
В недавней статье про современные архитектуры данных мы упоминали Data Fabric и Data Mesh. Сегодня поговорим про эти стратегии Data Governance более подробно: разберем их главные достоинства и недостатки, основные сходства и принципиальные отличия, ключевые вызовы и технологии реализации, а также возможности совместного применения на практике.
Что такое Data Fabric
Согласно глоссарию DAMA DMBOK2, архитектура данных определяет план управления активами данных в соответствии со стратегией организации по установлению стратегических требований к данным и проектам, отвечающим этим требованиям. Как и остальные области знаний фреймворка DAMA DMBOK2, архитектура данных обеспечивает управление ими (Data Governance).
В этой статье мы рассмотрим 2 популярные сегодня архитектурные модели управления данными: Data Fabric и Data Mesh. Они фокусируются прежде всего не на технических, а на организационных моментах, поэтому в переводе их названий на русский язык вполне уместны материальные метафоры. В частности, смысл термина Data Fabric лучше всего иллюстрирует выражение «ткань данных», которая окутывает всю организацию, обеспечивая беспрепятственный доступ к данным и их обработку. Впервые это понятие прозвучало в 2015 году, а через 5 лет аналитическое бюро Gartner внесло Data Fabric в ТОП-10 главных трендов 2020 года в области аналитики данных. Эта согласованная архитектура управления даннымивключает целую экосистему, которая объединяет повторно используемые сервисы производства данных, конвейеры их передачи и обработки, а также API-интерфейсы и другие подходы к интеграции данных между различными системами и хранилищами для беспроблемного доступа и обмена данными в распределенной среде.
Платформы Data Fabric стремятся снизить разрозненность данных, создавая виртуализированные уровни доступа, логически объединяя их через центральный орган, который может управлять данными, регулировать их и приводить в соответствие с корпоративными стандартами. Однако, не стоит путать Data Fabric с виртуализацией данных: в отличие от Fabric, платформа виртуализации не хранит данные, поэтому сталкивается с проблемами в стратегии модернизации приложений.
Можно рассматривать Data Fabric как набор сервисов, которые обеспечивают согласованные возможности для выбора конечных точек, охватывающих гибридные многооблачные среды. Это мощная архитектура стандартизирует методы и практические аспекты управления данными в облаке, в локальной среде и на периферийных устройствах, обеспечивая видимость и анализ данных, контролируемый доступ к ним, защиту и безопасность.
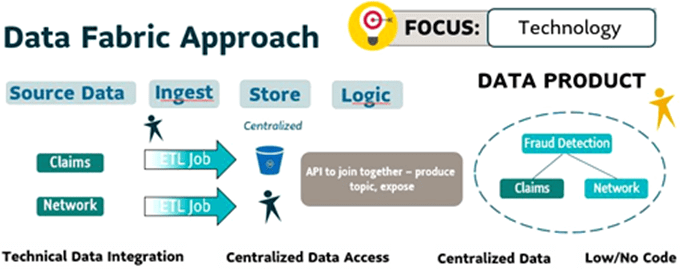
На практике идея Data Fabric воплощается в создании уровня технической интеграции и обеспечении централизованного доступа к данным через Low-code/No-code подход с применением совмеременных инструментов и технологий Big Data. В реальности это чаще всего реализуется в виде коммерческой платформы данных, которая гибко адаптируется к инфраструктуре клиента. Например, Arenadata Enterprise Data Platform, Cloudera Data Platform и т.д.
Такая архитектурная модель не описывает многие организационные моменты Data Governance: процессы, владение данных, а также роли и обязанности тех, кто создает эти информационные активы. В итоге сам поток управления данными, по сути, не учитывается, что напрямую приводит к низкому доверию к данным. В фокусе Data Fabric находятся технологии. Пример использования этого подхода к созданию системы обнаружения мошенничества можно представить так:
- создать ETL-задание для получения исходных данных по претензиям клиентов;
- собирать и хранить данные в централизованном репозитории;
- создать API с логикой для соединения таблиц и добавления правил на этот уровень.
Как устроен Data Mesh
Data Mesh или «сетка данных» возникла позже вышерассмотренного подхода и стала популярной примерно с 2019 года. Эта модель представляет собой децентрализованную по разным доменам архитектуру данных 4-го поколения, которая имеет централизованное управление и единые стандарты, обеспечивающие интегрируемость данных, а также централизованную инфраструктуру, с возможностью использования в режиме самообслуживания. Data Mesh активно использует потоковую и пакетную парадигмы обработки данных, транслируя децентрализованный подход, когда различные наборы данных должны полностью управляться отдельными командами в разных бизнес-областях. При этом продукты данных каждой доменной команды должны быть обнаруживаемыми, совместимыми, безопасными, надежными и обладать самоописываемой семантикой и синтаксисом.
Принципы сетки данных таковы:
- предметно-ориентированное, децентрализованное владение данными и архитектура – данные локально принадлежат команде, ответственной за их сбор и/или потребление;
- данные рассматриваются как продукт;
- инфраструктура самообслуживания данных представляет собой платформу;
- управление вычислительными ресурсами является федеративным.
Вышерассмотренный пример с применением подхода Data Mesh к созданию системы обнаружения мошенничества будет выглядеть так:
- определить команду домена, которая будет нести ответственность за работу над созданием ETL/ELT-заданием;
- каждый набор данных домена хранится отдельно и имеет владельца;
- копия каждого набора данных используется для доставки продукта данных;
- владелец продукта данных несет ответственность за написание логики для объединения всех наборов данных.
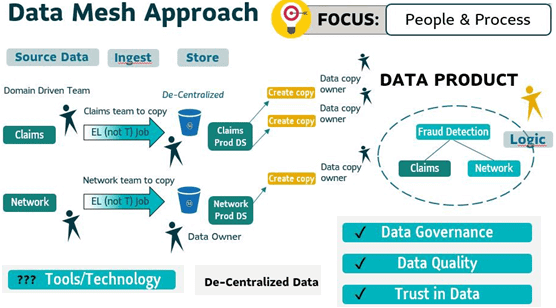
Таким образом, в подходе Data Mesh с самого начала определяется право собственности на данные, а ответственность владельца домена указывается на каждом процессе. Это поддерживает управление данными, создавая надежное доверие к ним. Можно сказать, что главный фокус сетки данных полностью посвящен людям и процессам, что мы рассматриваем в новой статье. Но инструменты и технологии, поддерживающие этот подход, пока находятся в стадии разработки. Впрочем, весной 2022 года Google выпустила движок BigLake, который реализует некоторые принципы Data Mesh, о чем мы рассказываем здесь.
Облака, Data Fabric и Data Mesh: взболтать, но не смешивать
Архитектуру данных и модели управления ими нельзя рассматривать в отрыве от контекста, т.е. операционных и организационных особенностей предприятия. Дизайн платформы данных закладывает основу цифровой трансформации, включая изменение организационной культуры. Поэтому данные организуются согласно доменно-ориентированному проектированию (Domain-Driven Design, DDD). Чтобы взять лучше из вышерассмотренных подходов Data Fabric и Data Mesh, разберем, возможно ли совместить централизованную структуру с автономией для конечного пользователя на базе облачных технологий.
Например, шина событий собирает данные и предоставляет их нескольким потребителям. API данных позволяют обмениваться данными. Реализовать это можно с помощью основанной на событиях микросервисной архитектуре, например, на базе Apache Kafka. В качестве объектного безопасного хранилища данных может выступать AWS S3, который обеспечивает легкий доступ к данным на всех уровнях потребления. Операционные данные собираются через пакетные и потоковые ETL-конвейеры на AirFlow и NiFi соответственно. А исторические транзакционные данные собираются и сохраняются для использования в аналитических моделях данных.
Интеграция уровня основных и эталонных данных является одним из ключевых факторов, позволяющих уменьшить проблемы с качеством данных в операционных и аналитических наборах данных. Для управления многодоменного управления данными нужна соответствующая модель MDM.
Аналитическая платформа использует очищенные данные для создания моделей данных, используемых BI и другими потребителями согласно принципам Data Mesh. Вместо федеративного управления данными нужны нестандартные децентрализованные способы организации мониторинга, отслеживания происхождения и качества данных. Сбор метаданных по всей платформе данных управляет отслеживаемостью данных.
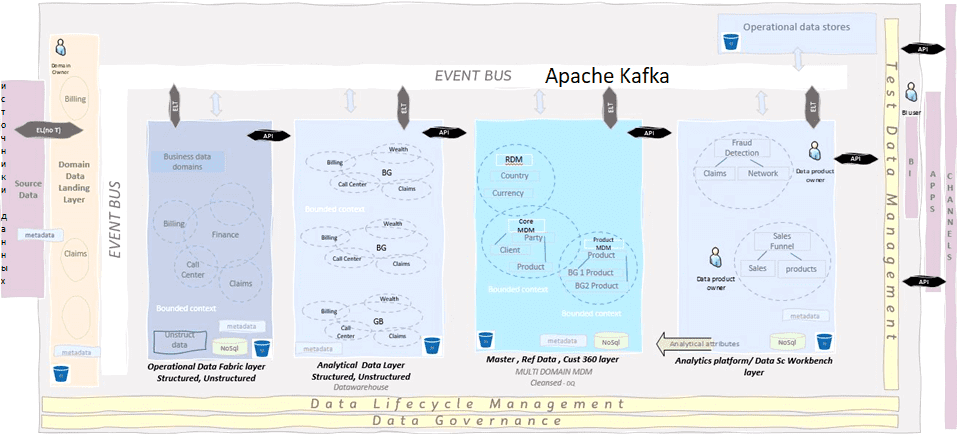
При практической реализации этой идеи архитекторы и дата-инженеры столкнутся со следующими вопросами и проблемами:
- как перенести/перестроить локальные операционные данные (структурированные и неструктурированные), вычислительные и аналитические хранилища конечных пользователей в облако?
- как найти баланс между пакетной и потоковой передачей данных, удовлетворяя требования бизнеса к быстрой поставке результатов?
- как интегрировать качество данных в облачную платформу данных?
- как обеспечить легкий доступ к данным с помощью федеративной модели безопасности? Этот вопрос рассматривается в нашей новой статье.
- как облачная платформа контролирует устойчивое производство и потребление данных?
- как быстро развернуть и доставить тестовые данные, если тестирование и развертывание аналитических моделей основано на традиционных тестовых средах?
- как управлять сквозным циклом создания и уничтожения данных, чтобы контролировать операционные риски и вести аудит?
- как бороться с отсутствием структуры и организации данных, а также их дублированием и расхождением в нескольких системах? Разрозненные модели данных приводят к интенсивной очистке данных на различных уровнях проектов, которые невозможно масштабировать или повторно использовать.
- как перейти от устоявшегося централизованного управления данными к контролируемой децентрализации, т.е. управлять данными, их владением, организацией по командам, проектам или функциям, чтобы обеспечить самостоятельную серверную аналитику?
В заключение остается открытым главный вопрос: сможет ли облачная платформа удовлетворить все варианты использования? В большинстве случаев реляционные модели в облаке не удовлетворяют потребности в расширенной аналитике по сравнению с NoSQL. А количество типов исходных и выходных данных растет быстрее, чем число готовых коннекторов к существующим системам. Наконец, дизайн озеро данных обычно основан на одноуровневой модели безопасности данных, используемой только для жизненных циклов производства. А большая часть аналитики данных является экспериментальной, поэтому такая модель безопасности затрудняет доступ к реальным данным и их исследования. Как безопасный протокол обмена данными Delta Lake От Databricks пытается решить эти проблемы, читайте в нашей новой статье.
Как научиться выбирать наиболее подходящую архитектуру для своего проекта хранения и аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

