В этом материале рассмотрим реализацию массово-параллельной архитектуры для хранения и аналитической обработки больших данных на примере популярной Big Data СУБД Greenplum. Прочитав эту статью, вы поймете, почему MPP-базы потребляют много ресурсов и как связано число сегментов со скоростью работы кластера.
MPP, Greenplum и PostgreSQL
Напомним, СУБД Greenplum – это типичный представитель распределенной массивно-параллельной архитектуры (MPP, Massive Parallel Processing) на основе PostreSQL для управления крупномасштабными аналитическими хранилищами данных. Greenplum реализует концепцию «Shared Nothing», когда узлы кластера, которые взаимодействуют для выполнения вычислительных операций, не разделяют ресурсы: каждый из них имеет собственную память, операционную систему и жесткие диски. Благодаря этому MPP-базы эффективно распараллеливают нагрузку на выполнение аналитических запросов к многотерабайтным хранилищам данных.
Можно сказать, что кластер Greenplum представляет собой несколько экземпляров (инстансов, instance) объектно-реляционной базы данных PostreSQL, которые работают вместе как единая СУБД. Разумеется, чтобы поддерживать распределенную работу, в частности, распараллеливание SQL-запросов, исходный код PostgreSQL был модифицирован. К примеру, были изменены такие элементы, как системный каталог, оптимизатор, исполнитель запросов и компоненты диспетчера транзакций [1]. Связь между отдельными экземплярами PostgreSQL обеспечивается за счет соединения инстансов на сетевом уровне с помощью быстрых обособленных сетей (интерконнектов, interconnect) [2].
Greenplum для инженеров данных и аналитиков данных
Код курса
GPDE
Ближайшая дата курса
24 июня, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
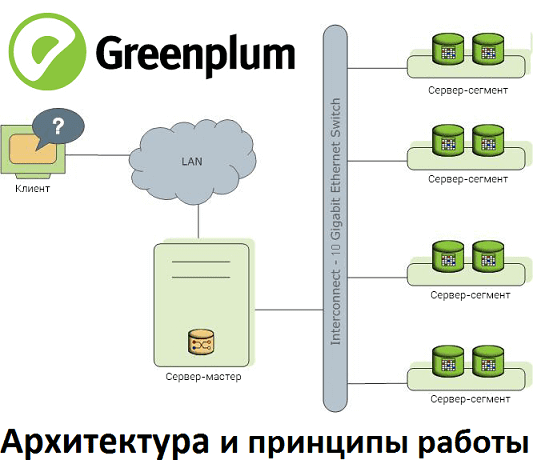
Архитектура Гринплам
Как и любая распределенная Big Data система, кластер Greenplum работает по определенным принципам взаимодействия узлов. Эта MPP-СУБД представляет модифицированную версию популярной архитектуры master-slave, где для повышения надежности добавлен резервный главный сервер. Таким образом, между компонентами кластер Greenplum существуют следующие отношения [1]:
- Мастер-сервер (Master host), где развернут главный инстанс PostgreSQL (Master instance). Он является точкой входа в Greenplum и представляет собой экземпляр базы данных, к которому подключаются клиенты, отправляя SQL-запросы. Мастер координирует свою работу с сегментами – другими экземплярами базы данных в этой Big Data системе.
- Резервный мастер (Secondary master instance) — инстанс PostgreSQL, который вручную включается в работу при отказе основного мастера.
- Сервер-сегмент (Segment host), который хранит и обрабатывает данные. Обычно 1 хост-сегмент содержит 2-8 сегментов Greenplum. Точное число экземпляров базы данных на хосте зависит от его характеристики (ЦП, память, жесткие диски), а также от сетевых интерфейсов и рабочих нагрузок. Сегменты Greenplum представляют собой инстансы PostgreSQL и делятся на основные (primary) и зеркальные (mirror). Каждая ячейка сегментов Greenplum – это независимая база данных PostgreSQL, где хранится часть данных. Primary-сегмент обрабатывает локальные данные, отдавая результаты мастеру. Каждому primary-сегменту соответствует свое зеркало (Mirror segment instance) — инстанс PostgreSQL, который автоматически включается в работу при отказе primary.
Конечные пользователи базы данных Greenplum взаимодействуют с ней через мастера, как с обычной СУБД PostgreSQL. Подробнее о том, как выполняется клиентское подключение, мы рассказываем здесь. Примечательно, что сам мастер не содержит никаких пользовательских данных, они хранятся только на сегментах. Реляционные таблицы и их индексы распределены по доступным сегментам кластера Greenplum. Каждый сегмент содержит свою часть данных и выполняет процессы, обслуживающие эти данные. Мастер распределяет рабочие нагрузки между сегментами с учетом глобального системного каталога – набора системных таблиц с метаданными о самой базе данных Greenplum. Взаимодействие мастера с сегментами, которое объясняет работу рассматриваемой MPP-СУБД, можно представить следующим образом [1]:
- пользователь подключается к к базе данных с помощью клиентских программ: psql или через API-интерфейсы типа JDBC и ODBC;
- мастер аутентифицирует клиентские соединения и обрабатывает входящие SQL-запросы;
- для обработки запроса в каждой базе данных сегмента создаются соответствующие процессы;
- после выполнения вычислений над локальными данными каждый сегмент возвращает результаты мастеру;
- мастер координирует результаты от сегментов и представляет конечный итог клиентской программе.
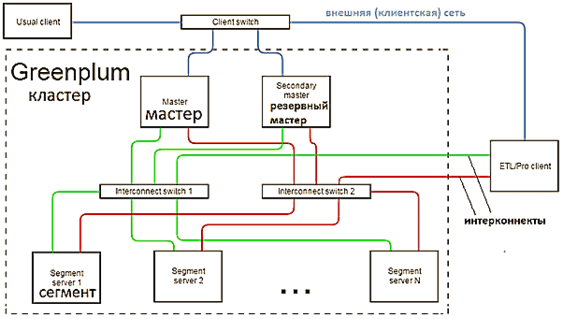
Секреты эффективности или особенности работы Greenplum
MPP-архитектура обусловливает следующую специфику работы Greenplum [2]:
- несколько разных interconnect-сетей повышает пропускную способность канала взаимодействия сегментов и обеспечивает отказоустойчивость кластера, т.к. при отказе одной из сетей весь трафик перераспределяется между оставшимися;
- повысить производительность кластера можно за счет идентичной настройки хост-сегментов. Это позволит равномерно распределить данные и рабочие нагрузки по большему числу сегментов с одинаковыми мощностями для распараллеливания задач и их одновременного выполнения.
- Быстрота работы узла зависит от соотношения числа процессорных ядер к числу данных, расположенных на этом хосте. Любой запрос на одном сегменте не может занимать более 1-го процессорного ядра.
- Greenplum работает со скоростью самого медленного сегмента, поэтому несбалансированное распределение данных (в одной таблице или во всей базе) по сегментам снижает общую производительность кластера.
Для равномерного распределения данных Greenplum стоит помнить про классическое шардирование в реляционной базе (горизонтальное партиционирование), когда логически независимые строки таблицы хранятся раздельно, сгруппированные в заранее определенные секции. Эти секции размещаются на разных, физически и логически независимых серверах, хотя один физический узел кластера может содержать несколько серверов баз данных. Наиболее популярным методом шардирования считается хэширование идентификационных данных клиента, что позволяет однозначно привязать его данные к отдельному и заранее известному инстансу («шарду»). Таким образом обеспечивается независимая от количества клиентов горизонтальная масштабируемость [3].
В Greenplum каждая таблица представлена в виде (N+1) таблиц на всех сегментах кластера, где N – число сегментов + 1 таблица на мастере, где нет пользовательских данных. На каждом сегменте хранится 1/N строк таблицы. Логика разбиения таблицы на сегменты задаётся ключом (полем) дистрибуции, на основе которого любую строку можно отнести к одному из сегментов. Поскольку именно ключ дистрибуции задает распределение данных по сегментам кластера, выбирать это поле нужно по принципу равномерного распределения значений в нем [2].
Примечательно, что в 6-ой версии рассматриваемой MPP-СУБД, которая вышла в конце 2019 года, появился новый инструмент оптимизации схемы хранения данных — реплицированные таблицы. Они полностью дублируются на всех сегментах кластера, поэтому их JOIN-соединение будет выполняться локально, без перераспределения данных. Это особенно важно для хранения объёмных справочников. Также в новой версии появился алгоритм consistent hashing, который позволяет при добавлении в кластер новых узлов перераспределять только часть блоков, ускоряя фоновое перераспределение таблиц [4]. Подробнее про особенности хранения данных в GP читайте в этом материале.
Администрирование Greenplum / Arenadata DB
Код курса
GRAD
Ближайшая дата курса
13 мая, 2024
Продолжительность
40 ак.часов
Стоимость обучения
120 000 руб.
В следующей статье мы рассмотрим особенности интеграции Гринплам с Apache Kafka. А как обеспечить эффективную работу Greenplum для хранения и аналитики больших данных, вы узнаете на примере администрирования MPP-СУБД Arenadata DB на авторизованных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

