
В этой статье для дата-инженеров рассмотрим кейс компании PayPal, которая переводит свои аналитические рабочие нагрузки из локального кластера Apache Spark в Google Cloud Processing. Читайте далее, чем это решение оказалось лучше выполнения Spark-заданий в кластере DataProc с использованием данных BigQuery и облачного хранилища Google (GCS, Google Cloud Storage) для потоковой аналитики больших данных.
Аналитика больших данных в PayPal с Apache Spark: предыстория
За аналитику больших данных в PayPal отвечают задания Apache Spark, который собирают поведенческие данные с веб-сайта и переупаковывают их в формат, пригодный для использования в Data Science-задачах. Например, пользователь посещает веб-сайт платежной системы PayPal, входит в свою учетную запись и переводит деньги другому пользователю. Оба они проверяют балансы своих счетов и выходят из системы. Это пользовательские действия происходят в течение сеанса, и для каждого из них запускается событие. Процесс создания сеансов объединяет все события из одного пользовательского сеанса и обеспечивает их сводное представление, включая время начала и окончания сеанса и количество случившихся событий.
Изначально все обработанные данные о пользовательском поведении доступны в распределенной файловой системе Hadoop (HDFS). События группируются почасово в зависимости от времени. Spark-задание считывает пакетные данные на стороне клиента и выполняет группировку на основе идентификатора пользователя и идентификатора сеанса.
В зависимости от времени окончания сеанса сгруппированные события разделяются на завершенные и текущие сеансы. Все завершенные сеансы записываются в окончательный результат, а текущие сеансы – во временное место. В начале каждого прогона выполняется объединение текущего набора данных и нового пакета поведенческих данных. SQL-СУБД используется для управления состоянием этого задания [1].
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
13 мая, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Сравнение вариантов обработки данных в BigQuery
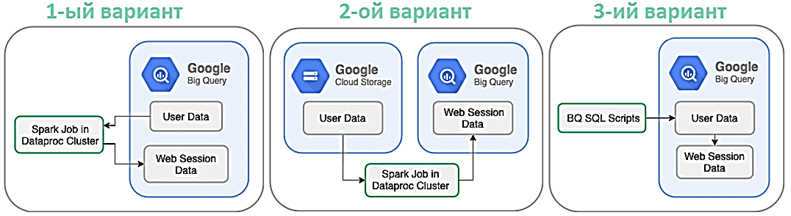
Первым вариантом является выполнение задания Dataproc на данных в BigQuery, где будут храниться все пользовательские данные. Напомним, BigQuery — это RESTful веб-сервис для интерактивного широкомасштабного анализа больших наборов данных, хранящихся в Google Storage.
BigQuery предоставляет внешний доступ к Dremel – масштабируемой, интерактивной специальной системе ad-hoc запросов для анализа данных, доступных только для чтения. Чтобы использовать данные в BigQuery сначала их необходимо загрузить в Google Storage, а затем импортировать с помощью BigQuery API HTTP с OAuth-подобной аутентификацией.
Все пользовательские данные можно перенести в кластер DataProc с помощью коннектора Spark-BigQuery. Dataproc – это тоже часть облака Google, управляемый и настраиваемый сервис Apache Spark и Hadoop, позволяющий использовать open-source инструменты стека Big Data для пакетной обработки, запросов, потоковой передачи и машинного обучения. Подробнее о том, что такое Dataproc и зачем он нужен, мы писали здесь и здесь.
Таким образом, Spark-задание, которое раньше выполнялось локально, можно перепрофилировать для запуска в кластере DataProc и записывать данные обратно в BigQuery с помощью той же библиотеки коннекторов.
Преимущество этого варианта в повторном использовании существующих Spark-заданий. Но здесь появляются дополнительные этапы ввода/вывода и затраты на перемещение данных из BigQuery для обработки. Также для каждого запуска кластера DataProc потребуется дополнительное время.
Поскольку BigQuery является сервисом для доступа к пользовательские данные, хранящимся в GCS, то для них можно запустить Spark-задание в кластере DataProc с помощью коннекторов DataProc Hadoop. Обработанные данные можно записать обратно в BigQuery. Этот вариант похож на предыдущий и имеет те же преимущества, но меньшие затраты – только на выполнение задания DataProc.
В 3-м варианте существующие задания Spark SQL необходимо переписать с использованием BigQuery SQL, чтобы использовать преимущества существующей инфраструктуры. При этом стоит помнить, когда за задания BigQuery выставляются счета по запросу, этот подход будет дороже, чем другие альтернативы [1].
С версии 2.0 BigQuery поддерживает стандартный диалект SQL, соответствующий соответствует стандарту ISO / IEC 9075:2011 и имеет расширения, которые поддерживают запросы вложенных и повторяющихся данных [2].
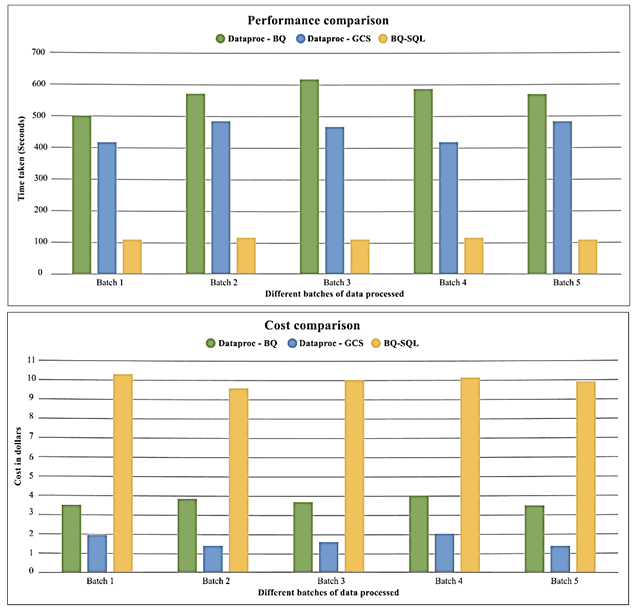
Чтобы оценить производительность и стоимость предложенных вариантов, они были протестированы на разных пакетах, каждый из которых содержит около 75 ГБ пользовательских данных, хранящихся в BigQuery или Google Cloud Storage. Тестирование показало, что выполнение SQL-задания BigQuery обеспечивает лучшую производительность, в среднем обрабатывая 1 пакет данных примерно за 2 минуты. Производительность DataProc в GCS выше, чем DataProc в BigQuery.
Стоимость DataProc- BigQuery состоит включает затраты на запуск задания DataProc и извлечение данных из BigQuery. Стоимость BigQuery SQL зависит от расценок облачного провайдера. При этом, если в BigQuery предусмотрены выделенные слоты, стоимость выполнения будет меньше. Задание DataProc с чтением GCS тоже является вполне жизнеспособным вариантом, если нет возможности делать большие инвестиции [1].
Таким образом, дата-инженеры PayPal выбрали 3-ий вариант, переписав существующие задания Spark SQL на BigQuery SQL, чтобы использовать преимущества существующей инфраструктуры Google. Помимо высокой стоимость, недостатком этого решения является тестируемость или контроль. В частности, BigQuery не позволяет писать какие-либо модульные тесты, в отличие от локального кластера Apache Spark, который предоставляет разработчикам и дата-инженерам полный контроль над ПО. Поэтому при создании конвейера потоковой обработки специалисты PayPal столкнулись с некоторыми причудами этого решения, о чем мы рассказывали здесь.
Больше примеров использования Apache Spark для разработки распределенных приложений и аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

