Чтобы добавить в курсы по Apache AirFlow еще больше полезных примеров, сегодня рассмотрим, как избежать дублирования кода при загрузке данных. Этот пример пригодится дата-инженерам в работе с ELT-процессами наполнения информацией корпоративных хранилищ и озер данных. Читайте про фреймворк динамической загрузки данных на базе конфигурационных YAML-файлов, DAG-фабрик и загрузчиков.
Проблема дублирования DAG’ов в ELT-процессах работы с озером данных
Дата-инженеры используют Airflow в качестве оркестратора конвейера данных, чтобы упростить организацию и мониторинг процессов их обработки. Одним из самых частых кейсов при этом являются процессы взаимодействия с корпоративными хранилищами и озерами данных: извлечение информации из разных источников и их загрузка в Data Lake на базе Apache Hadoop HDFS или AWS S3.
На практике обычно дата-инженер создает отдельный цепочку задач (DAG, Directed Acyclic Graph) для каждого источника данных, который должен быть интегрирован в Data Lake. Этот подход отлично работает вначале, но по мере роста объема информации и усложнения таких конвейеров объем дублированного кода многократно возрастает. По сути, исходный код, создающий DAG для извлечения данных, является одинаковым для каждого источника, отличаясь особенностями подключения к нему и запросом на инкрементную загрузку данных в Data Lake. Помимо нарушения одного из главных принципов современной разработки ПО – DRY (Do Not Repeat Yourself), дублирование кода увеличивает объем работы при внесении изменений, которые следует отразить в каждом DAG. Это отнимает много времени и может стать причиной ошибок. Избежать этой проблемы поможет обобщенный способ создания DAG для процессов загрузки данных [1]. О некоторых из них мы уже рассказывали в статье о динамической генерации DAG из одного или нескольких Python-файлов. Энтузиасты профессионального сообщества AirFlow сгруппировали эти идеи в единый фреймворк, чтобы упростить управление процессами загрузки данных. Как это работает и что под капотом этого фреймворка, мы рассмотрим далее.
Упрощение процессов загрузки данных: Docker для Apache Airflow
Обычно для унификации отдельных задач в AirFlow дата-инженер пишет файл конфигурации, на основе которого платформа динамически генерирует DAG, позволяя постепенно извлекать данные из целевого источника и загружать их в Data Lake. Предлагаемый фреймворк состоит из трех логических уровней [1]:
- файлы конфигурации в формате YAML, где содержатся сведения об источниках данных, включая параметры DAG, учетные данные, спецификации таблиц, типы данных и пр. Поэтому интегрировать новый исходный код также легко, как написать простой файл конфигурации.
- Фабрики DAG, основанные на Python-библиотеке DAG-factory – open-source проекте для динамической генерации DAG-файлов Airflow из YAML-файлов. Эту библиотеку, исходный код которой доступен на Github, следует установить в среде Airflow через менеджер пакетов pip: pip install dag-factory. Версия должна быть выше Python 3.6.0, а версия Apache Airflow – выше 1.10 [2]. С его помощью можно динамически создать YAML-файлы конфигурации для генерации DAG, вызвав метод dag-factory.generate_dags() в Python-скрипте. Это позволяет инкапсулировать логику для динамического создания DAG через интерфейс и фабрики. Интерфейс DAG отвечает за чтение файлов конфигурации и передачу параметров конфигурации в соответствующую фабрику, чтобы она могла создать рабочий процесс DAG, позволяющий извлекать данные из целевого источника. Фабрики DAG можно разделить по типам движков баз данных, например, при извлечении информации из MySQL и MongoDB.
- Загрузчик – Docker-образ, реализующий подход функциональной инженерии данных в процессах их загрузки. С заданным набором параметров загрузчик может извлекать данные из целевого источника и загружать их в Data Lake. Загрузчики детерминированы и идемпотентны, поэтому они дают один и тот же результат при каждом запуске с одним и тем же набором параметров. Чтобы упростить управление загрузчиками их также можно разделить по типам источников данных и зарегистрировать в реестре Docker-образов (Docker registry) – масштабируемом серверном stateless-приложении, которое хранит и позволяет распространять образы Docker. Загрузчик представляет собой простой Python-скрипт с набором параметров для определения источника и приемника: хост, учетные данные, имя базы данных, таблицы, столбца и пр. Исходный код загрузчика для источника данных MySQL и приемника AWS S3 можно посмотреть на Github [3].
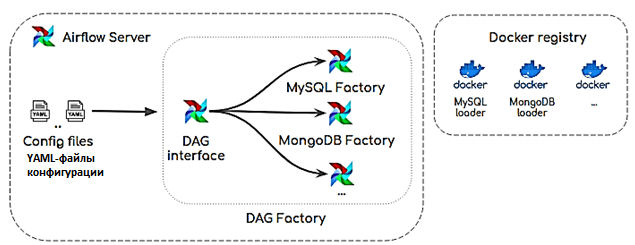
Таким образом, работа описанного фреймворка сводится к следующему [1]:
- Интерфейс DAG читает из файла конфигурации параметры для динамической генерации DAG (имя, аргументы по умолчанию, расписание, соединение с базой данных, таблицы, столбцы с их типами данных);
- в соответствии с типом ядра базы данных, создается рабочий процесс DAG путем вызова соответствующего метода фабрики, передавая ей необходимые параметры, считанные из файла конфигурации;
- фабрика DAG динамически создает рабочий процесс, позволяющий извлекать и загружать данные из целевого источника. При этом он будет иметь столько задач, сколько таблиц указано в файле конфигурации. Задачи основаны на запуске соответствующего Docker-образа загрузчика с помощью операторов Airflow Docker. Для этого параметры, указанные в файле конфигурации, должны быть переданы как переменные среды в Docker-образ.
- Загрузчик извлекает данные из определенного механизма СУБД базы данных и загружать их в озеро данных, например, на базе Hadoop HDFS или AWS S3.
О том, как AirFlow используется в low-code сервисе интеграции веб-приложений Zapier, читайте в нашей новой статье. А другие интересные примеры практического применения Apache AirFlow для разработки сложных конвейеров аналитики больших данных с Hadoop и Spark вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://towardsdatascience.com/generalizing-data-load-processes-with-airflow-a4931788a61f
- https://github.com/ajbosco/dag-factory
- https://github.com/ajhenaor/pyspark-mysql-to-s3-loader