
Продолжая тему нереляционных хранилищ данных, сегодня мы поговорим о главных плюсах и минусах Apache Cassandra. Читайте в нашем материале, чем хороша эта отказоустойчивая распределенная NoSQL-СУБД и с какими проблемами можно столкнуться при ее использовании в реальном Big Data проекте.
Чем хороша Кассандра: 10 ключевых преимуществ
Начнем с положительных моментов. Благодаря своим архитектурным особенностям, Apache Cassandra характеризуется следующими достоинствами:
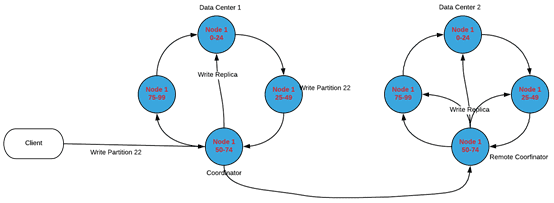
- масштабируемость и надежность в связи с отсутствием центрального сервера (Master Node), отказ которого может стать причиной сбоя всего кластера, как в случае HBase. Добавить новые узлы в кластер и обновить версии Cassandra можно на лету, без дополнительного ручного вмешательства и переконфигурации всего кластера. Однако, на практике рекомендуется заново сгенерировать ключи (токены) для каждого узла, включая существующие, чтобы сохранить качество распределения нагрузки. Генерации ключей для существующих узлов можно избежать в случае кратного увеличения количества узлов (дважды, трижды и т.д.) [1]. Также стоит отметить 3 механизма восстановления данных [2]:
- чтение с восстановлением (read repair), когда во время чтения данные запрашиваются со всех реплик и сравниваются после координации. Та колонка, которая имеет последнюю метку времени, распространится на узлы с устаревшими метками.
- направленная отправка (hinted handoff), которая сохраняет информацию об операции записи на координаторе даже если запись на каком-то узле не получилась. Потом, по возможности, эта запись вновь повторится. Такой механизм позволяет быстро восстановить данные в случае краткосрочного отсутствия узла в кластере. Кроме того, при уровне согласованности ANY он позволяет добиться полной доступности для записи (absolute write availability) даже при недоступности всех узлов-реплик – операция записи подтверждается, а данные сохранятся на узле-координаторе.
- анти-энтропийное восстановление узла (anti-entropy node repair) — регулярно запускаемый вручную процесс восстановления всех реплик, который позволяет восстановить данные, если они не были восстановлены двумя вышеописанными способами.
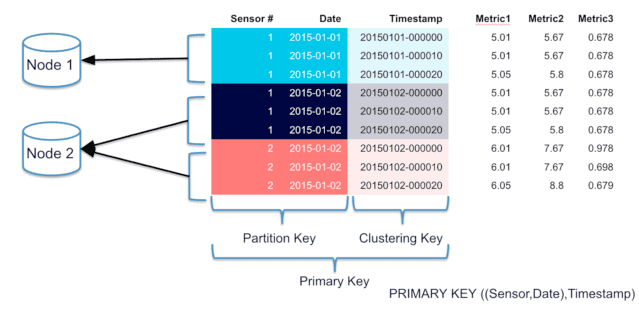
- гибкая схема данных, основанная на комбинации столбцовых семейств (Column Family) в пространство ключей (keyspace) [3], позволяя определять в строках одной и той же таблицы разные столбцы и таким образом эффективно хранить разряженные таблицы. При этом в одной таблице может быть до двух миллионов столбцов [4], что весьма актуально для Big Data систем.
- высокая пропускная способность, особенно для операций записи (около 80-360 МБ/с на узел) – благодаря хранению в оперативной памяти ответственного узла, данные записываются быстрее, чем считываются [3]. Кроме того, за счет использования LSM-деревьев, Сassandra также позволяет довольно-таки быстро считывать данные [4]. Напомним, LSM-дерево (Log-structured merge-tree, журнально-структурированное дерево со слиянием) – это структура данных, которая хранит пары «ключ — значение» и предоставляет быстрый доступ по индексу в условиях частых запросов на вставку, например, при хранении журналов транзакций [5].
- собственный SQL-подобный язык запросов (CQL, Cassandra Query Language), который позволяет выполнять простейшие запросы SELECT с выборкой по определённому условию. Добавление и обновление осуществляется через единое выражение UPDATE, операция INSERT отсутствует. Также CQL поддерживает пространство имён и семейств столбцов. Драйверы с поддержкой этого языка запросов реализованы для языков Python, Java, Ruby, PHP, JavaScript и Perl [1].
- наличие инструментов расширения функциональных возможностей – определенные пользователем типы данных (UDT, User Defined Types), начиная с версии 2.1, а в релизе 2.2 можно писать хранимые процедуры и агрегаты [4].
- поддержка поиска за счет вторичных индексов, создать которые можно с помощью CQL-выражения CREATE INDEX [1];
- настраиваемая согласованность и поддержка репликации, когда пользователи могут сами определить необходимое количество реплик и задать уровень согласованности данных по каждой операции хранения и [3]. В частности, при каждом чтении и записи клиент может указать желаемый уровень согласованности (консистентности) — ANY, ONE, TWO, THREE, QUORUM, SERIAL, ALL и другие. Например, используемый по умолчанию уровень ONE говорит, что запрос должен дойти хотя бы до одного узла, отвечающего за хранение строки, а QUORUM — что запрос должно получить большинство узлов, например, 2 из 3. Это позволяет выбирать между скоростью выполнения запросов и надежностью. Для большинства задач именно ONE является вполне подходящим уровнем согласованности [4].
- автоматическое разрешение конфликтов благодаря хранению временных меток (timestamp) для каждого столбца в любой записи. К примеру, если одновременно делаются два запроса на изменение значений разных столбцов одной записи, то возможен конфликт на узлах, отвечающих за хранение этой строки. Конфликт будет успешно разрешен по времени последнего изменения столбцов [4].
- поддержка аутентификации, ролей и работы с клиентом по защищенному криптографическому протоколу SSL [4].
- поддержка ACID-транзакционности на уровне одной записи, т.е. для набора столбцов с одним ключом [2]:
- Atomicity (атомарность) — все столбцы в одной записи за одну операцию будут записаны;
- Consistency (согласованность) — можно задать уровень строгой согласованности;
- Isolation (изолированность) — начиная с версии 1.1, появилась поддержка изолированности, когда во время записи столбцов одной строки другой пользователь, который читает эту же строку, увидит полностью старую версию записи или, уже после окончания операции, новую версию, а не часть колонок из одной и часть из второй;
- Durability (долговечность), обеспечиваемая наличием журнала фиксаций, который будет воспроизведён и восстановит отказавший узел кластера до нужного состояния.
5 основных недостатков Apache Cassandra
Главные минусы Кассандра, как и ее достоинства, обусловлены особенностями архитектуры этой нереляционной СУБД. В частности, среди наиболее существенных недостатков рассматриваемой системы, важных с точки зрения использования в Big Data проектах, отмечаются следующие:
- особенности внутреннего языка запросов – несмотря на некоторую схожесть с SQL, CQL значительно отличается от него. В частности, операции INSERT и UPDATE по сути это одно и то же. Также Cassandra не поддерживает операции соединения (JOIN). Для объединения двух семейств столбцов придется извлекать и объединять данные программным способом, что дорого и трудоемко для больших наборов данных. СУБД пытается обойти это ограничение, сохраняя как можно больше данных в одной и той же строке. Поэтому запросы, необходимые для приложения, должны быть определены в схеме данных [3].
- Высокие накладные расходы при работе с большими объемами данных – из-за SELECT-driven подхода к проектированию данных, необходима очень сильная денормализация, что предполагает фактическое создание отдельной таблицы под каждый запрос [6].
- Требования к уникальности ключей – каждый ключ, например, ключ строки и ключ столбца, должен быть уникальным в своей области действия. Если один и тот же ключ используется дважды, данные будут перезаписаны. Впрочем, эта проблема решается использованием составного ключа, который объединяет несколько полей или добавлением к ключу случайного значения или метки времени [3].
- Трудности с операцией поиска, которая не встроена в ядро архитектуры Cassandra, и механизмы поиска надстраиваются поверх него с помощью сортировки данных. Кассандра поддерживает вторичные индексы с несколько ограниченной функциональностью, которые система строит автоматически. Когда вторичные индексы не работают, пользователи должны знать модель данных и строить индексы самостоятельно с помощью сортировки и секционирования [3].
- Сложности с использованием типа данных «счетчик» (counter), который нельзя сортировать, индексировать и использовать в строке с ним какие-то другие типы данных. Напомним, в Cassandra значение столбца-счетчика – это 64-разрядное целое число со знаком, которое поддерживает две операции: увеличение и уменьшение запрос [6].
В следующей статье мы расскажем о согласованности данных в Apache Cassandra и варианты настройки этого параметра.
Источники

