Сегодня рассмотрим, зачем в системах асинхронного обмена данными нужны очереди недоставленных сообщений, как их организовать и обработать. Разбираемся с Dead Letter Queue на примере Apache Kafka и RabbitMQ.
Обработка недоставленных сообщений в Apache Kafka
Хотя Apache Kafka и RabbitMQ не являются взаимозаменяемыми альтернативами, именно эти системы чаще всего используются для организации распределенных очередей в рамках асинхронного обмена данными между несколькими приложениями. Распределенный характер очереди сообщений предполагает разделение сообщений по нескольким серверам, каждый из которых может обрабатывать часть очереди сообщений и может связываться с другими серверами, чтобы гарантировать обработку всех данных. Про ключевые отличия Apache Kafka и RabbitMQ мы писали здесь. А в этой статье мы рассматриваем ключевые проблемы распределенных очередей сообщений и способы их решений в Apache Kafka и RabbitMQ.
Чтобы избежать потери данных без остановки всего конвейера, для сообщений которые не могут быть обработаны приложением-потребителем, можно использовать очередь недоставленных сообщений (Dead Letter Queue, DLQ). В DLQ скапливаются сообщения, которые не могут быть обработаны потребителем. Поскольку Apache Kafka, в отличие от RabbitMQ, не доставляет сообщения приложениям-потребителям, это обычно происходит из-за некорректного формата или схемы данных.
Отправка таких сообщений в DLQ-очередь Kafka реализуется в приложении-потребителе с помощью блока try-cath для обработки ожидаемых или непредвиденных исключений через вызов метода send() API продюсера. Например, на Python это может быть реализовано так:
from kafka import KafkaProducer, KafkaConsumer
import json
bootstrap_servers = ['localhost:9092']
primary_topic = 'primary-topic-name'
dlq_topic = 'dlq-topic-name'
dlq_producer = KafkaProducer(
bootstrap_servers=bootstrap_servers,
value_serializer=lambda x: x.encode('utf-8'),
acks='all'
)
consumer = KafkaConsumer(
primary_topic,
bootstrap_servers=bootstrap_servers,
auto_offset_reset='latest',
enable_auto_commit=True,
value_deserializer=lambda x: x.decode('utf-8')
)
for msg in consumer:
print(f'\nReceived:\nPartition: {msg.partition} \tOffset: {msg.offset}\tValue: {msg.value}')
try:
data = json.loads(msg.value)
print('Data Received:', data)
except:
print(f'Value {msg.value} not in JSON format')
dlq_producer.send(dlq_topic, value=msg.value)
print('Message sent to DLQ Topic')
Такой подход позволяет продолжить поток сообщений со следующими входящими сообщениями, не останавливая рабочий процесс из-за ошибки недопустимого сообщения. Однако, дата-инженер должен самостоятельно предусмотреть появление таких сообщений в конвейере обработки данных и программно реализовать работу с ними.
Впрочем, не всегда нужно реализовывать свою DLQ-очередь. Например, интеграционная среда Kafka Connect от Confluent предоставляет возможность управления недоставленными сообщениями. Настроить DLQ в Kafka Connect очень просто: достаточно установить значения для параметров конфигурации errors.tolerance и errors.deadletterqueue.topic.name.
При работе с приложениями Kafka Streams, разработанными с помощью библиотеки, которая позволяет работать с данными в топиках Kafka, используя мощную оболочку для API продюсера и потребителя Java, а также множество встроенных дополнительных функций. Одной из встроенных функций Kafka Streams является обработчик исключений десериализации, чтобы управлять исключениями записей, которые не могут быть десериализованы. Хотя в чистом виде эта функция Kafka Streams не называется Dead Letter Queue, фактически она решает организацию очереди недоставленных сообщений.
Во фреймворке Spring, который отлично поддерживает Apache Kafka и предоставляет множество шаблонов также есть различные варианты обработки ошибок и повторных попыток, включая очереди недоставленных сообщений. В частности, Spring Cloud Stream позволяет реализовать строить логику DLQ с помощью простых аннотаций.
Наконец, можно воспользоваться open-source проектом Parallel Consumer для Apache Kafka. Он предоставляет параллельную клиентскую оболочку Apache Kafka с очередями на стороне клиента, более простой API-интерфейс потребителя/продюсера с параллелизмом ключей и расширяемую неблокирующую обработку ввода-вывода. Эта библиотека позволяет обрабатывать сообщения параллельно через одного потребителя Kafka, позволяя увеличить параллелизм потребителей Kafka без увеличения количества разделов в топике. Во многих случаях это улучшает пропускную способность и уменьшает задержку обработки данных за счет снижения нагрузки на брокеров Kafka. Также этот проект открывает новые варианты использования, такие как экстремальный параллелизм, обогащение внешних данных и организация очередей.
Ключевой особенностью Parallel Consumer является обработка/повторение вызовов веб-сервисов и баз данных в одном клиентском приложении Kafka. Такое распараллеливание позволяет избежать единовременной отправки одного веб-запроса. Наконец, клиент Parallel Consumer имеет мощную логику повторных попыток, включая настраиваемые задержки и динамическую обработку ошибок, которые могут быть отправлены в очередь недоставленных сообщений.
Однако, ошибочные сообщения важно не только собрать в единую очередь, но и организовать их дальнейшую обработку. Как это сделать в Apache Kafka, мы разбираем здесь и здесь, а пока рассмотрим очереди недоставленных сообщений в RabbitMQ.
Dead Letter Queue в RabbitMQ
В RabbitMQ, который в отличие от Kafka, реализует pull-модель, сам доставляет сообщения приложениям-потребителям, сообщения повторно публикуются в обменнике, если истек срок жизни сообщения или очередь превысила максимальный лимит длины. Также это происходит, если приложение-потребитель со значением false для параметра requeue для настроек basic.reject или basic.nack, не подтвердило получение сообщения. Истечение срока действия очереди не приведет к удалению содержащихся в ней сообщений.
В RabbitMQ сообщение может попасть в DLX-очередь по следующим причинам:
- сообщение было отклонено с параметром requeue, установленным в значение false;
- истек срок жизни сообщения (TTL);
- превышена максимально допустимая длина целевой очереди, куда сообщение направлялось первоначально;
- сообщение было возвращено больше раз, чем предусматривает ограничение, установленное аргументом политики delivery-limit очередей кворума.
Каждая из этих причин кодируется соответствующим образом, что прописывается в аргументе reason пары {queue, reason}, которая означает событие недоставления сообщения в очередь queue.
Поскольку RabbitMQ реализует подход «умный брокер, глупый потребитель», эта платформа берет на себя работу с недоставленными сообщениями, используя встроенный механизм обменников (exchanger). Обменник недоставленных сообщений (Dead letter exchange, DLX) представляет собой обыкновенный обменник, который может быть любым из 4-х стандартных типов: Fanout (для распараллеливания сообщений в несколько очередей), Direct (для отправки в конкретную очередь по ключу маршрутизации), Headers (для сложной маршрутизации по заголовкам сообщения) или Topic (для маршрутизации по маскированному шаблону ключа).
Для любой заданной очереди DLX-обменник может быть определен на клиенте с использованием аргументов очереди или на сервере с использованием политик. Если используются оба варианта, аргументы клиента переопределяют политику сервера. Однако, рекомендуется применять политики, поскольку это позволяет переконфигурировать DLX без повторного развертывания приложений. Для этого следует добавить ключ dead-letter-exchange в определение политики. Можно применить общую DLX-политику ко всем очередям или уточнить ее, явно указав ключ маршрутизации с помощью параметра dead-letter-routing-key. Политики также можно определить с помощью подключаемого модуля управления.
Чтобы установить DLX-обменник для очереди, следует при ее создании указать необязательный аргумент x-dead-letter-exchange. Например, в GUI облачной платформе cloudamqp.com, которая позволяет создать собственный бессерверный экземпляр RabbitMQ, о чем я писала здесь и здесь, это будет выглядеть следующим образом.
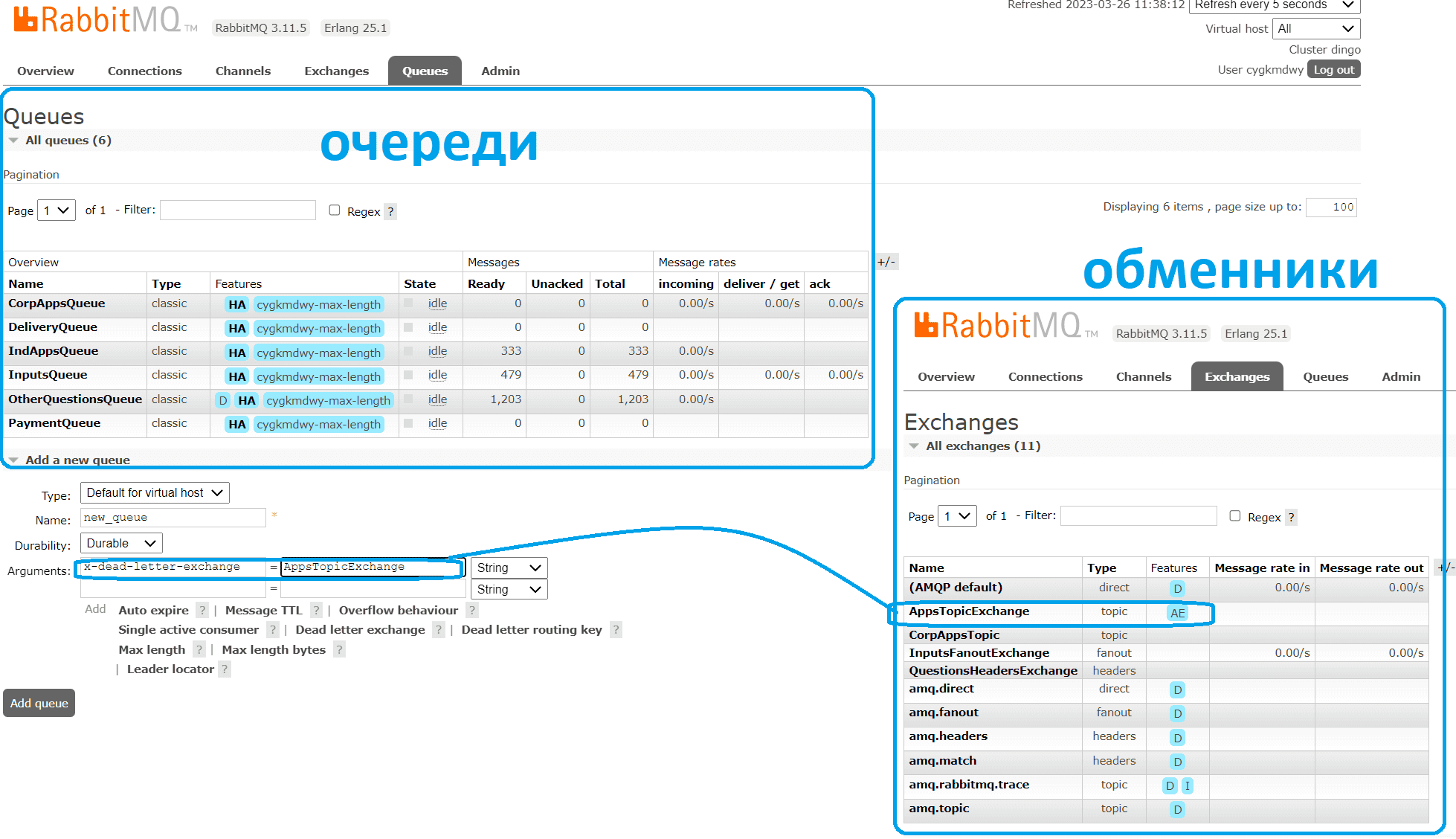
В этом примере уже существующий обменник AppsTopicExchange объявляется в качестве сборщика недоставленных сообщений для вновь создаваемой очереди new_queue. Важно, что DLX-обменник не создается при объявлении новой очереди, а уже должен существовать к тому времени, когда возникнут недоставленные сообщения, иначе они будут просто удалены. Можно детализировать маршрутизацию сообщений, указав ключ маршрутизации или заголовки сообщения для обменника типа Topic. Если для очереди не был установлен конкретный ключ маршрутизации, сообщения в ней помечаются недоставленными со всеми исходными ключами маршрутизации.
По умолчанию недоставленные сообщения повторно публикуются без внутреннего подтверждения продюсера. Поэтому в кластеризованной среде RabbitMQ не гарантируется безопасность использования DLX-обменников. Сообщения удаляются из исходной очереди сразу после публикации в целевой очереди DLX-обменника. Это гарантирует, что не будет чрезмерного накопления сообщений, что может привести к истощению ресурсов брокера. Но сообщения могут быть потеряны, если целевая очередь недоступна для приема сообщений.
Таким образом, благодаря механизму обменников и множеством настраиваемых параметров очереди, работа с недоставленными сообщениями в RabbitMQ изначально более гибкая, чем в Apache Kafka. Однако, при необходимости обработку недоставленных сообщений в Kafka дата-инженер может модифицировать с помощью пользовательского кода и лучших практик работы с этой платформой потоковой передачи событий, о которых мы рассказываем в нашей новой статье.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Администрирование кластера Kafka
- Apache Kafka для инженеров данных
- Администрирование Arenadata Streaming Kafka
Источники

