Чтобы на наглядном примере показать, чем Apache NiFi полезен для дата-инженера, сегодня рассмотрим практический кейс построения простого ETL-конвейера. Как собрать данные из разных API, записать их в СУБД и отправить уведомление о результатах с готовыми процессорами NiFi.
Постановка задачи: ETL-конвейер тревел-приложения
В качестве примера рассмотрим корпоративное приложение для путешественников, которое собирает данные об авиарейсах в реальном времени, сопоставляет данные о фактической погоде в городе прилета и формирует пакет предложений по местным гостиницам и трансферу до них.
Популярный инструмент современной дата-инженерии, Apache NiFi позволяет автоматизировать сбор и маршрутизацию потоков данных между множеством приемников и источников в соответствии с заданными требованиями по качеству данных посредством точной фильтрации. Рассмотрим, как брать данные из двух разных API, записывать их в быструю объектно-реляционную базу данных PostgreSQL и отправлять уведомления в каналы корпоративного мессенджера Slack.
API позволяет открывать данные и функции приложений для внешних разработчиков и сторонних сервисов благодаря документированному средству взаимодействия, т.е. самому интерфейсу прикладного программирования. Стороннему разработчику не нужно знать, внутреннюю реализацию сервиса, к которому идет обращение через API, как и устройство самого интерфейса, чтобы использовать его для взаимодействия с данными и функциями. В нашем кейсе первый API, например, Aviationstack.com позволяет получить доступ к данным о рейсах в реальном времени. Второй API, к примеру, visualcrossing.com дает возможность получить данные о погоде в любом городе. Сопоставление данных о городе, в котором находится аэропорт назначения из первого API, с данными о погоде от второго API, будет реализовано через обращение к этим API в рамках Apache NiFi. Также в этом ETL-конвейере помимо Apache NiFi, будет использоваться сервис синхронизации распределенных систем ZooKeeper, который упростит управление ими за счет улучшенного и надежного распространения изменений.
Чтобы облегчить процессы тестирования и развертывания приложения, можно использовать технологию контейнерной виртуализации, упаковав в единый образ Docker разработанный исходный код со всем сопутствующим программным окружением. Далее этот контейнер можно быстро развернуть в любой среде, избежав сложностей с ее настройкой и администрированием.
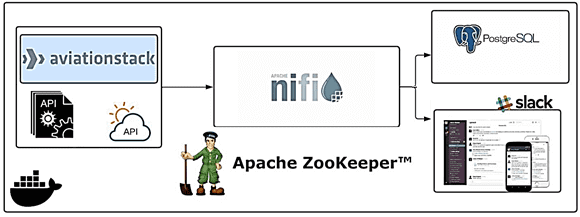
С точки зрения дата-инженера в данном кейсе интересен сам ETL-процесс, т.е. сбор, преобразование и загрузку данных. В Apache NiFi получение данных из источников, их преобразование и дальнейшая маршрутизация в места назначения реализуется с помощью процессоров, что мы и рассмотрим далее.
Реализация в Apache NiFi
Поскольку в рассматриваемом кейсе источниками данных являются внешние API, прежде всего необходимо обратиться к ним. Для этого в Apache NiFi есть процессор клиента HTTP под названием InvokeHTTP, который может взаимодействовать с настраиваемой конечной точкой этого протокола. Целевой URL-адрес и метод HTTP настраиваются. Атрибуты потокового файла (FlowFile) преобразуются в заголовки HTTP, а его содержимое включается в тело запроса при использовании HTTP-методов PUT, POST или PATCH. После настройки параметров и запуска, процессор InvokeHTTP вернет данные в формате JSON. Чтобы выделить из этого ответа данные по конкретным дням, получив доступ к каждой отдельной записи, для разделения можно использовать процессор SplitJSON. Он разбивает файл JSON на несколько отдельных файлов потоковых файлов для элемента массива, заданного выражением JsonPath. Каждый сгенерированный FlowFile состоит из элемента указанного массива и передается в отношение «разделение» (split), при этом исходный файл передается в «исходное» отношение (original). Если указанный JsonPath не найден или не оценивается как элемент массива, исходный файл перенаправляется на «сбой» (failure), и файлы не создаются.
Чтобы записывать в PostgreSQL не все, а только нужные данные, для фильтрации пригодится процессор JoltTransformJSON. Он применяет список спецификаций Jolt к полезной нагрузке JSON потокового файла. Новый FlowFile создается с преобразованным содержимым и направляется в отношение «успех». Если преобразование JSON завершается с ошибкой, исходный FlowFile направляется в отношение «сбой». Прежде чем добавлять данные в PostgreSQL в виде записи, следует преобразовать данные в формате JSON в DML-команды, т.е. сформировать SQL-запрос на вставку данных в таблицу СУБД через Insert. В настройках процессора PutDatabaseRecord, отвечающего за запись данных в PostgreSQL, следует указать подробности соединения с базой данных, имя схемы и таблицы.
Процессор PutDatabaseRecord использует указанный RecordReader для ввода записей из потокового файла. Эти записи транслируются в операторы SQL и выполняются как единый пакет. При возникновении ошибок потоковый файл перенаправляется на сбой или повторяет попытку. Тип оператора, выполняемого процессором, указывается через соответствующее свойство (INSERT, UPDATE или DELETE). Также возможно задать тип оператора через атрибут Use statement.type Attribute, который заставляет процессор получать тип оператора из атрибута потокового файла. Но если тип оператора UPDATE, то входящие записи не должны изменять значения первичных ключей или указанных пользователем ключей обновления. Если такие записи встречаются, оператор UPDATE, отправленный в базу данных, может ничего не сделать, если не найдены существующие записи с новыми значениями первичного ключа или может непреднамеренно повредить существующие данные путем изменения записей, для которых не найдены новые значения существующего первичного ключа.
За отправку уведомлений в корпоративный мессенджер Slack в Apache NiFi отвечает процессор PutSlack. В конфигурации этого процессора необходимо задать настройки подключения к нужному каналу и указать шаблоны формирования сообщений по нужным переменным. В нашем случае это город прилета.
В заключение отметим, что при отсутствии готовых процессоров, разработчик Data Flow может самостоятельно создать собственный, о чем мы подробно писали здесь. А еще один пример построения простого конвейера по переносу данных из облачного объектного хранилища AWS S3 в Hadoop HDFS с помощью готовых процессоров Apache NiFi, читайте в нашей новой статье.
Освойте все тонкости администрирования и эксплуатации Apache NiFi для эффективной аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://medium.com/i%CC%87stanbuldatascienceacademy/dataflow-with-apache-nifi-flight-weather-api-writing-various-source-8863d91c2b7e
- https://medium.com/@stefentaime/getting-started-with-etl-pipeline-data-engineering-using-api-apache-nifi-zookeeper-postgres-f96ae2faeb81
- https://github.com/Stefen-Taime/Nifi-ETL-Data-Pipeline

