
В этой статье мы поговорим про ключевые достоинства и недостатки Apache HBase, а также рассмотрим наиболее интересные примеры практического использования этой нереляционной распределенной СУБД в крупных Big Data проектах.
Достоинства и недостатки одной из самых популярных NoSQL СУБД для Big Data
Прежде всего, отметим, что Apache HBase и Cassandra считаются наиболее популярными нереляционными базами данных в мире Big Data [1]. Оба этих продукта основаны на концепциях Google Big Table и являются колоночно-ориентированными хранилищами, где информация хранится хранятся в ячейках, сгруппированных в колонки, а не в строки данных [2]. Однако, сравнению этих СУБД посвящена наша отдельная статья, а сегодня мы расскажем о наиболее существенные достоинствах Apache HBase, важных с точки зрения ее прикладного использования [3]:
- специфическая модель данных, не ограничивающая число столбцов, которые можно сгруппировать в группы или семейства (column families) – информация хранится по столбцам, при не нужно хранить пустые значения (равные нулю), поэтому HBase хорошо подходит для разреженных наборов данных;
- прослеживаемая аналогия с реляционными СУБД в плане индекса первичного ключа – в HBase данные в таблицах упорядочены по строковым ключам при динамическом секционировании (partitioning) диапазона строк;
- встроенный механизм временных меток (timestamp), которые добавляются автоматически, но могут быть изменены вручную [1];
- наличие инструментов расширяемости (REST и другие API-интерфейсы Java и шлюзов) и внешних SQL-решений (Apache Phoenix, Drill, Hive и Cloudera Impala), позволяющих работать с данными, хранящимися в HBase, как с реляционными таблицами.
- высокая производительность и быстрота работы, в т.ч. в режиме реального времени, за счет кэширования в памяти и обработки данных на стороне сервера через фильтры и сопроцессоры. Например, тест на таблице из 3-х миллиардов строк при 300 параллельных запросов в секунду показал, что чтение будет занимать примерно 18 миллисекунд, запись выполнится почти в 3 раза быстрее и займет примерно 8 миллисекунд.
- высокая доступность и отказоустойчивость, обеспечиваемые с помощью репликации через центр обработки данных, неделимые и согласованные операции на уровне строк, а также автоматическое распределение нагрузки и балансировку таблиц за счет механизма регионирования. В качестве отказоустойчивого хранилища данных используются распределенная файловая система Hadoop (HDFS) и Amazon S3.
- способность к масштабированию – Apache HBase рассчитана на поддержание высокой производительности даже при увеличении кластера до сотен узлов для работы с миллиардами строк и миллионами столбцов.
Администрирование кластера HBase
Код курса
HBASE
Ближайшая дата курса
26 августа, 2024
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
При всех вышеперечисленных достоинствах, рассматриваемой нереляционной СУБД класса «семейство столбцов» свойственны следующие недостатки [3]:
- некоторые, особенно сложные запросы (примерно 1% от общего количества) могут выполняться медленнее (порядка 300 миллисекунд);
- индексация возможна только по одному полю (Row Key). Впрочем, Apache Phoenix позволяет ввести вторичный индекс – об этом мы рассказывали здесь и здесь.
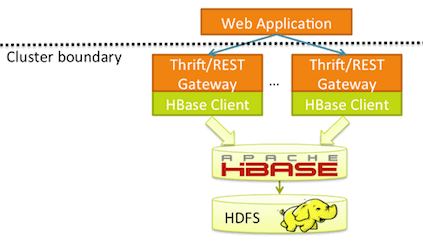
Где используется HBase: практические примеры и реальные кейсы
Вышеотмеченные достоинства и недостатки рассматриваемой СУБД обусловливают специфику ее прикладного использования. Благодаря тому, что рассматриваемая NoSQL-система обеспечивает сверхбыстрый доступ к огромному быстро изменяющемуся хранилищу данных, на практике ее активно применяют для аналитики Big Data в реальном времени и работы с табличными данными пользовательских приложений.
Например, корпорация Adobe, широко известный разработчик графических программ, пользуется HBase с октября 2008 для хранения и обработки своих внутренних данных. А Celer Technologies, глобальная ИТ-корпорация, разрабатывающая финансовые системы использует Hadoop/HBase для хранения всех финансовых данных по торговле, рискам и клирингу в одном хранилище данных. Благодаря этому клиенты организации могут создавать новые функции для быстрого извлечения данных на основе их торговых операций, рисков и операций клиринга из одного места [4].
Интересен также опыт американской компании Streamy, которая применяет рассматриваемую СУБД в рамках своей соцсети новостных сайтов в реальном времени, заменив прежнюю реляционную СУБД. HBase обеспечивает хранение сотни миллионов документов, разреженных матриц, журналов и всего остального, что когда-то было сделано в SQL-системе. Благодаря кэшированию в памяти результатов запроса обеспечивается высокое быстродействие, а глубокая интеграция с экосистемой Hadoop обеспечивает надежное выполнение тысячи ежедневных заданий MapReduce, используя таблицы для анализа журналов, обработки данных о внимании и сканирования каналов [4].
Facebook хранит в этой СУБД все потоковые данные, сгенерированные из различных сервисов (чаты, электронная почта, смс и пр.). Ключевыми качествами для этого примера использования являются отказоустойчивость и возможность быстрого извлечения данных с использованием техники произвольного доступа, что обеспечивает высокую производительность [5]. Аналогичные положительные результаты использования Apache HBase отмечают Yahoo, Twitter, NGDATA и множество других компаний по всему миру [4].
Интеграция Hadoop и NoSQL
Код курса
NOSQL
Ближайшая дата курса
5 августа, 2024
Продолжительность
40 ак.часов
Стоимость обучения
120 000 руб.
Станьте профессионалом по настройке и эксплуатации нереляционных СУБД в Big Data, пройдя обучения на наших практических курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Источники
- https://www.intellectsoft.net/blog/hbase-vs-cassandra/
- https://www.3pillarglobal.com/insights/exploring-the-different-types-of-nosql-databases
- https://ru.bmstu.wiki/Apache_HBase
- https://hbase.apache.org/poweredbyhbase.html
- https://beyondcorner.com/learn-apache-hbase/facebook-messenger-case-study-with-apache-hbase/

