Мы уже рассматривали, как загрузить в Greenplum большие объемы данных. В продолжение этой важной для обучения дата-инженеров темы, сегодня разберем еще несколько инструментов, решающих задачу организации ETL-процессов с этой MPP-СУБД.
ETL-инструменты PostgreSQL
Хотя Greenplum может хранить и обрабатывать огромные наборы данных на уровне петабайт, эта СУБД не генерирует их самостоятельно, а получает из внешних источников. Данные генерируются миллионами пользователей, IoT-устройствами, транзакционными, аналитическими и файловыми системами. Все эти источники данных передают их в Greenplum не напрямую, а через промежуточные системы хранения. Чтобы эффективно загружать в Greenplum новые данные с минимальной задержкой, дата-инженеры используют специальные инструменты организации ETL-процессов. В случае Greenplum их можно разделить на 2 категории: из сообщества PostgreSQL,которая лежит в основе GP, и собственные утилиты этой MPP-СУБД.
ETL-инструментам PostgreSQL относятся команды копирования. Прежде всего, это Pg_dump —инструмент командной строки, который может извлекать данные из таблицы в файл. Это официальное решение для резервного копирования PostgreSQL. Он может упаковывать данные в обычный или сжатый файл, а также в настраиваемый формат, и выводить только таблицу DDL. Самая простая команда резервного копирования выглядит следующим образом:
pg_dump mydb > db.sql
А восстановить файл дампа поможет обратная команда:
psql -f db.sql mydb
Также копировать данные можно с помощью оператора copy — SQL-команды PostgreSQL и Greenplum, которая обеспечивает обмен данными между таблицей и файлом. Она может выгрузить содержимое таблицы с необходимым разделителем, заголовком и прочими метаданными в файл и наоборот. Копирование также может быть выполнено на стороне клиента, который также может использовать файл на хосте psql, для таблицы на удаленном сервере. В Greenplum 5.0 улучшена функция копирования, позволяющая обрабатывать файл на каждом хосте сегмента, а не на главном хосте, если в команде copy есть соответствующее ключевое слово on segment. Недостатком этого решения является последовательность процесса копирования, поскольку строки проходят через мастер-узел, а все данные копируются одной командой. Этот способ загрузки из файла или стандартного ввода подходит для добавления относительно небольших наборов данных, например, таблиц измерений до 10 000 строк или однократной загрузки данных. Тем не менее, в некоторых случаях, связанных с восстановлением из резервной копии, PostreSQL-команда copy работает лучше специализированной утилиты gpfdist, о которой мы поговорим далее.
Но перед этим еще рассмотрим SDK как способ загрузки данных в Greenplum. Эта MPP-СУБД поддерживает 3 типа интерфейса SDK: libpq, ODBC и JDBC. Драйверы ODBC и JDBC широко используются многими инструментами BI и ETL, обеспечивая общий интерфейс для интеграции с Greenplum. Как и в случае copy, ограничением этого инструмента PostgreSQL является отсутствие возможности MPP: передача данных выполняется через мастер-узел, который становится узким местом, если сегментов много. Процесс загрузки данных выглядит так:
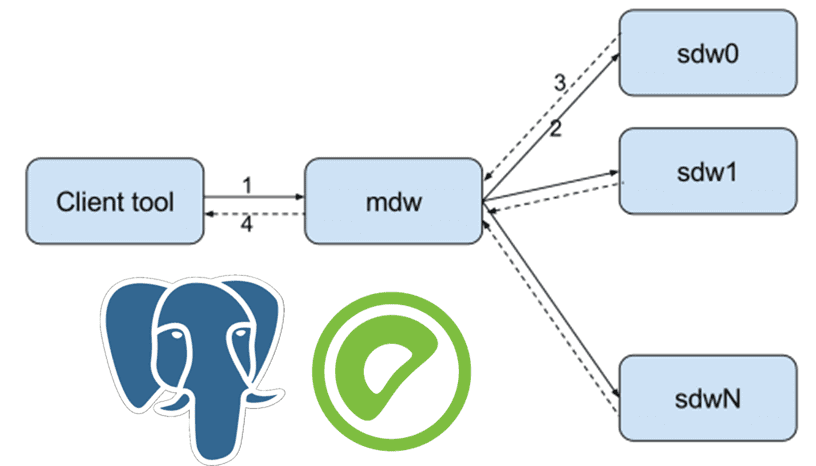
- Клиентский инструмент отправляет запрос выбора внешней таблицы мастеру (mdw);
- Мастер-узел отправляет команду каждому сегменту (sdwn);
- Сегмент посылает данные мастеру;
- Мастер возвращает результат запроса клиенту.
Утилиты Greenplum
Обойти недостатки PostgreSQL-инструментов, связанные с отсутствием массивно-параллельной обработки данных, помогают специальные утилиты Greenplum. Одной из них является gpfdist — программа файлового сервера, которая использует протокол HTTP, чтобы загружать данные параллельно в каждый сегмент напрямую без мастера, параллельно обслуживая внешние файлы данных для сегментов Greenplum. Экземпляр gpfdist может обрабатывать 200 МБ/с, а процессы gpfdist выполняются одновременно, каждый из которых обслуживает часть данных, подлежащих загрузке.
Greenplum использует внешнюю таблицу для связи с внешним источником данных. Утилита позволяет Greenplum считывать данные с сервера gpfdist, который работает как http-сервер, а сама MPP-СУБД – как http-клиент в каждом сегменте для параллельного запроса данных из главной внешней таблицы gpfdist. Рабочий процесс читаемой внешней таблицы gpfdist выглядит так:
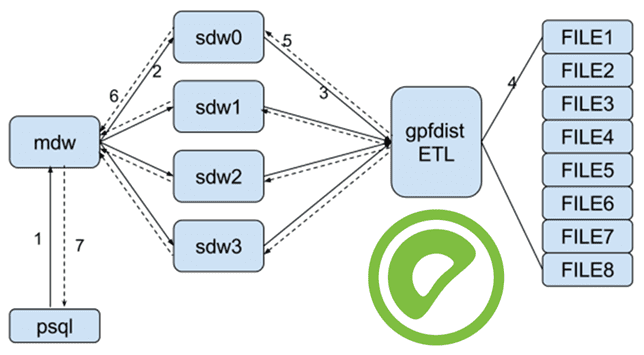
- Клиентский инструмент отправляет запрос выбора внешней таблицы мастеру (mdw);
- Мастер отправляет команду каждому сегменту (sdwn);
- Каждый сегмент отправляет запрос на ETL-сервер gpfdist с http-запросом;
- Gpfdist читает файл, анализирует его и разделяет каждую строку файла;
- Gpfdist отправляется в другой сегмент параллельно;
- Сегмент отправляет результат мастеру по завершении чтения;
- Мастер возвращает результат запроса клиенту.
Помимо HTTP-сервера для отправки статического файла, gpfdist также предоставляет множество дополнительных функций для улучшения операции загрузки данных.
- поддержка SSL для безопасной передачи конфиденциальных данных, в отличии от простой передачи обычного текста по сети. Gpfdist будет работать в режиме безопасности, если он начинается с аргумента —ssl. Тогда любое подключение к серверу gpfdist будет зашифровано. Greenplum может передавать данные с этим режимом безопасности, если имя протокола задано как gpfdists.
- поддержка формата сжатия, чтобы более эффективно использовать емкость диска. Gpfdist может читать внешние таблицы из сжатого файла gzip или bzip2 напрямую.
- преобразование (transform) — предварительная обработка, когда содержимое файла данных не совсем соответствует определению таблицы. Gpfdist предоставляет метод предварительной обработки файла данных перед их передачей в Greenplum. Метод считывает конфигурацию из YAML-файла, который определяет, как запускать скрипт.
- PIPE – общий метод межпроцессного взаимодействия в системе POSIX. PIPE может быть записан одним процессом и одновременно прочитан другим. Gpfdist может читать файл из PIPE, когда он передает содержимое в сегменты Greenplum. Используя PIPE, gpfdist может эффективно обмениваться данными с другим инструментом, потому что на самом деле данные не нужно сохранять на диск. Это наиболее часто используемая функция gpfdist для взаимодействия с другими инструментами, например, Informatica.
О лучших практиках применения gpfdist для загрузки больших объемов данных в Greenplum мы писали здесь.
В заключение отметим еще одну утилиту загрузки данных в Greenplum – gpload, которая действует как интерфейс для параллельной загрузки внешних таблиц. Ее производительность ниже, чем у gpfdist. Также она может вызвать увеличение каталога из-за создания и удаления внешних таблиц. Gpload выполняет загрузку, используя спецификацию, определенную в YAML-файле управления, за одну транзакцию выполняя следующие операции:
- вызов процессов gpfdist;
- определение временной внешней таблицы на основе исходных данных;
- осуществление операций INSERT, UPDATE или MERGE для загрузки исходных данных в целевую таблицу СУБД;
- удаление временной внешней таблицы;
- очистка процессов gpfdist.
Читайте в нашей новой статье, как писать UDF-функции на Python с помощью соответствующего расширения Greenplum. А освоить практику администрирования и эксплуатации этой MPP-СУБД для эффективного хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

