Чтобы сделать обучение разработчиков Apache Spark, дата-аналитиков и инженеров Big Data еще более наглядным, сегодня рассмотрим проблему JOIN-соединений при неравномерном распределении данных по узлам кластера и способы ее решения. Читайте далее, как избавиться от перекосов и ускорить выполнение SQL-запросов в Spark-приложениях.
Перекосы данных в Apache Spark: что это и чем опасно
Проблема перекоса или неравномерного распределения данных по узлам кластера характерна для любой распределенной системы. В приложениях Apache Spark это влияет на скорость обработки данных и особенно заметно при выполнении таких операций, как соединения таблиц (JOIN). Подобные SQL-запросы выполняются достаточно медленно и существенно замедляют работу всего приложения, о чем мы упоминали здесь. Исправить это можно, равномерно перераспределив большой набор данных между доступными worker’ами, одновременно отправив меньший из соединяемых наборов всем рабочим узлам, предварительно отсортировав его по столбцам для консолидации данных.
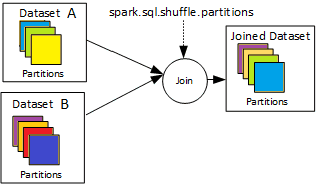
Таким образом, решение проблемы перекоса в Apache Spark сводится к следующим способами [1]:
- равномерное перераспределение большого набора данных, число разделов зависит от доступных ресурсов;
- широковещательная передача (broadcasting) отсортированного меньшего набора данных, который можно еще более сократить, ограничив количество атрибутов.
По умолчанию Apache Spark использует Hash Partitioner для разделения данных по разным разделам, чтобы обрабатывать их параллельно. Hash Partitioner работает с концепцией использования функции hashcode(), суть которой одном и том же хэш-коде для одинаковых объектов. Hash Partitioner разделяет ключи с одинаковым хэш-кодом и распределяет их по разделам [2]. Перераспределить большой набор данных можно следующими методами:
- DataFrame.repartition(numPartitions,*cols) – возвращает новый DataFrame, разделенный по хешу. Целочисленный параметр numPartitions указывает целевое количество разделов или столбец для разделения. По умолчанию используется количество разделов. Строковый параметр *cols задает столбец, по которому нужно разделить данные [3].
- Custom Partitioner — пользовательский перераспределитель RDD, который может быть применен только к PairedRDD, полученного из исходного RDD. Для реализации этого метода разработчику Spark необходимо расширить класс apache.spark.Partitioner, чтобы переопределить метод numPartitions, возвращающий количество разделов для RDD, и getPartition(key: Any), который возвращает номер раздела, куда должен перейти ключ (от 0 до nnumberOfPartitions-1). Пользовательское разбиение на разделы позволяет менять размер и количество разделов в соответствии с потребностями конкретного Spark-приложения. Разработчик может определить, какой ключ должен входить в какой раздел, используя явный разделитель через вызов метода partitionBy() для парного RDD. Этот способ предоставляет больше свободы, однако, требует более глубоких знаний Apache Spark.
Стратегия перераспределения зависит от характера данных и специфики предметной области. Сегодня чаще всего используется более высокоуровневый DataFrame API, чем RDD.Также можно оптимизировать использование ресурсов кластера, настроив соотношение исполнителей и количества ядер CPU [1]. Из готовых методов, предоставляемых фреймворком, для перераспределения данных чаще всего используются coalesce() и repartition(). Как они работают и чем отличаются, мы рассмотрим далее.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
13 мая, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Coalesce vs Repartition: что и когда выбирать для перераспределения данных
Метод repartition() в Spark используется для увеличения или уменьшения разделов в датасете. Выполняется полное перемешивание данных и создаются разделы одинакового размера. Этот метод не пытается сократить перемещение данных, в отличие от сoalesce(), который объединяет существующие разделы, чтобы избежать полного перемешивания. Coalesce() создает разделы разных размеров, т.е. с разным объемом данных. Чтобы продемонстрировать отличия методов coalesce() и repartition(), рассмотрим небольшой пример, полностью приведенный в источнике [4].
Создадим датафрейм из чисел от 1-го до 10.
val x = (1 to 10).toList
val numbersDf = x.toDF(“number”)
Датафрейм разделен на 4 раздела:
Partition A: 1, 2
Partition B: 3, 4, 5
Partition C: 6, 7
Partition D: 8, 9, 10
Уменьшим количество разделов до 2-х, объединив их с помощью метода coalesce():
val numbersDf2 = numbersDf.coalesce(2)
В результате применения метода coalesce() данные из раздела B перемещены в раздел A, а из раздела D – в раздел C. Исходные данные из разделов A и раздела C остались на месте. Этот метод работает быстро в некоторых случая, сводя к минимуму перемещение данных.
Partition A: 1, 2, 3, 4, 5
Partition C: 6, 7, 8, 9, 10
Метод coalesce() изменяет количество узлов, перемещая данные из одних разделов в другие, но он не может увеличить количество разделов, т.е. повысить уровень параллелизма в кластере Apache Spark.
Теперь применим к исходному набору данных метод repartition(), создав новый датафрейм:
val homerDf = numbersDf.repartition(2)
Результат будет выглядеть следующим образом:
Partition ABC: 1, 3, 5, 6, 8, 10
Partition XYZ: 2, 4, 7, 9
Теперь раздел ABC содержит данные из разделов A, B, C и D. Раздел XYZ также содержит данные из каждого исходного раздела. Выполнено полное перемешивание данных, которые равномерно распределены по разделам. С помощью этого метода можно увеличить количество разделов, уровень параллелизма в кластере Apache Spark. Например, зададим большее число разделов, создав новый датафрейм из исходного с помощью метода repartition():
val bartDf = numbersDf.repartition(6)
Результат будет выглядеть так:
Partition 00000: 5, 7
Partition 00001: 1
Partition 00002: 2
Partition 00003: 8
Partition 00004: 3, 9
Partition 00005: 4, 6, 10
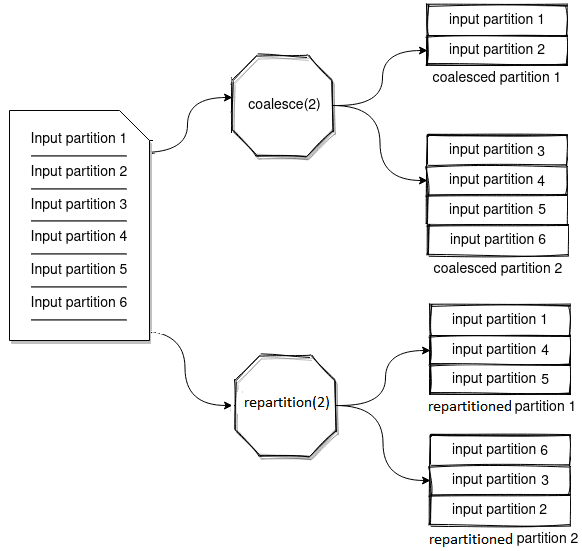
Таким образом, выбирая между repartition() и coalesce(), стоит учитывать, нужно ли полное перемешивание данных с перераспределением по узлам или достаточно простого объединения нескольких разделов. Чем эти методы отличаются от parttionBy(), читайте в нашей новой статье.
Больше подробностей про возможности Apache Spark для разработки распределенных приложений аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- https://npntraining.medium.com/data-skew-problem-in-spark-4b5ca6c8cd3b
- https://blog.clairvoyantsoft.com/custom-partitioning-spark-datasets-25cbd4e2d818
- https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.sql.DataFrame.repartition.html
- https://mrpowers.medium.com/managing-spark-partitions-with-coalesce-and-repartition-4050c57ad5c4

