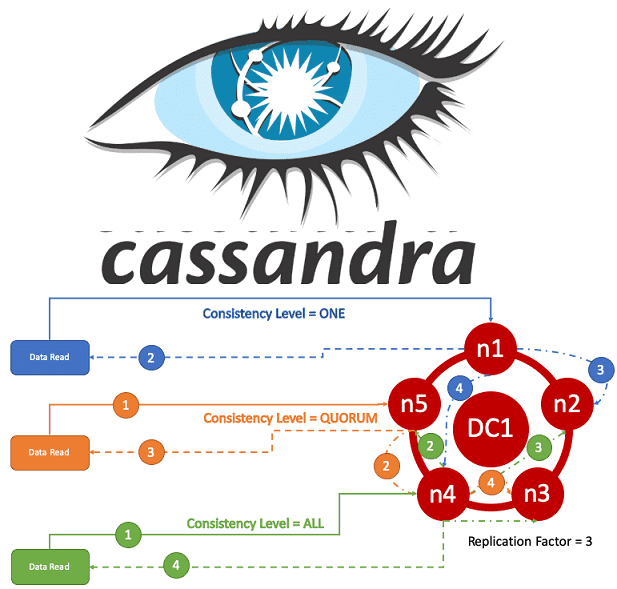
Как мы уже отмечали, одним из преимуществ Кассандры является возможность задания уровня согласованности для операций чтения и записи данных. В этой статье рассмотрим, какие бывают уровни согласованности для этих процессов в Apache Cassandra, и как они влияют на скорость работы распределенной NoSQL-СУБД при ее эксплуатации в реальных Big Data проектах.
Что такое согласованность и зачем она нужна
Вообще, разговор о согласованности данных в распределенных системах стоит начать с CAP-теоремы (согласованность, доступность, устойчивость) [1], однако это тема отдельной статьи. Apache Cassandra полностью реализует принципы доступности (Availability) и устойчивости к разделению (Partition tolerance), обеспечивая корректный отклик на любой запрос и простоту масштабирования. Однако, согласованность (Consistency), т.е. непротиворечивость данных считается слабым местом этой распределенной СУБД в связи с ее децентрализацией, когда на множестве узлов хранятся разные реплики одной и той же информации. Для устранения этой проблемы используется механизм настройки уровней согласованности.
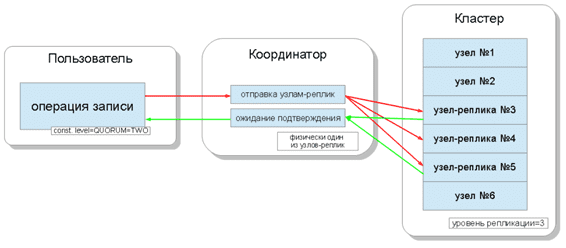
Напомним, в отличие от другой популярной NoSQL-базы данных для Big Data, Apache HBase, все узлы кластера Cassandra равноценны – клиенты могут соединятся с любым из них для записи и чтения. При этом выполнение запроса начинается с его координации, чтобы с помощью ключа и меток определить, на каких узлах кластера находятся нужные данные и отправить запрос именно туда. Узел, выполняющий координацию, называется координатором (coordinator), а узлы, которые выбраны для сохранения записи с данным ключом — узлами-реплик (replica nodes). Физически координатором может быть один из узлов-реплик [2].
Можно сказать, что доступность данных напрямую зависит от уровня согласованности операций чтения и записи, так как он определяет, сколько узлов-реплик может отказать при подтверждении успешного выполнения этих операций. Например, если уровень репликаций меньше, чем сумма узлов, с которых пришло подтверждения об успешной записи данных, и с которых происходит чтение, то есть гарантия строгой согласованности (strong consistency). Строгая согласованность гарантирует, что после записи новое значение всегда будет прочитано. Иначе возможна ситуация, когда в результате чтения СУБД возвратит устаревшие данные.
Для борьбы с этим в Apache Cassandra есть механизм итоговой согласованности (eventual consistency), который распространит данные по узлам-репликам после того, как закончится координационное ожидание. Если при этом будут доступны не все узлы-реплики, то придется задействовать другие средства восстановления данных, в частности, чтение с исправлением и запускаемое вручную анти-энтропийное восстановление узла (anti-entropy node repair) [2].
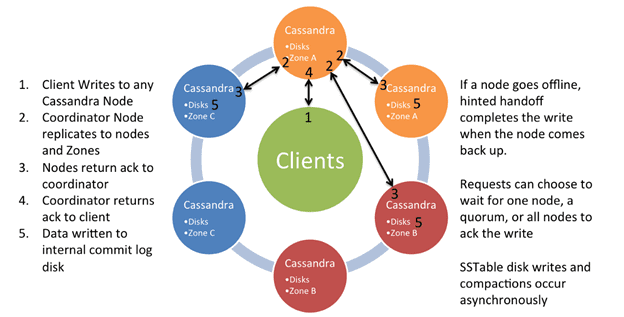
Согласованная запись в NoSQL-СУБД Кассандра
При записи данных уровень согласованности определяет количество узлов-реплик, с которых будет ожидаться подтверждение удачного окончания операции – сигнала того, что данные успешно записаны. Для записи существуют такие уровни согласованности [2]:
- ANY (0) — даёт возможность записать данные, даже если все узлы-реплики не отвечают. Координатор дожидается первого ответа от любого одного узла-реплик или данные сохранятся с помощью механизма направленной отправки (hinted handoff) на координаторе.
- ONE (1) — координатор шлёт запросы всем узлам-реплик, но возвращает управление пользователю, дождавшись подтверждения от любого первого узла;
- TWO (2)— координатор дожидается подтверждения от двух первых узлов, прежде чем вернуть управление;
- THREE (3) — координатор ждет подтверждения от трех первых узлов, прежде чем вернуть управление;
- QUORUM (4) — координатор дожидается подтверждения записи от более чем половины узлов-реплик, а именно round(N/2)+1, где N — уровень репликации;
- ALL (5) — координатор дожидается подтверждения от всех узлов-реплик;
- LOCAL_QUORUM (6) — координатор дожидается подтверждения от более чем половины узлов-реплик в том же центре обработки данных, где расположен координатор. Это позволяет избавиться от задержек, связанных с пересылкой данных в другие датацентры.
- EACH_QUORUM (7) — координатор дожидается подтверждения от более чем половины узлов-реплик в каждом центре обработки данных.
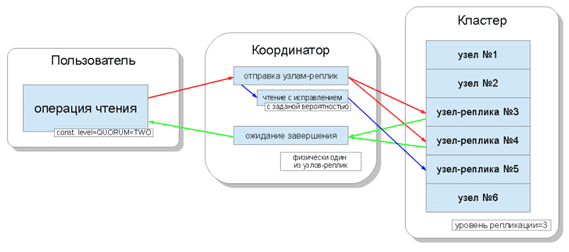
Согласованное чтение Big Data в Apache Cassandra
В случае чтения уровень согласованности определяет количество узлов-реплик, с которых будет считана информация [2]:
- ONE (1) — координатор шлёт запросы к ближайшему узлу-реплике, читая остальные с целью исправления (read repair) с заранее заданной в конфигурации вероятностью;
- TWO (2) — координатор шлёт запросы к двум ближайшим узлам, выбирая значение с большей меткой времени;
- THREE (3) — координатор шлёт запросы к трем ближайшим узлам, выбирая значение с большей меткой времени;
- QUORUM (4) — собирается кворум, то есть координатор шлёт запросы к более чем половине узлов-реплик, а именно round(N/2)+1, где N — уровень репликации;
- ALL (5) — координатор возвращает данные после прочтения со всех узлов-реплик;
- LOCAL_QUORUM (6) — собирается кворум узлов в том датацентре, где происходит координация, и возвращаются данные с последней меткой времени;
- EACH_QUORUM (7) — координатор возвращает данные после собрания кворума в каждом из датацентров.
Как уровни согласованности влияют на быстроту работы NoSQL СУБД
Подводя итог возможным уровням согласованности в Apache Cassandra, можно сделать следующие выводы [2]:
- QUORUM на чтение и на запись обеспечит строгую согласованность и баланс между временной задержкой на выполнение этих операций;
- strong consistency также будет достигнута при записи ALL, и чтении ONE. Однако, в этом случае данные будут считываться быстрее и с большей доступностью, поскольку количество отказавших узлов, при котором чтение все еще будет выполнено, может быть больше, чем при QUORUM. Для записи потребуются все рабочие узлы-реплик.
- Обратный случай (запись ONE, чтение ALL) тоже обеспечит строгую согласованность, но запись будет выполняться быстрее и с большей доступностью, т.к. потребуется подтверждение об успешном окончании операции лишь с одного узла. Чтение же, в этом случае, требует отклика от всех узлов-реплик и происходит медленнее.
- При отсутствии требований о строгой согласованности, можно ускорить операции чтения и записи, а также улучшить доступность за счет выставления меньших уровней согласованности.
По умолчанию для всех операций в Apache Cassandra используется уровень согласованности ONE. Отметим, что в ранних версиях этой NoSQL-СУБД задать уровень согласованности можно было прямо в самом CQL-запросе, например, так [3]:
SELECT * FROM users WHERE state=’TX’ USING CONSISTENCY QUORUM;
Однако, начиная с версии 1.2 (2012 год) разработчики убрали эту возможность, аргументируя тем, что согласованность операции должна устанавливаться не в рамках запроса, а на уровне протокола ее выполнения [3]. Таким образом, сегодня установить consistency level в Кассандре можно двумя следующими способами:
- изменить значение этого параметра в программном коде с использованием класса SimpleStatement, например, так [4]:
from cassandra import ConsistencyLevel
from cassandra.query import SimpleStatement
query = SimpleStatement(
«INSERT INTO users (name, age) VALUES (%s, %s)»,
consistency_level=ConsistencyLevel.QUORUM)
session.execute(query, (‘John’, 42))
- также можно указать необходимый уровень согласованности в следующей инструкции cqlsh, оболочки командной строки для взаимодействия с Cassandra через CQL [5]:
CONSISTENCY <consistency level>
Напомним, cqlsh поддерживает ряд специальных команд, которые не являются частью CQL, используя драйвер собственного протокола Python при подключении к узлу, указанному в командной строке [5].
В следующей статье мы подробнее расскажем, как именно выполняются процессы записи и считывания больших данных (Big Data) в Apache Cassandra с учетом рассмотренных уровней согласованности.
Источники
- https://ru.wikipedia.org/wiki/Теорема_CAP
- https://ru.bmstu.wiki/Apache_Cassandra
- https://issues.apache.org/jira/browse/CASSANDRA-4734
- https://wp.huangshiyang.com/cassandra-setting-a-consistency-level
- https://cassandra.apache.org/doc/latest/tools/cqlsh.html

