
В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое DataStax Enterprise Graph. Читайте далее, как немецкая ИТ-компания Traversals с помощью этой распределенной графовой СУБД построила масштабное аналитическое решение для кибербезопасности, обнаружения мошенничества, анализа конкурентов и оповещения клиентов в реальном времени. Также разберем, при чем здесь Cassandra и Spark SQL.
Постановка задачи: кейс компании Traversals
Немецкая компания Traversals работает в области аналитики больших данных и решений искусственного интеллекта. Перед Traversals стояла задача создать сервисы анализа данных для ряда приложений, включая кибербезопасность, обнаружение мошенничества, анализ конкурентов и оповещение пользователей в реальном времени. Для этого команда Data Scientist’ов и аналитиков Big Data решили использовать графовую парадигму обработки информации с возможностью масштабирования реализованных проектов. Идея состояла в построении единого графа знаний из нескольких источников, включая посты соцсетей, результаты поисковой выдачи из Google и Яндекс, а также открытые данные различных государственных сервисов. Объединяя данные из множества источников, компания Traversals планировала находить взаимосвязи в них, чтобы прогнозировать важные события в режиме реального времени.
Для этого команде разработчиков требовалась распределенная система графовой аналитики, способная в большом масштабе обрабатывать огромные объемы распределенных вычислений и эффективно обеспечивать сохранение результатов с течением времени. В качестве инструментального средства решения этой задачи сотрудники Traversals выбрали DataStax Enterprise Graph (DSE Graph), о чем мы поговорим далее. А о том, как международный ритейлер H&M использовал машинное обучение и графовую аналитике больших данных для анализа совместимости модных предметов одежды и обуви из своего торгового ассортимента, читайте в нашей новой статье.
Что такое DataStax Enterprise Graph
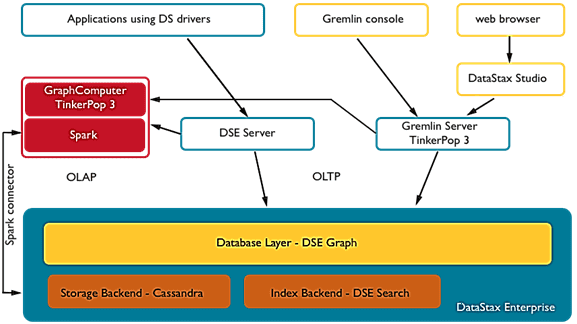
DataStax Enterprise Graph – это распределенная графовая база данных, оптимизированная для быстрого хранения и обхода данных, а также анализа сложных, разрозненных и связанных датасетов большого объема в реальном времени. Она может масштабироваться, выполняя транзакционные и аналитические рабочие нагрузки с поддержкой основных функций enterprise-систем, включая обеспечение безопасности, администрирование, мониторинг и инструменты разработки.
DSE Graph основан на популярных графовых СУБД TitanDB и Apache Cassandra, которые использует структуру графов для хранения данных и отношений. Именно такие графовые СУБД чаще всего применяются для бизнес-сценариев выявления взаимосвязей: предотвращение мошенничества, реализация платформ Интернета вещей и рекомендательных систем. Некоторые из этих кейсов мы разбирали в прошлых статьях: здесь, здесь и здесь.
Горизонтально масштабируемая архитектура DSE Graph способна обрабатывать петабайты информации и тысячи одновременных пользователей и операций в секунду: данные автоматически распределяются по всем узлам кластера. DSE Graph является компонентом комплексной аналитической системы DataStax Enterprise и обеспечивает следующие преимущества:
- масштабируемость для больших графов и большого количества пользователей, событий и операций – графы в DSE Graph могут содержать миллиарды вершин и ребер;
- одновременная поддержка большого объема транзакций (OLTP) и аналитической обработки графов (OLAP) – транзакционная емкость DSE Graph масштабируется в зависимости от размера кластера и отвечает на сложные запросы обхода огромных графов за миллисекунды;
- потоковая и пакетная аналитика данных в кластерах DSE реализуется с помощью унифицированного языка реляционных запросов Apache Spark SQL;
- интеграция с поисковым движком DSE Search обеспечивает эффективное индексирование, поддерживает поиск по географическим и числовым данным, а также полнотекстовый поиск вершин и ребер в больших графах;
- встроенная поддержка языка Apache TinkerPop для модели данных графа свойств и языка Gremlin. Gremlin — это основной интерфейс в DSE Graph, функциональный язык обхода графов и виртуальная машина от Apache TinkerPop, который естественным образом поддерживает императивные и декларативные запросы. Apache TinkerPop — это open-source проект, который предоставляет структуру абстракции для взаимодействия с DSE Graph и другими графовыми СУБД.
- Вершинно-ориентированные индексы сокращают время выполнения запросов, оптимизируя глубокий обход графа за счет быстрого сокращения пространства поиска;
- Оптимизированная утилизация дискового пространства позволяет эффективно использовать хранилище и обеспечивает быструю скорость доступа к данным.
В качестве интерактивного инструмента разработки DSE Graph использует аналитическую среду DataStax Studio. Эта система самодокументированных записных книг подобно Jupyter Notebook или Google Colab также позволяет писать запросы на CQL (Cassandra Query Language) к NoSQL-СУБД Cassandra и Spark SQL, поддерживая визуализацию результатов. Самодокументирующиеся записные книжки сочетают в себе исполняемый код, документацию (текст с разметкой) и визуализацию результатов запроса. Эта многофункциональная интерактивная среда предоставляет разработчикам и аналитикам интуитивно понятный интерфейс для совместной работы и проверки теорий.
DataStax Studio поддерживает визуальную навигацию по объектам СУБД Cassandra, включая создание сложных CQL-запросов и их настройку, помогая визуализировать пространство ключей в виде дерева. Для DSE Graph среда DataStax Studio обеспечивает исследование и просмотр больших наборов данных, наглядно представляя Gremlin-код в виде визуальных схем. Для разработчиков Spark-приложений и дата-аналитиков DataStax Studio позволяет писать, тестировать и выполнять запросы Spark SQL к кластерам DSE. Интеллектуальный редактор кода обеспечивает выделение синтаксиса, проверку, интеллектуальное завершение кода, параметры конфигурации и профилирование запросов.
DSE Graph и Apache Spark
Рассмотрим, как DSE Graph совмещает подходы OLTP и OLAP обработки. OLTP-запросы требуют доступ к ограниченному подмножеству всего графа. В OLTP-запросах используются фильтры, чтобы ограничить количество вершин, по которым нужно пройти. DSE Graph совмещает вершины с их ребрами и соседними вершинами. Когда подграф указывается в обходе с использованием индексов, количество запросов к диску сокращается, чтобы найти и записать запрошенный подграф в память. Попав в память, обход выполняет переход по ссылкам от вершины к вершине по ребрам.
OLAP-запросы обращаются к большой части данных графа. В случае OLAP-запросов весь граф интерпретируется как последовательность звездообразных графов, каждый из которых состоит из одной вершины, а также ее свойств, инцидентных ребер и свойств ребер. Звездные графы обрабатываются линейно, переходя от одного к другому, пока они все не будут обработаны. Затем выполняется агрегирование обнаруженных данных.
Каждый граф, созданный в DSE Graph, имеет источник обхода OLAP, доступный для консоли Gremlin и DataStax Studio. Этот источник обхода использует SparkGraphComputer для анализа запросов и их выполнения в отношении базовых узлов DSE Analytics. Узлы должны быть запущены с включенными Graph и Spark для доступа к источнику обхода OLAP. Для этого следует подключиться к master-узлу кластера Spark через консоль или указав его в поле hosts yaml-файла Gremlin.
Свойства Spark можно установить из Gremlin с помощью метода графа graph.configuration.setProperty(). По умолчанию Spark-приложения будут использовать все доступные ресурсы на узле, поэтому рекомендуется ограничить их перед запуском OLAP-обхода, установив максимальное количество ядер и объем памяти. Это особенно важно на серверах с очень большим количеством ядер ЦП и памяти. OLAP-обходы графа создают множество промежуточных объектов во время выполнения, которые собираются сборщиком мусора JVM. Поэтому рекомендуется настроить больший пул исполнителей, каждый с меньшими ресурсами памяти и ЦП, по сравнению с другими заданиями Spark, которые обычно лучше работают с меньшим количеством исполнителей с большим объемом памяти и ресурсов ЦП. В частности, чтобы уменьшить паузы при сборке мусора и повысить производительность обхода OLAP, доступная Spark память должна быть равномерно распределена между ядрами ЦП. А общее количество ядер ЦП на исполнителе не должно превышать 8, причем в каждый момент времени работает одно из них.
Настроить эти свойства поможет конфигурация spark.cores.max, которая устанавливает максимальное количество ядер, используемых Spark. Установка значения этого свойства меньше, чем общее количество ядер, ограничивает количество узлов, на которых будут выполняться запросы. Свойство spark.executor.memory задает объем памяти для каждого исполнителя Spark, а spark.executor.cores устанавливает количество ядер. Прежде чем настраивать свойства Spark из Gremlin, следует отключить текущий контекст Spark из веб-интерфейса этого фреймворка. Это завершит все выполняющиеся в данный момент OLAP-запросы Gremlin.
Некоторые OLAP-запросы и большинство запросов DseGraphFrame используют для обходов соединения Spark SQL. Напомним, по умолчанию Spark имеет 200 разделов для выполнения соединений слиянием. На практике это может создавать огромные разделы для очень больших графов, замедляя выполнение запросов. Поэтому, чтобы уменьшить размер отдельных разделов и повысить производительность, можно увеличить количество разделов в случайном порядке, повысив значение свойства spark.sql.shuffle.partitions. Например, в 2-4 раза больше ядер кластера Apache Spark.
Освойте практику использования Apache Spark и других инструментов Big Data для разработки распределенных приложений и графовой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники
- https://www.datastax.com/enterprise-success/traversals
- https://docs.datastax.com/en/dse/6.0/dse-dev/datastax_enterprise/graph/dseGraphAbout.html
- https://docs.datastax.com/en/studio/6.0/studio/aboutStudio.html
- https://docs.datastax.com/en/dse/6.0/dse-dev/datastax_enterprise/graph/graphAnalytics/graphAnalyticsSparkGraphComputer.html

