается ложное впечатление возможности настраивать параметр «P» в распределенных системах и рассматривать локальные хранилища данных в нерелевантном контексте.
Администрирование кластера HBase
Код курса
HBASE
Ближайшая дата курса
26 августа, 2024
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
В итоге получается слишком узкий взгляд на архитектурные особенности и функциональные возможности современных Big Data систем при попытке классифицировать их по категориям CP/AP. Например, Cassandra позиционируется как распределенная СУБД, поддерживающая все 3 свойства CAP благодаря механизму настраиваемых уровней согласованности, про который мы рассказывали здесь [4]. Однако, такое сочетание противоречит принципу тройственной ограниченности CAP-теоремы, таким образом опровергая ее. На самом деле это показывает не ошибочность теоремы, а ее некорректное применение к несоответствующим объектам, например, как в случае неприменимости законов классической механики к релятивистским явлениям [5].
Альтернативные подходы к оценке распределенных систем
Поскольку даже сам автор CAP-теоремы отмечает ее несостоятельность для оценки современных Big Data систем, были предложены альтернативные варианты. Наиболее известным подходом считается BASE (Basically Available, Soft-state, Eventually consistent) – базовая доступность, неустойчивое состояние, согласованность в конечном счёте. Этот подход к построению распределенных систем был сформулирован во второй половине 2000-х годов. Базовая доступность означает, что сбой на некоторых узлах приведет к отказу в обслуживании только незначительной части сессий, сохраняя доступность в большинстве случаев. Неустойчивое состояние подразумевает возможность жертвовать долговременным хранением состояния сессий (промежуточные результаты выборок, информация о навигации и контексте) в пользу фиксации обновлений только критичных операций. Согласованность в конечном счёте предполагает возможность противоречивости данных в некоторых случаях, но гарантирует итоговую целостность информации в практически обозримое время [6]. Таким образом, Cassandra скорее соответствует BASE-концепции, чем CAP в ее изначальной трактовке. По сути, BASE считается противоположностью ACID-модели, утверждая, что истинная согласованность не может быть достигнута в реальном мире и смоделирована в высокомасштабируемых системах. При выборе между BASE и ACID стоит учитывать контекст задачи. В частности, если нужна высокая скорость обработки, а целостность данных не является критичной, BASE будет лучшим вариантом. Иначе стоит подумать об ACID, что сделает систему максимально надежной с точки зрения данных в плане полной поддержки классических транзакций [7].
Интеграция Hadoop и NoSQL
Код курса
NOSQL
Ближайшая дата курса
5 августа, 2024
Продолжительность
40 ак.часов
Стоимость обучения
120 000 руб.
Еще одним альтернативным подходом к построению распределенных систем считается теорема PACELC, впервые описанная Даниелом Дж. Абади из Йельского университета в 2012 году. Она основана на модели CAP, но, помимо согласованности, доступности и устойчивости к разделению также включает временную задержку (L, Latency) и логическое исключение между сочетаниями этих понятий. Согласно PACELC, в случае сетевого разделения (P) в распределенной системе необходимо выбирать между доступностью (A) и согласованностью (C), как и в CAP- теореме, но в остальном (E, ELSE), даже при нормальной работе системы без разделения, нужно выбирать между задержкой (L) и согласованностью (C). В логическом выражении PACELC формулируют следующим образом: IF P -> (C or A), ELSE (C or L). Так PACELC расширяет и уточняет CAP-теорему, регламентируя необходимость поиска компромисса между временной задержкой и согласованностью данных в распределенных Big Data системах. Поэтому более корректно вместо классифицировать NoSQL-СУБД по категориям PACELC, чем по CAP, например, так [8]:
- Amazon DynamoDB, Cassandra, Riak и Cosmos DB – это PA/EL-системы, в которых согласованность может страдать в пользу доступности при разделении, а при нормальной работе – в пользу более низкой задержки времени;
- MongoDB можно рассматривать как PC/EC-базу, которая в большинстве случаев гарантирует, согласованность операций чтения и записи;
- Google Big Table и Apache HBase, а также ACID-совместимые VoltDB, H-Store, Megastore и MySQL Cluster, являются PC/EC-системами, которые не отказываются от согласованности, оплачивая затраты на доступность временем ожидания ее достижения.

Как проектировать, настраивать и администрировать NoSQL-решения, чтобы найти баланс между согласованностью, доступностью, устойчивостью и задержкой обработки данных в распределенных системах, разбирается на наших практических курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Администрирование кластера HBase
- Архитектура Данных
- Hadoop SQL администратор Hive
- Интеграция Hadoop и NoSQL
- https://ru.wikipedia.org/wiki/Теорема_CAP
- https://habr.com/ru/post/258145/
- https://ru.wikipedia.org/wiki/Линеаризуемость
- https://www.datastax.com/blog/2019/05/how-apache-cassandratm-balances-consistency-availability-and-performance
- https://habr.com/ru/post/322276/
- https://ru.bmstu.wiki/Теорема_CAP_(Consistency,_Availability_и_Partition_tolerance)
- https://habr.com/ru/post/328792/
- https://en.wikipedia.org/wiki/PACELC_theorem