
В последнее время в мире Big Data все меньше можно услышать новостей про Apache Hadoop. Сегодня рассмотрим, почему мифы о смерти Хадуп – это всего лишь мифы и как будет развиваться эта мощная экосистема хранения и обработки больших данных в будущем. Читайте в нашей статье про слияния и поглощения ведущих вендоров, тренд на облачные сервисы и Google Cloud Storage connector, а также попытки нивелировать ограничения HDFS с помощью Apache Ozone.
Apache Hadoop в 2020 году: развитие или забвение
При том, что сравнение Apache Hadoop и Spark не совсем корректно, т.к. последний входит в экосистему проектов первого, Спарк выигрывает по множеству показателей [1]:
- MapReduce работает быстрее за счет операций в памяти, а с жестким диском;
- микро-пакетный режим позволяет вести потоковую обработку данных практически в реальном времени;
- Spark SQL снижает порог входа в технологию, реализуя аналитику больших данных через стандартные ANSI SQL-запросы;
- наличие встроенной библиотеки машинного обучение (MLLib) включает специалистов по Data Science и Machine Learning в круг пользователей этого фреймворка.
Данные наблюдения подтверждает динамика поисковых запросов в соответствующем инструменте Google [2]: примерно с сентября 2016 года популярность Хадуп идет на спад, а Spark остается на достаточно высоком уровне, хотя тоже имеет тенденцию к снижению.
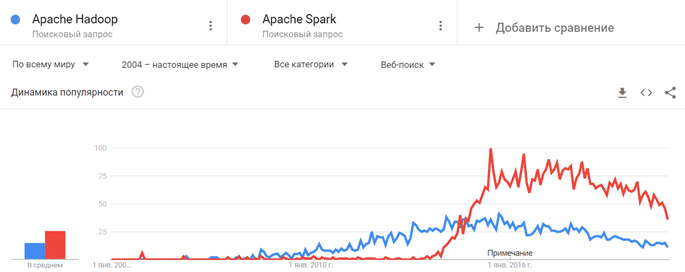
Однако, не все так однозначно. Говорить о смерти Хадуп и устаревании этой Big Data технологии [3] не стоит по следующим причинам [4]:
- большинство ключевых компонентов экосистемы постоянно обновляются – например, недавно мы рассказывали про Apache Spark 3.0, вышедший летом 2020 года. Примерно тогда же вышел новый релиз Apache Hadoop 3.3.0, поддерживающий ARM-архитектуру, Java 11, систему каталога YARN-приложений, файловую систему Tencent Cloud COS для доступа к объектному хранилищу COS и планирование запуска контейнеров по расписанию. Еще анонсировано облегчение работы с DNS и IP, а также стабилизация HDFS RBF (Router-based Federation), куда добавлены средства управления безопасностью [5];
- основные компоненты платформы Хадуп достигли такого уровня зрелости и стабильности, что ажиотаж вокруг них закономерно снижается – эта Big Data технология становится повседневным надежным инструментом, который незаметно работает на заднем плане и не привлекает особого внимания;
- повсеместный переход от локальной ИТ-инфраструктуры к облачным сервисам приводит к появлению новых соответствующих продуктов, таких как, например, Apache Ozone и Google Cloud Storage connector, о которых мы поговорим далее.
Слияния, поглощения и облака
Если еще несколько лет назад можно было наблюдать конкуренцию между несколькими вендорами или дистрибьютерами Хадуп: Hortonworks, MapR, Cloudera, то сегодня рынок этой Big Data платформы не отличается большим разнообразием. В частности, в 2018 году Cloudera и Hortonworks объявили о слиянии, а годом позже корпорация Hewlett-Packard Enterprise купила MapR Technologies [6]. Тем временем, Cloud-гиганты, такие как Microsoft Azure, Amazon и Google запускают облачные сервисы по хранению и обработке больших данных в т.ч. на базе хадуп-кластеров, предоставляемых по модели «on-demand», о чем мы писали здесь.
Таким образом, из локальных дистрибуций Хадуп enterprise-класса сегодня наиболее известными можно назвать продукт от Cloudera, а на российском рынке – от Arenadata. При этом востребованность локальных решений снижается, уступая месту тренду на сервисный подход. Актуальность этой тенденции подтверждает не только предложение Hadoop-as-a-Service практически у каждого облачного провайдера, но и выпуск следующих продуктов:
- коннектор Google Cloud Storage– клиентская Java-библиотека с открытым исходным кодом, которая позволяет заменить HDFS на облачное хранилище Google. Она реализует Хадуп-совместимую файловую систему (Hadoop Compatible FileSystem, HCFS) и работает внутри JVM, что позволяет процессам обработки больших данных, таким как задания Hadoop или Spark, получать прямой доступ к информации из Google Cloud Storage [7]; Подробнее о Google Cloud Storage Connector for Hadoop мы рассказываем здесь.
- Apache Ozone – масштабируемое распределенное хранилище объектов для Хадуп, которое может эффективно работать в контейнерных средах, таких как Kubernetes и YARN, и основано на высокодоступном реплицированном уровне блочного хранилища Hadoop Distributed Data Store (HDDS). Примечательно, что приложения Apache Spark, YARN и Hive, отлично совместимы с Ozone и не требуют внесения каких-либо изменений [8].
Завтра мы продолжим разговор про Apache Ozone и рассмотрим, чем это хранилище отличается от HDFS, а также какие преимущества оно предоставляет своим пользователям. Главные обновления свежего релиза Хадуп-2021 мы разбираем в этой статье. А освоить практику администрирования и эффективной эксплуатации экосистемы Apache Hadoop для хранения и аналитики больших данных в проектах цифровизации частного бизнеса, а также государственных и муниципальных предприятий, вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Hadoop
- Администрирование кластера Hadoop
- Безопасность озера данных Hadoop
- Hadoop для инженеров данных
- Основы Arenadata Hadoop
- Администрирование кластера Arenadata Hadoop
- Анализ данных с Apache Spark
Источники
- https://www.iflexion.com/blog/spark-vs-hadoop-mapreduce
- https://trends.google.ru/trends/explore?date=all&q=Apache%20Hadoop,Apache%20Spark
- https://blogs.gartner.com/merv-adrian/2020/03/04/its-time-to-stop-talking-about-the-hadoop-market/
- https://blogs.gartner.com/merv-adrian/2020/08/19/august-2020-hadoop-distribution-apache-project-tracker/
- https://blogs.apache.org/hadoop/entry/announce-apache-hadoop-3-3
- https://www.livebusiness.ru/tags/big_data_platformy/
- https://www.infoq.com/news/2019/09/Google-Cloud-Storage-Hadoop/
- https://hadoop.apache.org/ozone/

