
Сегодня рассмотрим преимущества потоковой обработки данных с Apache Kafka и Flink над пакетными Big Data технологиями в виде Hadoop, Spark и Oozie. В качестве примера разберем реальный кейс аналитики больших данных по пользовательским сеансам в музыкальном онлайн-сервисе Spotify, а также возможность замены Apache Flink на Spark Structured Streaming.
От рекламы до контент-менеджмента: зачем Spotify анализ пользовательских сеансов
Бизнес аудио-сервиса Spotify основан на стриминговых технологиях Big Data, которые позволяют пользователям в режиме онлайн легально и бесплатно слушать более 50 миллионов музыкальных треков, аудиокниг и подкастов без загрузки данных на локальное устройство. Spotify доступен в США, Европе, Австралии и Новой Зеландии, в некоторых странах Азии и Африки, а с 2021 года пришел и Россию. Сервис занимает более 36 % мирового аудиостриминга, причем около 70% прослушиваний выполняется через плейлисты, а не по поисковым запросам или авторским страницам [1]. Поэтому данные о пользовательских сеансах (продолжительность, количество прослушанных песен, пропуски и прерывания) позволяют определить текущее настроение пользователя, чтобы сформировать для него персональные рекомендации. О том, как устроена рекомендательная система Spotify на базе Apache Kafka, Storm, Hadoop и Cassandra, мы рассказывали здесь. А сейчас выделим еще несколько ключевые задач, которые обеспечивает аналитика пользовательских сеансов [2]:
- визуализация важных KPI на наглядных дэшбордах, например, как долго пользователи слушают новую серию Discover Weekly – персонализированного плейлиста с предложениями песен в зависимости от прослушанных композиций и текущих рекомендаций – сколько песен подряд прослушано или пропущено.
- определение текущего поведения конкретной категории пользователей с помощью нескольких показателей и быстрая реакция. Например, если австралийские пользователи не слушают Discover Weekly в понедельник утром, так долго, как обычно, можно оперативно активировать оповещение и выявить проблему до того, как проснутся европейские или американские пользователи, чтобы снизить риск негативного инцидента.
- онлайн-формирование персональных рекомендаций по контенту и вставка подходящей рекламы на основе того, что пользователь слушает или чувствует прямо сейчас.
Разумеется, все перечисленные сценарии могут быть реализованы с помощью классической пакетной обработки с почасовыми или ежедневными заданиями. Но потоковая обработка данных в реальном времени с малой задержкой принесет больше выгоды – далее мы рассмотрим, почему.
Как устроена пакетная архитектура обработки событий и что с ней не так
Часто для анализа пользовательских сеансов в пакетном режиме используются такие Big Data технологии, как Apache Kafka, Hadoop, Spark и Oozie. В этом случае система аналитики больших данных работает следующим образом:
- сперва выполняется сбор данные о пользовательском поведении – события об активности пользователей непрерывно отправляются в Apache Kafka в режиме реального времени$
- для периодического копирования событий из Kafka в HDFS (система Hadoop), например, каждый час используется пакетный инструмент, такой как Camus или Oozie;
- Spark запускает пакетные задания для группировки отдельных пользовательских событий в пользовательские сеансы. В Spotify сессия одного пользователя может длиться много часов, к примеру, при прослушивании музыки в долгих поездках. Это усложняет процесс создания полных и правильных пользовательских сессий, т.к. события одного и того же пользовательского сеанса могут располагаться в разных часовых сегментах, которые неизвестны заранее.
- для смягчения этой проблемы задание Spark может запускаться ежедневно, например, в полночь, обрабатывая последние 24-часовые сегменты, чтобы создать набор данных с пользовательскими сеансами за определенный день. Такой подход гарантирует полноту и корректность созданных пользовательских сеансов.
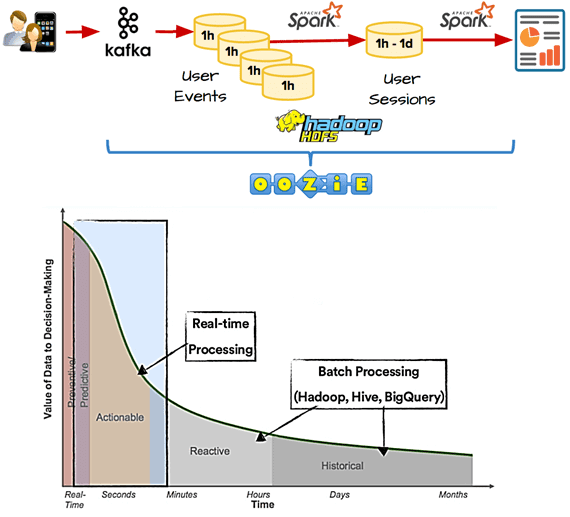
Однако, возникнут проблемы с сеансами, которые начинаются до полуночи и заканчиваются после этого момента. А, поскольку Spotify пользуется спросом в разных странах и часовых поясах, таких сеансов будет много, т.к. пользователи слушают музыку постоянно и везде. Альтернативой является ежечасное выполнение заданий Spark, которые будут каждый раз объединять промежуточные данные об активных сеансах за последний час. Но сохранение таких промежуточных данных о состояния сеанса «на лету» — достаточно нетривиальная задача. Кроме того, независимо от подхода, задание Spark должно группировать события по пользователям, сортировать их по меткам времени, удалять дубликаты и, что самое важное, назначать один и тот же идентификатор сеанса событиям, которые происходят близко друг к другу.
Анализ данных с Apache Spark
Код курса
SPARK
Ближайшая дата курса
13 мая, 2024
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
Почти real-time: микропакетная архитектура Spark Streaming
Самый простой способ уменьшить задержку и сократить цикл обратной связи — использовать Spark Streaming. Непрерывное выполнение задания потоковой передачи Spark позволяет исключить Camus, Oozie и разделение данных в Hadoop HDFS. Также можно быстрее получать результаты, настроив задание Spark Streaming для обработки всех новых событий небольшими пакетами каждые 10 минут или даже ежеминутно.
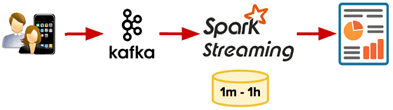
Однако, реализовать поддержку пользовательских сеансов в Spark не так-то просто, т.к. этот фреймворк внутренне разделяет непрерывный поток событий на отдельные микропакеты. Поскольку один пользовательский сеанс может охватывать несколько микропакетов, потребуется разрабатывать дополнительный код для логической группировки событий из разных микропакетов в один пользовательский сеанс [2].
Технически это можно реализовать с помощью метода mapWithState(), который принимает пользовательские действие и текущий сеанс пользователя в качестве входных данных, обновляет их и выводит обновленную модель для последующих операций. Такой подход довольно удобен для установки тайм-аутов в приложениях, когда сеанс должен быть закрыт, если в течение некоторого времени не поступали новые данные. Например, пользователь закрыл сеанс без явного выхода из системы. Вместо того, чтобы вручную кодировать таймаут в updateStateByKey(), разработчик приложения Spark Streaming может установить его напрямую в mapWithState():
userActions.mapWithState(StateSpec.function(stateUpdateFunction).timeout(Minutes(10)))
В отличие от updateStateByKey(), произвольные данные могут быть отправлены далее по потоковому конвейеру от функции обновления состояния. Также можно получить доступ к snapshot-снимкам текущего состояния пользовательских сеансов – UserSessionSnapshots. Это поток DStream, в котором каждый RDD является моментальным снимком обновленных сеансов после обработки каждого пакета данных. Кроме того, mapWithState() работает в десятки раз быстрее updateStateByKey() [3].
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
13 мая, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Однако, это решение не подходит, если события прибывают с опозданием из-за проблем с подключением к сети. Spotify позволяет слушать музыку в автономном режиме, когда будут воспроизводиться песни, хранящиеся локально на вашем устройстве, например, в самолете. В этом случае события пользовательской сессии кэшируются локально на телефоне клиента и не будут отправлены в Apache Kafka без подключения к Интернет. Все ранее буферизованные события попадут в Kafka, как только пользователь вернется в онлайн, причем накопленные события включаются в тот же микропакет, что и новые события, которые генерируются в онлайн-режиме. Если логика обработки не отличает исходное время события, сгенерированного в автономном режиме от текущего времени, случившегося онлайн, будут получены некорректные результаты, т.к. старые и новые события считаются одинаковыми и группируются в один микропакет.
Аналогичная проблема может произойти, когда пользователь меняет устройства, например, во время перелета слушая музыку в автономном режиме на ноутбуке, чтобы сэкономить заряд телефонного аккумулятора. События сохраняются в локальной буфере и не могут быть отправлены в Kafka. Но по прилету пользователь выключает ноутбук и слушает музыку на мобильном телефоне в онлайн-режиме. События немедленно отправляются в Kafka. Однако, при включении ноутбука и наличии подключения к сети все ранее буферизованные события тоже отправляются в Kafka, меняя порядок, который был в реальности. Это также может привести к некорректным результатам для конкретного пользователя. Решить все эти проблемы пакетной обработки информации поможет переход к технологиям Big Data, которые поддерживают действительно потоковый режим, такие как Apache Kafka в сочетании с Flink. Как это реализуется на практике, мы рассмотрим далее.
Потоковая обработка в Apache Spark
Код курса
SPOT
Ближайшая дата курса
16 мая, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Потоковая аналитика Big Data с Apache Flink и Spark Structured Streaming
Заменив Spark Streaming на Apache Flink можно напрямую обращаться к событиям Kafka, обрабатывая их в их собственном представлении — в виде потока, а не пакетной абстракции. Таким образом, озер данных превращается в текущую реку.

Рассмотрим два сценария, в которых необходимо подсчитать:
- кейс А — как долго пользователь слушает музыку в одном сеансе;
- кейс В — сколько последовательных песен пользователь воспроизводит из определенного списка воспроизведения.
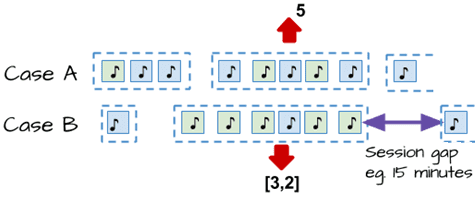
В этом случае потоковый конвейер будет выглядеть следующим образом [2]:
- для чтения событий из топика Kafka приложение Flink предоставляет потребителя, который с помощью внутреннего механизма контрольных точек дает возможность выполнять единовременную обработку. Нужно всего лишь указать простые параметры подключения (топик и адрес брокера Kafka):
sEnv.addSource(new FlinkKafkaConsumer09[Event](conf.topic(), getSerializationSchema, kafkaProperties(conf.kafkaBroker())) )
- далее создаются пользовательские сеансы – в качестве ключа группировки входящих событий используется userId и назначаются окнам сеанса. Здесь следует всего лишь указать промежуток между событиями, составляющими окно, например, 15 минут:
.keyBy(_.userId) .window(EventTimeSessionWindows.withGap(Time.minutes(15)))
- можно дополнить пример простой функцией вычисления, которая будет применяться для каждого окна пользовательского сеанса. В результате получается конвейер обработки, который обрабатывает неупорядоченные события, которые умещаются в несколько строк кода:
val sessionStream : DataStream[SessionStats] = sEnv .addSource(new FlinkKafkaConsumer09[Event](…)) .keyBy(_.userId) .window(EventTimeSessionWindows.withGap(Time.minutes(15))) .apply(new CountSessionStats())
Если требуется обрабатывать поздние события, которые поступают с максимальным опозданием в 1 час, т.е. 60 минут, этот параметр нужно установить конвейере. Apache Flink будет сохранять состояние всех окон в течение этого дополнительного периода, чтобы при появлении некоторых устаревших событий отреагировать на них, обновляя агрегаты: .allowedLateness(Time.minutes(60)).
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
27 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Сократить цикл обратной связи поможет триггер раннего срабатывания, который будет выдавать каждое окно каждые несколько минут с промежуточными результатами:
.trigger(EarlyTriggeringTrigger.every(Time.minutes(10))).
Разумеется, рассмотренный пример не отражает все аспекты потоковой обработки и возможности Apache Flink, однако показывает, почему современная аналитика больших данных все чаще основана на технологиях работы с данными в реальном времени. В заключение добавим, что вместо Apache Flink можно использовать Spark Structured Streaming – библиотеку потоковой передачи данных, которая развивает возможности Spark Streaming и больше приближена к real-time обработке, о чем мы подробно рассказывали здесь.

Научиться разрабатывать распределенные приложения потоковой аналитики больших данных с Apache Kafka и Spark вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для разработчиков
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
Источники

