Продолжая разговор про Apache NiFi и другие ETL-инструменты больших данных, сегодня мы подробнее расскажем про пакетные средства загрузки и маршрутизации информации из различных источников: Sqoop, Chuckwa и Falcon. Читайте в нашей статье, чем они похожи и чем отличаются, а также как применяются в Big Data системах и интернете вещей (Internet of Things, IoT), в т.ч. индустриальном (Industrial IoT, IIoT).
Краткий обзор 3-х популярных ETL-систем пакетной передачи Big Data
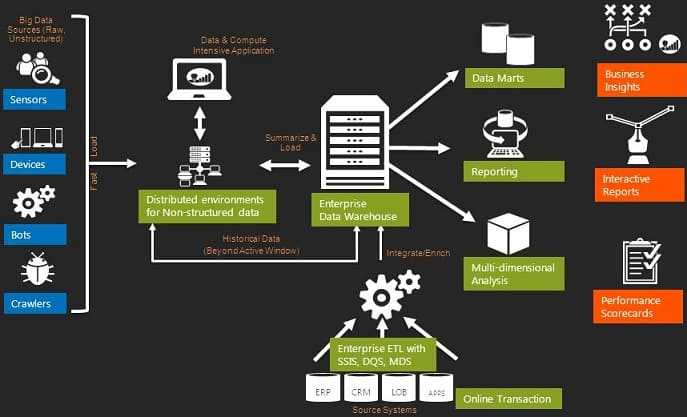
Среди фреймворков пакетной загрузки больших данных из разных источников наиболее популярными считаются следующие проекты фонда Apache Software Foundation (ASF):
- Chukwa – платформа сбора данных с открытым исходным кодом для мониторинга распределенных Big Data систем, построенная на базе HDFS и MapReduce, включая масштабируемость и надежность Apache Hadoop. Chukwa содержит гибкий и мощный инструментарий для отображения, мониторинга и анализа результатов, чтобы наилучшим образом использовать собранные данные [1].
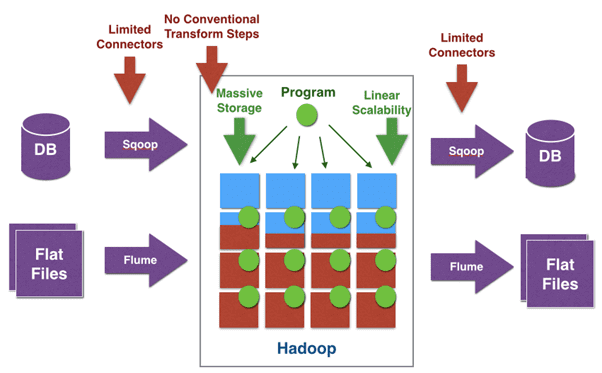
- Sqoop – инструмент для эффективной передачи информации между Apache Hadoop и структурированными хранилищами данных – реляционными СУБД (Oracle, MS SQL Server, MySQL, PostgreSQL, Netezza, Teradata и другие, которые поддерживают подключение JDBC). Sqoop использует MapReduce для импорта и экспорта данных, что обеспечивает параллельную работу и отказоустойчивость. Интерфейс Sqoop реализован в виде командной строки [2].
- Falcon— фреймворк по обработке и управлению данными в Hadoop, в т.ч. для координации данных и управления их жизненным циклом. При этом обеспечивается быстрая передача информации и связанных процессов/задач в кластер Apache Также реализуется высокое качество обработки и предсказуемость результатов при общем упрощении процесса управления данными. Пользователю достаточно всего лишь определить конечные точки инфраструктуры и объявить (декларировать) датасеты и правила обработки. Декларативные конфигурации дают возможность явно задавать зависимости между данными, процессами и задачами, позволяя оперировать различными функциями управления [3].
С точки зрения надежности передачи данных, у вышеперечисленных систем обеспечивается по-разному: в Apache Sqoop и Falcon – за счет репликации данных в HDFS, в Chukwa – с помощью механизма контрольных точек (checkpoints) [4].
Где и как используются Apache Chukwa, Sqoop и Falcon: реальные примеры
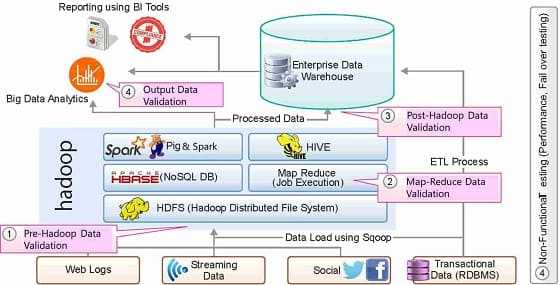
На практике Apache Chukwa широко используется для сбора логов из распределенных веб-систем, а также SCADA, что позволяет применять ее в IIoT-проектах с возможностью линейного масштабирования скорости передачи данных до 200 МБ/сек [5]. Однако, в случае непрерывной передачи данных с критичным требованием относительно низкой временной задержки (low latency), необходимо воспользоваться потоковыми ETL-инструментами, о который мы расскажем в новой статье.
Если требуется передавать не только данные журналов (логи), но и другую информацию между реляционными базами данных и кластером Apache Hadoop, следует обратить внимание на Sqoop. В частности, именно этот ETL-инструмент используется международной компанией Apollo Group для извлечения информации из внешних баз данных и обратного помещения обработанных в кластере Hadoop пакетов. Другая крупная компания, Coupons.com использует Sqoop для обмена данными между своим корпоративным хранилищем IBM Netezza and экосистемой Apache Hadoop [6].
Для упрощения процессами управления данных в Apache Hadoop и построения крупномасштабных конвейеров маршрутизации в этой экосистеме используется Falcon. Например, InMobi Technologies, индийский глобальный поставщик корпоративных платформ для маркетологов, использует Apache Falcon в качестве платформы для управления своими ETL-конвейерами отчетности, аналитики, машинного обучения (Machine Learning), соблюдения политики хранения данных, архивации данных и их перемещения по глобальной сети. Также Falcon может применяться для запуска одинаковых конвейеров на нескольких сайтах с локальными данными с последующим объединением результатов [7].
Отметим еще раз, что, пакетные ETL-инструменты работают с некоторой задержкой, обусловленной временем на сбор и упаковку нужного объема данных в пакет для последующей загрузки в место назначения. Если необходима «мгновенная» передача информации («на лету», т.е. в режиме реального времени), следует обратить внимание на потоковые маршрутизаторы: Apache Flume, NiFi, Fluentd и StreamSets Data Collector. Как они работают и где применяются на практике, мы рассмотрим в следующий раз.
Станьте профессионалом по установке, администрированию и эксплуатации ETL-средств для больших данных на нашем практическом курсе Кластер Apache NiFi в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве.
Источники
- http://chukwa.apache.org/
- https://ru.bmstu.wiki/Apache_Sqoop
- https://www.nixp.ru/news/13112.html
- https://moluch.ru/archive/202/49512/
- https://www.usenix.org/legacy/event/lisa10/tech/full_papers/Rabkin.pdf
- https://www.dezyre.com/article/sqoop-vs-flume-battle-of-the-hadoop-etl-tools-/176
- http://www.hadoopsphere.com/2015/03/data-pipelines-with-apache-falcon.html

