В прошлой статье мы разобрали, как настраиваемые уровни согласованности влияют на скорость работы с данными в Apache Cassandra. Сегодня поговорим, как в этой нереляционной базе данных выполняются операции записи, чтения, уплотнения и удаления. Читайте в нашей статье, что такое memTable, SSTable и Bloom-фильтр, благодаря которым рассматриваемая распределенная NoSQL-СУБД может обработать массивы Big Data еще быстрее.
Операция записи Big Data в NoSQL-СУБД Кассандра
Данные записываются в Cassandra таким образом, чтобы обеспечить полную надежность и высокую производительность. Напомним, запись в Кассандре намного быстрее считывания, несмотря на несколько этапов выполнения этой операции [1]:
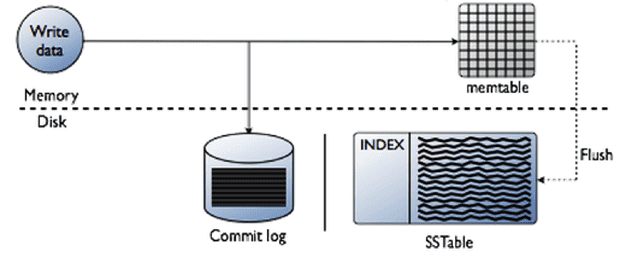
- Когда данные приходят после координации на узел непосредственно для записи, сначала записываются в журнал фиксации (commit log). Журнал фиксаций представляет собой последовательность операций модификации и является единым на всё пространство ключей. Он сохраняется на диске и разбивается на части при достижении определённого размера. Это позволяет гарантировать долговечность данных (data durability). При запуске узла после его сбоя (аварийного останова) журнал фиксаций читается при старте, восстанавливая все таблицы в памяти. Чтобы ускорить восстановление, рекомендуется хранить журнал фиксаций вынести на отдельном дисковом носителе [1].
- После попадания в журнал фиксаций, информация записывается в специальную таблицу в памяти (memtable), которая существует для каждого колоночного семейства и позволяет запомнить значение моментально. По сути, memtable – это хеш-таблица (hashmap) с возможностью одновременного доступа (concurrent access) на основе структуры данных, называемой «список с пропусками» (skip list) [1]. Эта вероятностная структура данных основана на нескольких параллельных отсортированных связных списках. Она эффективна благодаря расширению отсортированного связного списка дополнительными связями, добавленными в случайных путях с геометрическим/негативным биномиальным распределением, так, чтобы при поиске быстро пропускать части этого списка. Вставка, поиск и удаление выполняются за логарифмическое случайное время, что повышает быстродействие системы [2].
- Когда размер memtable превысит настраиваемое пороговое значение (параметр memtable_total_spacein_mb, по умолчанию равный ⅓ максимального размера кучи Java, heapspace), данные записываются в неизменяемый файл на диске, называемый SSTable (Sorted Strings Table) [1]. SSTable выполняет функцию долговременного хранилища полезных данных. Для каждой SSTable создается индекс раздела (partition index), сводка раздела (partition summary) и Bloom-фильтр – вероятностная структура данных, показывающая возможность нахождения нужной записи в определенной таблице [3].
- После сохранения SSTable части журнала фиксаций помечаются как свободные, таким образом освобождая занятое место на диске. Но, поскольку журнал фиксаций имеет сложную структуру из данных разных колоночных семейств в пространстве ключей, какие-то его части не освобождены, т.е. некоторым областям будут соответствовать другие данные, все ещё находящиеся в memTable [1].
Таким образом, для одной таблицы логических данных Cassandra может существовать множество SSTable. Буферизация строк в памяти с помощью memtable позволяет выполнять запись всегда как полностью последовательную операцию, когда дисковый ввод-вывод происходит одновременно, а не множество мелких действий за длительный период времени. Этим обусловлена высокая скорость записи в Cassandra [4].
Как Apache Cassandra читает данные
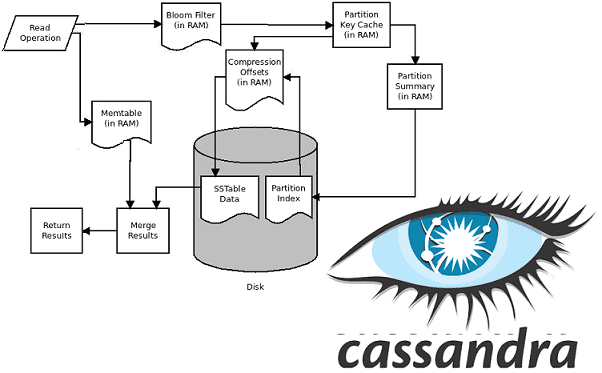
Как мы уже описали выше, каждому семейству столбцов соответствует одна таблица в памяти (memtable) и несколько сохранённых на диск таблиц (SSTable). Когда узел обрабатывает запрос на чтение данных, ему необходимо просмотреть все эти структуры и выбрать самое последнее по метке времени значение. Для ускорения этого процесса существует 3 механизма [1]:
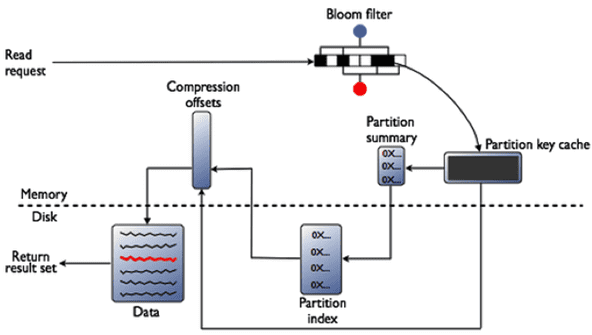
- блум-фильтр (bloom filter), который позволяет ответить на вопрос, содержит ли рассматриваемая таблица искомый ключ, благодаря чему можно уменьшить количество читаемых SSTable и сократить время выполнения процесса;
- кэш ключей (key cache), сохраняющий позицию на диске при записи для каждого ключа, что уменьшает количество операций позиционирования (seek operations) во время поиска по сохранённой таблице;
- кэш записей (record cache), который сохраняет запись целиком, позволяя совсем избавиться от операций чтения с диска.
Таким образом, при чтении Cassandra сперва обращается к Bloom-фильтру, который проверяет вероятность наличия в SSTable необходимых данных. Если Bloom-фильтр отвечает, что файл SSTable, вероятно, содержит необходимые данные, то СУБД просматривает кэши ключей и записей, а затем извлекает сжатые данные на диск. При отрицательном ответе Bloom-фильтра Кассандра переходит к следующему файлу SSTable [4]. Чтобы ускорить считывание, несколько SSTable объединяются в одну таблицу в рамках процесса уплотнения или сжатия (compaction), который рассмотрен далее.
Удаление и уплотнение
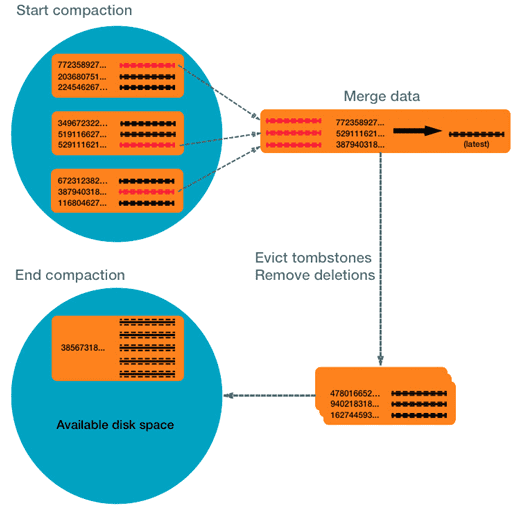
Cassandra, как и Apache HBase, использует операцию уплотнения или сжатия (compaction) данных для оптимизации дискового пространства путем уменьшения числа сохраненных таблиц и окончательного удаления данных, помеченных на удаление с помощью специальной метки (tombstone). При этом вместо удаления выполняется перезапись, затирая устаревшую информацию новыми данными. Если при чтении попадется колонка с меткой tombstone, этот столбец будет пропущен, словно такого значения никогда и не существовало. Таким образом, со временем столбцы, помеченные меткой tombstone, будут затерты данными с более свежими метками времени (timestamp) [1].
Кроме перезаписи устаревшей информации, Кассандра использует операцию уплотнения, чтобы предупредить расхождение данных, сохраненных на разных узлах в рамках децентрализованной архитектурой этой СУБД. Чтобы гарантировать целостность, Cassandra читает все SSTable на каждом узле кластера, выбирая данные с последней меткой времени (timestamp). Так количество операций позиционирования жёсткого диска при чтении пропорционально количеству сохранённых файлов SSTable [1].
В процессе уплотнения последовательно читается сразу несколько сохранённых таблиц и записывается новая SSTable, в которой объединены данные по меткам времени. Когда новая таблица полностью записана и введена в использование, СУБД может освободить таблицы-источники, которые образовали новую SSTable, устраняя избыточность перезаписанных данных. Однако, непосредственно во время операции уплотнения объем избыточности увеличивается, т.к. новая SSTable располагается на диске вместе с уже существующими таблицами. Поэтому для запуска compaction-операций необходимо дополнительное место на диске [1].
Как и Apache HBase, Кассандра реализует 2 стратегии уплотнения, которые отличаются друг от друга спецификой сжатия [1]:
- size-tiered compaction, позволяющее уплотнять конкретные две SSTable автоматически в фоновом режиме (minor compaction) или вручную для полного уплотнения (major compaction). С учетом возможности нахождения ключа во многих таблицах, эта стратегия требует выполнять операцию его поиска для каждой SSTable, выбранной для сжатия.
- уплотнение сохраненных таблиц уровнями (leveled compaction), в рамках которой сжимаются небольшие SSTable (порядка 5 МБ). Такие таблицы сперва группируются в уровни, каждый из которых в 10 раз больше предыдущего. При этом 90% запросов чтения происходит к одной SSTable, и лишь оставшиеся 10% дискового пространства будут использоваться под устаревшие данные. В этом случае для уплотнения под временную таблицу достаточно только 10-кратного размера исходной SSTable, то есть около 50 Мб.
В следующей статье мы рассмотрим несколько примеров практического использования Apache Cassandra в реальных Big Data проектах.
Источники
- https://ru.bmstu.wiki/Apache_Cassandra
- https://ru.wikipedia.org/wiki/Список_с_пропусками
- https://blog.bissquit.com/dbms/apache-cassandra/apache-cassandra-zapis-dannyh-chast-3-sstable/
- https://medium.com/@makersu/cassandra-writing-and-reading-data-8a15bf3867cd

