В продолжение разговора о применении технологий Big Data и Machine Learning в рекламе и маркетинге, сегодня рассмотрим архитектуру системы прогнозирования конверсии рекламных объявлений. Читайте далее, как организовать предиктивную аналитику больших данных на Apache Kafka и компонентах ELK-стека (Elasticsearch, Logstash, Kibana), почему так важно тщательно подготовить данные к машинному обучению, какие функции PySpark помогают сделать это и на что обратить внимание при настройке Spark-кластера.
Строим систему потоковой аналитики Big Data на Apache Kafka и Kibana через Logstash и Elasticsearch
Начнем с постановки задачи: требуется спрогнозировать конверсию рекламных объявлений, т.е. вычислить CTR-рейтинг (click through rate) или показатель кликабельности. Эта важная метрика эффективности интернет-маркетинга определяет отношение числа кликов на рекламное объявление к числу показов и измеряется в процентах. К примеру, если реклама была показана 10 раз и на нее кликнули 2 раза, то CTR равен 20 %, что считается весьма чрезвычайно высоким значением. Обычно CTR рекламных кампаний в Рунете колеблется от 0,01% до 2%, максимум 10%. Не стоит путать CTR с метрикой CR (conversion rate, рейтинг конверсии), обозначающей процент пользователей, которые не только прошли по ссылке, но и совершили покупку, чтоб более значимо для бизнеса [1].
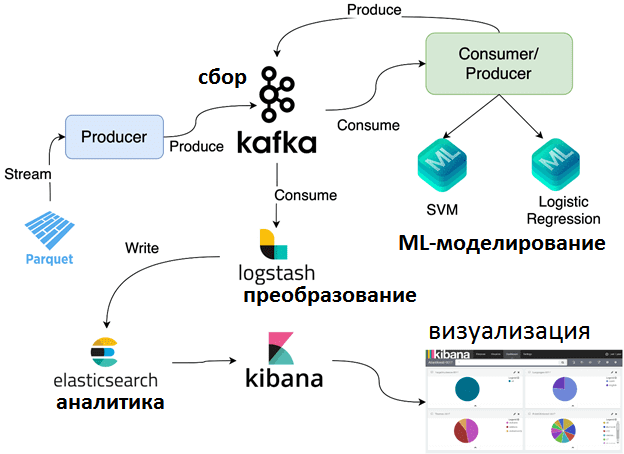
За непрерывный сбор и агрегацию потоковых данных для ML-модели отвечает Apache Kafka – популярная платформа потоковой обработки событий. Обучение алгоритмов Machine Learning проводится на обучающем и тестовом датасетах, которые после предварительной подготовки к моделированию, о чем мы поговорим далее, упакованы в файлы формата Parquet. Далее вся ML-система работает следующим образом [2]:
- издатели или продюсеры (producer) данных отправляют их в топики Kafka в потоковом режиме. Например, с помощью библиотеки PyArrow можно считать данные из Parquet-файла. Затем producer добавляет метку, которая обозначает класс решения для алгоритма классификации и предикторы или фичи (от англ. feature) для вычисления таргетной переменной (CTR).
- Потребитель данных из топиков Kafka считывает метку и столбец с фичами для ML-и логистической регрессии и машины опорных вектором (SVM, Support Vector Machine). Далее столбец фичей преобразуется из разреженного вектора в плотный вектор. 2 разных ML-модели используются для прогнозирования метки класса из столбца входных фичей.
- Producer записывает в Kafka полученный после ML-моделирования прогноз вместе с исходной меткой и оценкой корректности результата, например, 1 означает, что прогноз модели и исходная метка совпадали, иначе – 0.
- Logstash считывает прогноз вместе с исходной меткой и правильным значением из топика Kafka, преобразует их в JSON-формат и записывает их в NoSQL-СУБД Elasticsearch.
- Elasticsearch обеспечивает возможность быстрой аналитики по хранящимся в ней JSON-документам и визуализацию результатов в веб-интерфейсе Kibana.
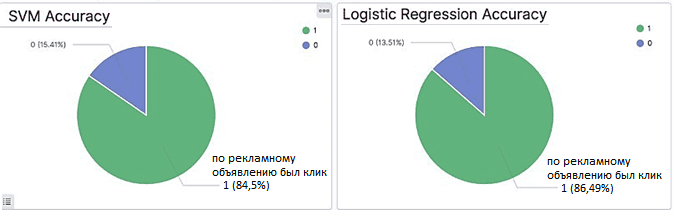
Мощные возможности Kibana по визуализации позволяют оценить эффективность каждой ML-модели с помощью настраиваемых информационных панелей или дэшбордов. Например, можно создать круговые диаграммы, которые показывают процент количества правильных прогнозов для каждой ML-модели и оперативно обновляются в соответствии с поступающими потоковыми данными. В частности, логистическая регрессия оказалась точнее, чем SVM-модель [2].
Об обучении ML-модели и подготовке данных к моделированию c Apache Spark
Поскольку машинное обучение требует предварительной подготовки данных (Data Preparation) к ML-моделированию, важно провести все соответствующие процедуры очистки, нормализации и форматирования исходных значений, о чем мы подробно рассказывали здесь. В качестве обучающего датасета в рассматриваемом примере использовался Criteo – набор данных по онлайн-рекламе, выпущенный Criteo Labs. Он содержит значения фичей и кликов для миллионов рекламных объявлений. Каждое объявление имеет фичи, описывающие данные. В датасете 40 атрибутов, включая метку классификации, где значение 1 означает, что на объявление кликали, а 0 – нет. Атрибуты состоят из 13 целочисленных столбцов и 26 категориальных столбцов. Переформатирование датасета в столбцовый формат Parquet позволяет обрабатывать данные намного быстрее, чем исходный формат CSV.
При том, что датасет Criteo позиционируется как набор данных для машинного обучения, он содержит много ошибок, пропусков и некорректных значений. Например, из 45 840 617 записей количество кликов по рекламе составляет около 26%, а остальные 74% данных не имеют отношения к CTR. Из 39 столбцов 24 содержат нулевые значения с разными процентными значениями, причем сразу 2 колонки (с целочисленнами и категориальными значениями) содержат более 75% null. Такие данные не могут считаться корректными и не должны входить в обучающий датасет для Machine Learning. С оставшимися столбцами были выполнены следующие преобразования [3]:
- для столбцов, где нулей или пропусков менее 40% были вычислены средние значения;
- рассчитаны выбросы для каждого целочисленного столбца в зависимости от его межквартильного размаха;
- null и выбросы в каждом столбце заменены средними значениями;
- строки категориальных столбцов преобразованы в индексы с помощью функции StringIndexr();
- определена размерность каждого столбца, описывающая количество значений в нем.
Все эти преобразования были выполнены с использованием функций PySpark и записных книжек DataBricks. Например, встроенный Bucketizer() из пакета pyspark.ml.feature использовался для разделения целочисленных столбцов, StringIndexr() – для индексации категориальных столбцов, OneHotEncoder() для кодирования категориальных столбцов с низкой размерностью и VectorAssembler() для объединения соответствующих столбцов в один столбец фичей. Подробности применения этих функций с примерами кода на Python можно посмотреть в источниках [3, 2].
После подготовки данных к ML-моделированию, датасет из двух столбцов с метками и фичами был разделен на набор для тестирования (25%) и набор для обучения (75%) модели Machine Learning. Обученные алгоритмы машинного обучения показали следующую точность на тестовом наборе данных [3]:
- логистическая регрессия — 72%;
- случайный лес — 74%;
- линейный SVM – 70%.
Благодаря настройке гиперпараметров, удалось повысить точность моделей, например, для случайного леса — 78%, при значениях 50 деревьях (numTrees= 50) с максимальной глубиной 20 (maxDepth). Поэкспериментировать с параметрами можно с помощью поиска по сетке в sklearn, который в Apache Spark называется ParamGridBuilder(). В частности, стоит убедиться, что maxDepth не выше 30, т.к. фреймворк не поддерживает большую глубину. Также стоит обратить внимание на корректную конфигурацию кластера, особенно достаточный объем оперативной памяти. К примеру, при обучении ML-модели с параметром maxDepth>20, размер RAM на вычислительном узле должен быть более 32 ГБ. Наконец, время обучения увеличивается в зависимости от размера данных: обучение модели случайного леса с numTrees=50 и maxDepth=20 может занять более 2 часов на кластере из 16 машин m5.2xlarge (32 ГБ, 8 ядер) [3].
Другой подобный кейс построения ML-системы аналитики больших данных в реальном времени на аналогичных Big Data технологиях читайте в нашей новой статье. А практические примеры разработки приложений машинного обучения и потоковой аналитики больших данных с Apache Spark и Kafka вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Аналитика больших данных для руководителей
- Подготовка данных для Data Mining на Python
- Машинное обучение в Apache Spark
- Apache Kafka для разработчиков
Источники
- https://ru.wikipedia.org/wiki/CTR_(Интернет)
- https://medium.com/swlh/ml-model-prediction-on-streaming-data-using-kafka-ae7e46d2bf10
- https://medium.com/swlh/preprocessing-criteo-dataset-for-prediction-of-click-through-rate-on-ads-7dee096a2dd9

