
Сегодня поговорим про особенности перехода с локального Hadoop-кластера в облачное SaaS-решение от Google – платформу Dataproc. Читайте далее, какие 5 шагов нужно сделать, чтобы быстро развернуть и эффективно использовать облачную инфраструктуру для запуска заданий Apache Hadoop и Spark в системах хранения и обработки больших данных (Big Data).
Шаги переноса Data pipeline‘ов c локальной экосистемы Hadoop в облако
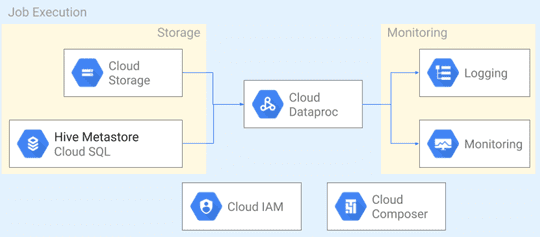
Напомним, Dataproc – это часть Google Cloud Platform, управляемый и настраиваемый облачный сервис Apache Spark и Hadoop, позволяющий использовать open-source инструменты стека Big Data для пакетной обработки, запросов, потоковой передачи и машинного обучения [1]. Вчера мы рассматривали его архитектуру, компонентный состав и принципы работы, а также средства обеспечения информационной безопасность. Сегодня активный переход в облака является одной из наиболее устойчивых тенденций в ИТ-сфере, включая развитие экосистемы Apache Hadoop. Поэтому дата-инженеру и администратору Big Data актуально знать, как обеспечить миграцию больших данных и конвейеров их обработки (data pipeline) в облако безболезненно для предприятия. Схематично весь процесс перехода можно разделить на 5 последовательных этапов, каждый из которых мы подробнее рассмотрим далее [2]:
- создание и настройка кластера;
- задание хранилища данных;
- создание и настройка data pipeline’ов;
- мониторинг производительности и обеспечение безопасности;
- оптимизация.
Hadoop для инженеров данных
Код курса
HDDE
Ближайшая дата курса
17 июня, 2024
Продолжительность
40 ак.часов
Стоимость обучения
120 000 руб.
Создание облачного кластера Hadoop в Dataproc
Облачный кластер может использовать одну из версий образа, предоставленных Dataproc, или пользовательский вариант на основе одной из предоставленных версий. Версия образа – это стабильный и поддерживаемый пакет операционной системы, компонентов стека Big Data и коннекторов Google Cloud, таких как Google Cloud Storage Connector for Hadoop, о котором мы писали здесь. Можно использовать последнюю версию образа по умолчанию или выбрать вариант, соответствующий существующей платформе, включая дополнительные поддерживаемые компоненты, например, Druid и Presto. А если нужны компоненты, которые еще не доступны, например, Apache Livy, следует инициализировать их, запустив исполняемый файл или скрипт на каждом узле кластера сразу после его установки.
В Dataproc очень просто создать типовой Hadoop-кластер с одним главным узлом или кластер высокой доступности с тремя главными узлами. Для этого следует в оболочке Cloud Shell выполнить следующую команду [2]:
# create a cluster in us-central1 gcloud dataproc clusters create my-first-cluster \ --region=us-central1
Определение хранилища данных
После создания кластера и добавления в него нужных дополнительных компонент, следует перенести сами данные в Google Cloud. Для этого можно присоединить HDFS, подключив постоянные диски (PD) к узлам Dataproc-кластера. Это тоже один из продуктов Google, представляющий собой надежное высокопроизводительное блочное хранилище для экземпляров виртуальных машин [3]. Другой популярной альтернативой является использование Google Cloud Storage в качестве хранилища. Чтобы переключиться с HDFS на облачное хранилище, следует изменить префикс пути к файлу с hdfs:// на gs://. Можно также использовать реляционные хранилища, такие как Delta Lake на базе Apache Spark и Iceberg, для поддержки схемы, транзакций ACID и управления версиями данных. Напомним, Apache Iceberg – это открытый формат таблиц для огромных наборов аналитических данных, который добавляет в Presto и Spark SQL-подобные таблицы [4]. Примечательно, что независимо от выбора хранилища самих данных, для кластеров Dataproc следует использовать центральное хранилище метаданных Apache Hive c MySQL в CloudSQL в качестве базы данных. Чтобы упростить переход на BigQuery, бессерверное хранилище данных петабайтного масштаба, Dataproc предоставляет специальные коннекторы: BigQuery connector и BigQuery Spark connector [2].
Запуск аналитических конвейеров
Dataproc упрощает отправку заданий в кластер с помощью метода jobs.submit в API без необходимости настраивать экземпляры периметра. Он использует центральный уровень управления идентификацией и доступом для проверки подлинности и авторизации запросов, позволяя выполнять задания на частных кластерах максимально безопасно. Для более сложных конвейеров обработки данных из несколько взаимозависимых заданий в виде разветвленного DAG-графа, можно использовать workflow-шаблоны Dataproc или прибегнуть к помощи Apache Airflow от Google Cloud через Dataproc API с Cloud Composer [2].
Data Pipeline на Apache Airflow
Код курса
AIRF
Ближайшая дата курса
22 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Мониторинг и безопасность
Центральный уровень управления идентификацией и доступом обеспечивает простой доступ к выходным данным задания или контрольному журналу с помощью Cloud Logging. Чтобы управлять ресурсами и приложениями кластера и контролировать их через безопасный доступ к веб-интерфейсу Hadoop, следует включить Dataproc Component Gateway. Облачный мониторинг или облачное профилирование подходят для расширенных вариантов использования, таких как мониторинг работоспособности и производительности, создание аналитических отчетов или панелей мониторинга.
Чтобы обеспечить безопасность и изоляцию, каждый кластер рекомендуется запускать с отдельной учетной записью службы с доступом только к тем ресурсам, которые требуются для выполнения задания. Такая учетная запись службы также полезна при мониторинге, аудите и отладке. Поскольку между рабочими процессами нет взаимозависимости, пользователь Dataproc может тестировать и развертывать различные версии компонентов Hadoop и своего сервиса. А режим работы кластера по требованию (on demand) позволяет сократить расходы с помощью механизма вытесняемых экземпляров (инстансов) для выполнения задач. Однако, это не подойдет в случае работы с HDFS, поскольку такие инстансы могут быть отключены в любой момент [2].
Оптимизация
Наконец, когда данные и конвейеры их обработки перенесены в облако, имеет смысл задуматься об их оптимизации, чтобы снизить операционные накладные расходы и затраты. В частности, использование облачного хранилища данных и Apache Hive в качестве внешнего хранилища метаданных, позволяет отделить хранение от вычислений. Это позволяет сосредоточиться на процессах обработки больших данных, а не на особенностях эксплуатации кластера. В частности, можно создавать эфемерные кластеры по требованию, которые удаляются по завершении работы конвейера данных. Кроме того, по мере роста рабочих нагрузок часто возникает проблема накладных расходов, о чем мы недавно рассказывали на примере конвейеров из заданий Spark, запускаемых с помощью Apache AirFlow. В этом случае Dataproc обеспечивает ручное и автоматическое масштабирование, которое использует метрики YARN для управления количеством узлов [2].
О других проблемах перехода от локального Hadoop-кластера к облачному объектному хранилищу с применением Spark-приложений читайте здесь. А про пример построения конвейера аналитики больших данных на Kafka, Spark и Google BigQuery читайте в нашей новой статье.
Разобраться в тонкостях администрирования и эксплуатации экосистемы Apache Hadoop для хранения и обработки больших данных, вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Hadoop для инженеров данных
- Построение конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
1. https://cloud.google.com/dataproc/docs/concepts/overview
2. https://medium.com/google-cloud/migrating-hadoop-to-dataproc-43e8da80ba98
3. https://cloud.google.com/persistent-disk/
4. https://iceberg.apache.org/

