
Чтобы сделать наши курсы по Apache Flink еще более полезными для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных, сегодня разберем, как работают источники данных потоковой обработки на примере топиков Kafka.
Источники данных в Apache Flink
Наряду с Apache Spark, Flink также является популярным фреймворком пакетной и потоковой обработки данных в реальном времени. Он обеспечивает отказоустойчивость за счет механизма контрольных точек, о чем мы писали здесь. При включенных контрольных точках Flink будет периодически сохранять состояние приложения во встроенную NoSQL-базу данных RocksDB или файловую систему HDFS. Однако, как и Spark, Flink выполняет роль вычислительного движка, а не хранилища данных. Источником данных для Flink могут быть реляционные или нереляционные базы, файловые системы или топики Apache Kafka. Некоторые источники данных, например, KafkaSource используют контрольные точки для фиксации смещения. В частности, KafkaSource считывает поток из Kafka и отправляет его далее по конвейеру обработки данных, не фиксируя смещение до тех пор, пока Flink не завершит контрольную точку, чтобы гарантировать, что данные считаны и успешно обработаны.
Изначально Apache Flink имеет устаревшие полиморфные интерфейсы SourceFunction и RichSourceFunction, которые помогают создавать простые непараллельные и параллельные источники. Разработчику следует реализовать метод запуска и собрать входные данные. Следующий пример Java-кода показывает, как создать источник данных Flink, используя интерфейсы SourceFunction и RichSourceFunction.
import org.apache.flink.streaming.api.functions.source.{RichParallelSourceFunction, SourceFunction}
class RichIntSource extends RichParallelSourceFunction[Long] {
override def run(sourceContext: SourceFunction.SourceContext[Long]): Unit = {
while (true) {
val numberOfTasks = this.getRuntimeContext.getIndexOfThisSubtask
(0 to numberOfTasks).foreach(_ => {
sourceContext.collect(System.currentTimeMillis())
Thread.sleep(10)
})
Thread.sleep(100)
}
}
override def cancel(): Unit = ???
}
Под капотом любой источник данных Flink состоит из трех основных компонентов:
- SplitEnumerator – ключевая часть источника, которая распределяет задачи (разделения) по SourceReaders, ведет статистику и отслеживает SourceReaders, работая как один экземпляр. Он генерирует разделения и назначает их считывателям, а также отвечает за сохранение незавершенных операций разделения и их сбалансированное назначение.
- SourceReader — это рабочий объект источника данных, который читает файлы, прослушивает службу HTTP или генерирует некоторые данные. SourceReader выполняет работу с директивами Splits. SourceReader запрашивает разделы и обрабатывает их, например, читая файл или раздел журнала, представленный разделом. Считыватели работают параллельно в диспетчерах задач в операторах источника данных и создают параллельный поток событий/записей.
- Split — наименьшая часть источника, которая содержит часть информации или данных, чтобы дать директивы SourceReaders — путь к файлу, диапазон и пр, что можно сериализовать. По сути, это степень детализации, с которой источник распределяет работу и распараллеливает чтение данных.
Также есть сериализатор для сериализации состояний и разделения для обмена сообщениями и сохранения состояния. Метод createEnumerator() вызывается первым в источнике после методов сериализатора, а затем приложения Flink создают средства чтения (readers). Эти считыватели работают параллельно, поэтому следует организовать задачи по чтению данных так, чтобы избежать дублирования или обработки не по порядку. Как это реализуется, рассмотрим далее.
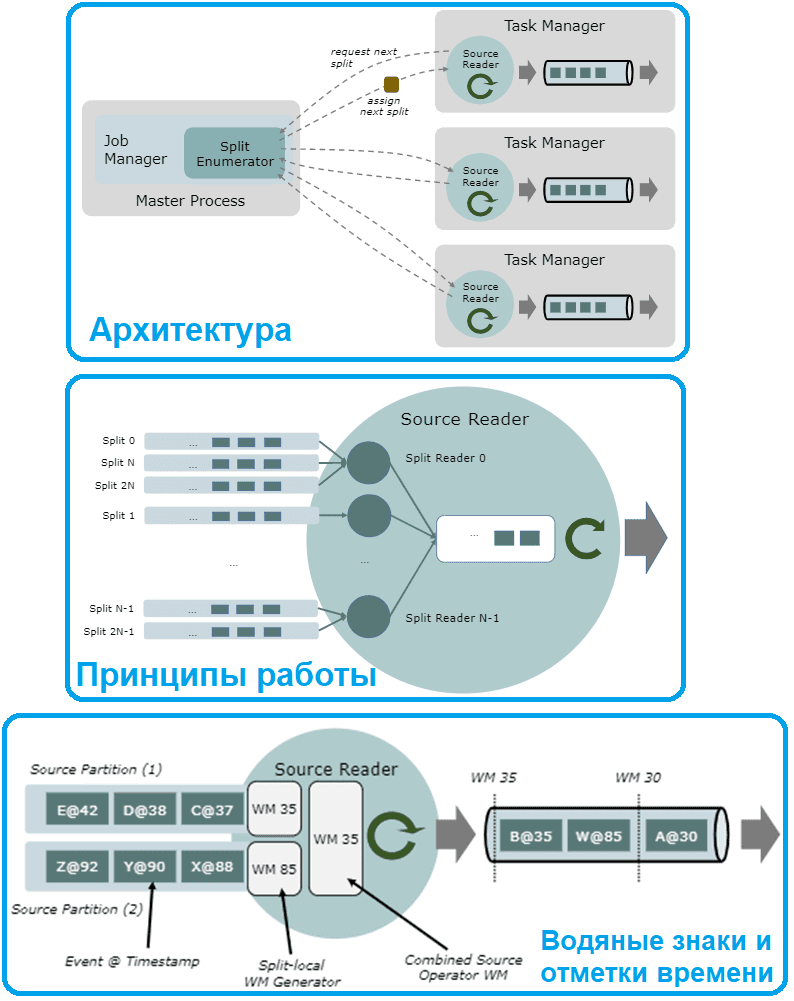
Как это работает
Предположим, если исходные данные для потоковой обработки публикуются в Kafka, Split – это раздел топика Kafka. SplitEnumerator подключается к брокерам для получения списка всех разделов топиков и может дополнительно повторить эту операцию, чтобы обнаружить новые добавленные разделы. SourceReader считывает назначенные разделы топиков с помощью KafkaConsumer и десериализует записи с помощью предоставленного десериализатора. Обычно в потоковой обработке данных разделы топиков не имеют конца, поэтому считыватель не останавливается, если не задать точку остановки явно. Если же раздел топика Kafka имеет заданное конечное смещение, SourceReader завершает работу, как только достигает его.
Временные метки событий назначаются в два этапа:
- SourceReader может прикрепить временную метку исходной записи к событию, вызвав метод collect(event,timestamp). Это актуально только для источников данных, основанных на записях и имеющих временные метки, таких как Apache Kafka, Pulsar, AWS Kinesis. Источники, которые не основаны на записях с метками времени, например, файлы, не имеют метки времени исходной записи. Этот шаг является частью реализации коннектора источника и не параметризуется приложением, использующим источник.
- TimestampAssigner, настроенный приложением, назначает окончательную метку времени, на основании временной метки исходной записи и события.
Этот двухэтапный подход позволяет пользователям ссылаться как на временные метки из исходных систем, так и на временные метки в данных события в качестве временной метки события. При использовании источника данных без временных меток исходной записи, таких как файлы и выборе временной метки исходной записи в качестве конечной временной метки события, их временная метка по умолчанию будет равна LONG_MIN (=-9 223 372 036 854 775 808).
Генераторы водяных знаков, о которых мы говори здесь, активны только во время выполнения потоковой передачи. API источника данных поддерживает запуск генераторов водяных знаков отдельно для каждого разделения, позволяя Flink наблюдать за ходом времени события для каждого разделения отдельно. Это важно для правильной обработки неравномерного распределения времени события и предотвращения того, чтобы незанятые разделы сдерживали ход времени события всего приложения. При реализации коннектора к источнику данных с помощью API Split Reader это обрабатывается автоматически. Все реализации, основанные на API Split Reader, имеют стандартные водяные знаки с поддержкой разделения.
Чтобы реализация API SourceReader более низкого уровня использовала генерацию водяных знаков с поддержкой разделения, реализация должна выводить события из разных разделений на разные выходные данные: Split-local SourceOutputs. Разделенные локальные выходные данные можно создавать и освобождать в основном выходе считывателя (ReaderOutput) с помощью методов createOutputForSplit(splitId) и releaseOutputForSplit(splitId).
Читайте в нашей новой статье, как создать и протестировать свой источник данных Apache Flink.
Освойте тонкости использования Apache Flink и Spark для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

